这次的爬虫相对于上一版来说,增加了对小说内容的爬取,并且利用了Redis数据库。
环境: win10 py3.6 pycharm scrapy1.6
from scrapy import cmdline
cmdline.execute('scrapy crawl dmoz'.split())
# -*- coding: utf-8 -*-
# 系统自动生成的配置
BOT_NAME = 'Spider'
SPIDER_MODULES = ['Spider.spiders']
NEWSPIDER_MODULE = 'Spider.spiders'
# redis数据库的一些基本配置(这里的redis没有配置任何密码,在本地使用)
# 这些内容为自己添加的内容 不用redis数据库时不需要配置
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
SCHEDULER_PERSIST = True
SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.SpiderPriorityQueue'
REDIS_URL = None
REDIS_HOST = '127.0.0.1'
REDIS_POST = 6379
# scrapy爬虫中使用的请求头
USER_AGENT = 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50'
# 是否遵守robots协议
ROBOTSTXT_OBEY = False
# 连接Mongode数据库的配置
# 以下的内容为自己添加的内容,不需要使用Mongode数据库的时候,不需要写
MONGODE_HOST = '127.0.0.1'
MONGODE_PORT = 27017
MONGODE_DBNAME = 'Test'
MONGODE_DOCNAME = 'Book3'
# 配置最大并发请求的数目
#CONCURRENT_REQUESTS = 32
# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
# 下载器在下载同一网站下一个页面需要等待的时间,该选项可用来限制爬虫的爬取速度
#DOWNLOAD_DELAY = 3
# 对单个网站并发请求的最大值
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
# 对单个IP进行并发请求的最大值。
#CONCURRENT_REQUESTS_PER_IP = 16
# 需要使用Cookies的时候开启 不适用的时候,禁用可以提高爬取速度
COOKIES_ENABLED = False
# 内建的telnet控制台
#TELNETCONSOLE_ENABLED = False
# Scrapy HTTP Request使用的默认header。由 DefaultHeadersMiddleware 产生。
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# 是否启用scrapy的中间件
#SPIDER_MIDDLEWARES = {
# 'Spider.middlewares.SpiderSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# 保存项目中启用的下载中间件及其顺序的字典
#DOWNLOADER_MIDDLEWARES = {
# 'Spider.middlewares.SpiderDownloaderMiddleware': 543,
#}
# Enable or disable extensions
# 是否需要拓展
# See https://doc.scrapy.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# 保存项目,启用pipelines及其顺序的地点
ITEM_PIPELINES = {
'Spider.pipelines.SpiderPipeline': 300,
}
#启用和配置AutoThrottle扩展(默认情况下禁用)
# See https://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# 初始下载延迟
#AUTOTHROTTLE_START_DELAY = 5
# 在高延迟的情况下设置的最大下载延迟
#AUTOTHROTTLE_MAX_DELAY = 60
# 请求的平均数量并行发送到每个远程服务器上
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# 启用显示所收到的每个响应的调节统计信息
#AUTOTHROTTLE_DEBUG = False
# 是否启用和配置HTTP缓存 (默认不启用)
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
from Spider.items import SpiderItem
from scrapy.conf import settings # 配置项的使用
import pymongo # 导入python控制数据库mongode的包
class SpiderPipeline(object):
def __init__(self):
# 类的初始化 这里连接的mongode数据库是没有上任何密码的
host = settings['MONGODE_HOST']
port = settings['MONGODE_PORT']
dbName = settings['MONGODE_DBNAME']
client = pymongo.MongoClient(host=host, port=port)
tdb = client[dbName]
self.post = tdb[settings['MONGODE_DOCNAME']]
# 将返回的类似字典类型的items插入到数据库中
def process_item(self, item, spider):
bookInfo = dict(item)
self.post.insert(bookInfo)
return item
# -*- coding: utf-8 -*-
import scrapy
class SpiderItem(scrapy.Item):
# 书名
bookName = scrapy.Field()
# 书标题
bookTitle = scrapy.Field()
# 章节数
chapterNum = scrapy.Field()
# 章节的名字
chapterName = scrapy.Field()
# 章节url
chapterURL = scrapy.Field()
# 小说正文
text = scrapy.Field()
Noverspider.py(核心代码)
from scrapy_redis.spiders import RedisSpider
from scrapy.selector import Selector
from Spider.items import SpiderItem
from scrapy.http import Request
class Noverspider(RedisSpider):
name = 'dmoz'
redis_key = 'Noverspider:start_urls'
# 需要爬取的url列表
start_urls = ['http://www.daomubiji.com/']
def parse_son(self, response):
# 类的初始化 这里下载的是除书内容外的所有内容
item = SpiderItem()
# 选择器的初始化
selector = Selector(response)
# 获取书的名字
bookName = selector.xpath('//div[@class="container"]/h1/text()').extract()
# 先抓大后抓小 这里是抓的章节的大
Chapter = selector.xpath('//div[@class="excerpts"]')
content = Chapter.xpath('.//article/a/text()').extract()
# 用每一个url作为下一个for循环的条件
url = Chapter.xpath('.//article/a/@href').extract()
# 循环提取盗墓笔记中需要的内容
for i in range(len(url)):
# 这里的try except是由于部分书籍的规则不尽相同,这里是添加了异常判断
try:
item['bookName'] = bookName[0].split(':')[0]
item['bookTitle'] = bookName[0].split(':')[1]
except Exception as e:
item['bookName'] = bookName[0]
# url的获取
item['chapterURL'] = url[i]
try:
item['chapterNum'] = content[i].split(' ')[1]
item['chapterName'] = content[i].split(' ')[2]
except Exception as e:
item['chapterNum'] = content[i].split(' ')[1]
# yield可以理解为只要扔出请求它就会有专门的下载器进行下载 参数如下 第一个url信息 第二个回调函数将要执行的地址
# self.parseContent()表示的是函数的执行 self.parseContent表示的是函数的地址
yield Request(url[i], callback=self.parseContent, meta={'item':item})
def parseContent(self, response):
# 类的初始化
item = response.meta['item']
selector = Selector(response)
text = selector.xpath('//article[@class="article-content"]/p/text()').extract()
text_new = ((''.join(text).replace('\u3000',''))).strip()
item['text'] = text_new
yield item
# 程序入口
def parse(self, response):
selector = Selector(response)
# 获取每一本书得链接地址,让程序通过主网页就可以爬取到他的子网页
urls = selector.xpath('//article/p/a/@href').extract()
for each in urls:
yield Request(each, callback=self.parse_son)
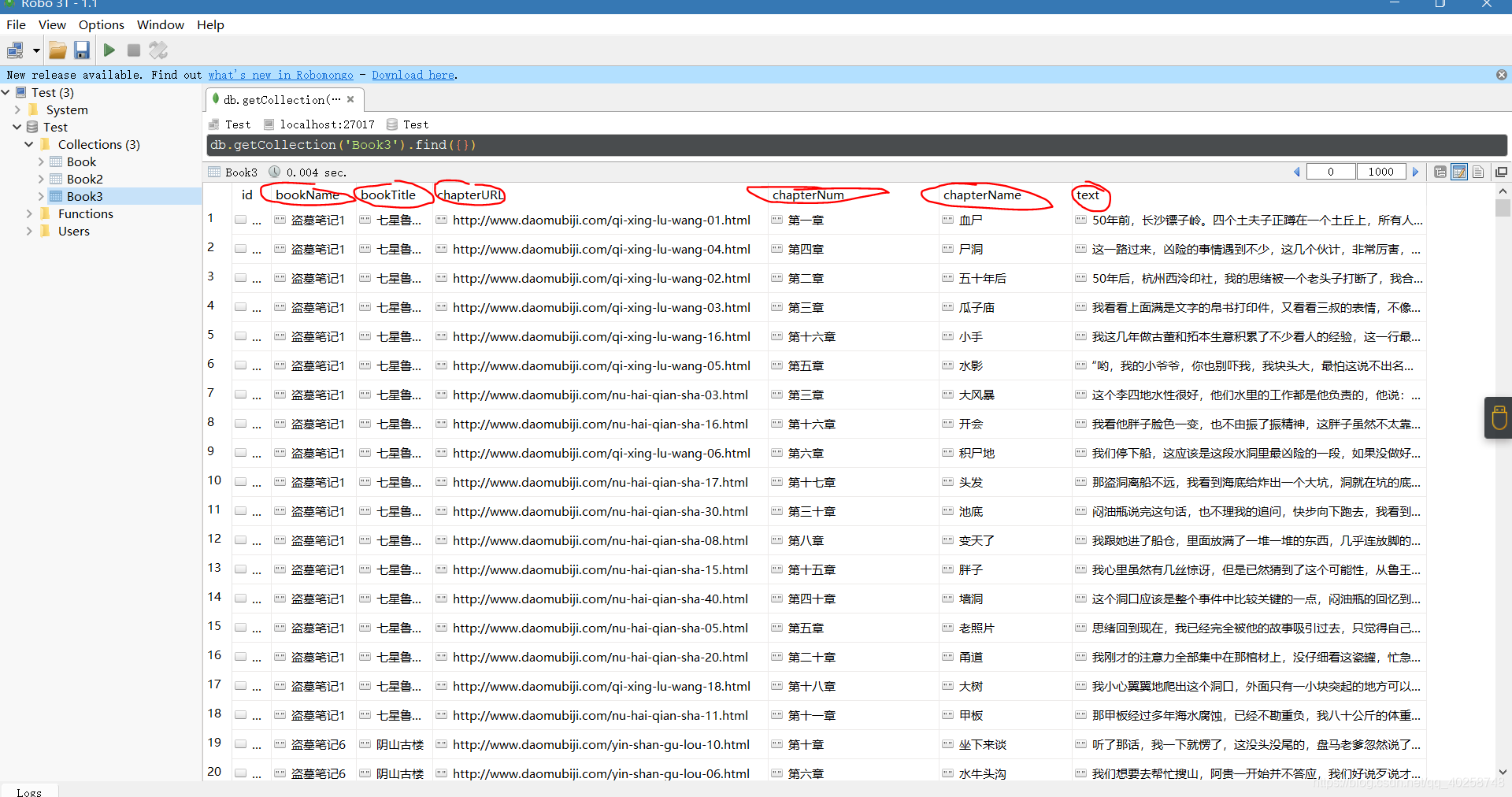
成果展示:
参考博客: https://www.jianshu.com/p/219ccf8e4efb
