2-3-4树(转红黑树),B-树,B+树分析
参考资料
漫画讲解B树
https://blog.csdn.net/zwz2011303359/article/details/63262541
前言
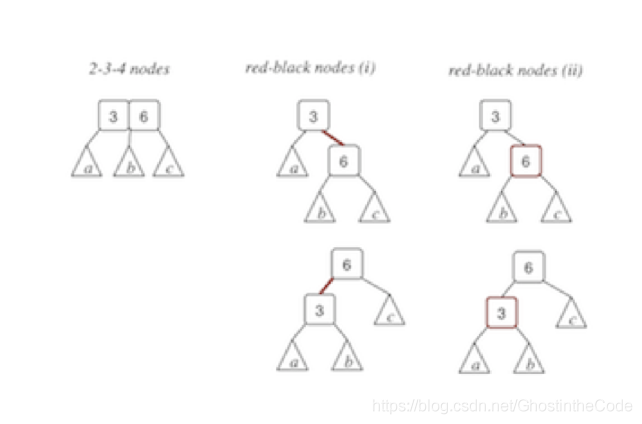
首先大家一定要知道没有B减树,那是B-树中间的是连字符。不要读错哦
其次就是2-3-4树是4阶的B-树。
再其次就是2-3-4树可以向红黑树转换。
举个例子:


带着问题学习
通过上面的分析,我们需要了解B-树和B+树就可以啦。带着问题学习是最高效的。
问题:
Mysql里面的索引基于什么样的数据结构?
答案:
主要基于hash表或者B+树
问题:
数据库索引为什么没有使用二叉查找树来实现?
答案:
二叉查找树的查找速度和比较次数都是最小的,但是我们需要考虑一个现实问题,磁盘IO。数据库索引是存储在磁盘上的,当数据量比较大的时候,索引的大小可能有好几个G甚至更多,当我们利用索引查询的时候,能把整个索引全部加载到内存么?显然是不可能的。能做的只有逐一加载每一个磁盘页,这里的磁盘页对于着索引树的节点。

B-树
如果利用二叉树作为索引结构,情形是什么样呢?假设树的高度是4,磁盘IO次数等于索引树的高度。就因为这样,为零减少磁盘IO次数,我们就需要把原本瘦高的树结构,变的矮胖一点。这就是B-树的特征之一。
B-树在查询中的比较次数其实不比二叉查找树少,尤其当单一节点中的元素数量很多时。可是相比磁盘IO的速度,聂村中的比较耗时几乎可以忽略。所以只要树的高度足够低,IO次数足够少,就可以提升查找性能。相比之下节点内部元素多一些也没有关系,仅仅是多了几次内存交互,只要不超过磁盘页的大小即可。这就是B-树的优势之一
B-树主要应用于文案系统以及部分数据库索引,比如中美的菲关系数据库MongoDB。而大部分关系型数据库,比如Mysql则使用B+树作为索引。
以上是我自己整理的笔记,如果觉得有点糊涂,可以看文章开头的链接,漫画更加让人印象深刻。相信你读完了心中就会有点B树啦,哈哈哈
B+树

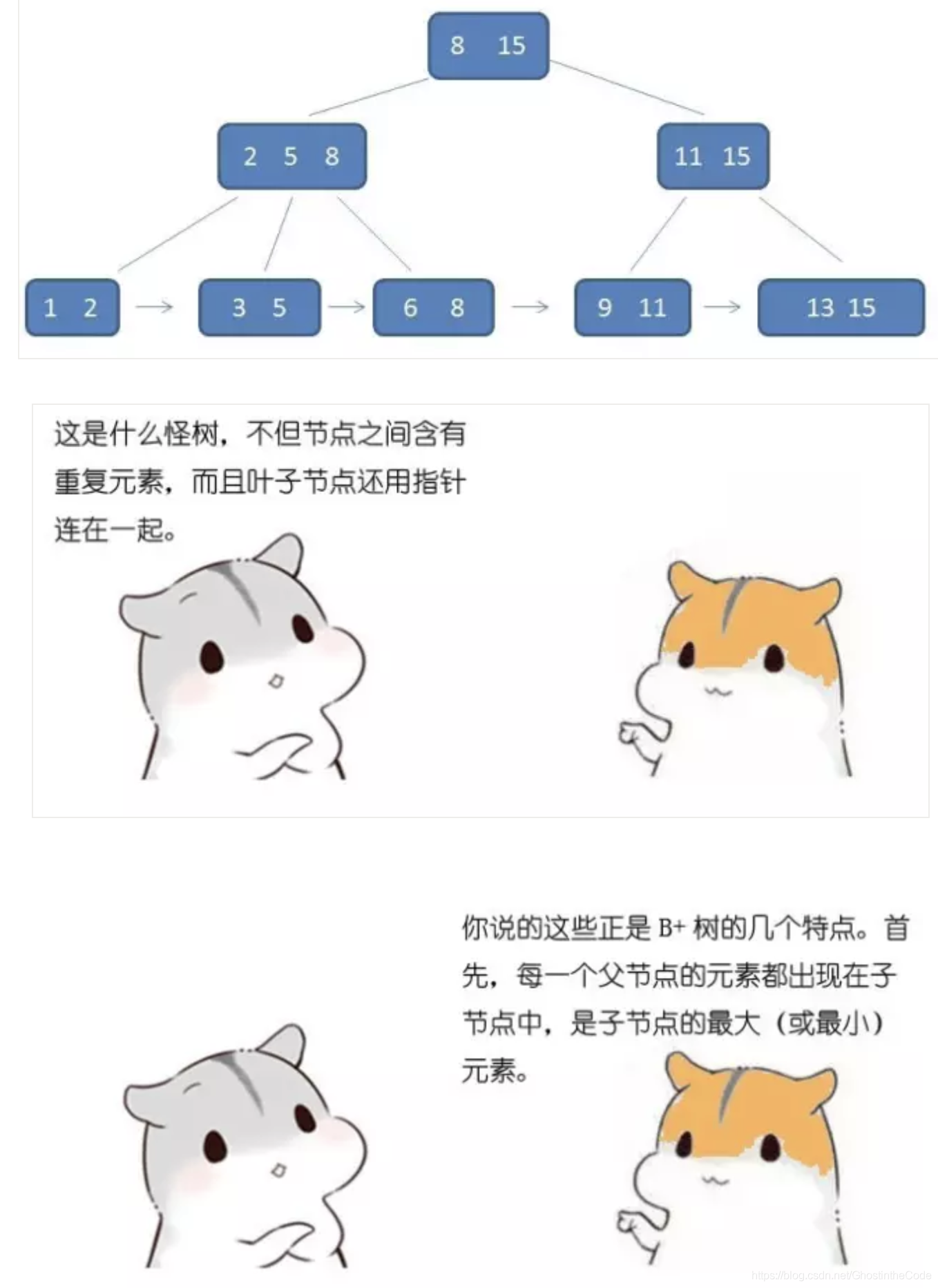
特点:
- 每一个父节点的元素都出现在子节点中,是子节点的最大(或最小)元素。
- 根结点的最大元素(这里是15)也就等同于整个B+树的最大元素。以后无论插入删除多少元素,始终要保持最大元素在根结点当中。
- 至于叶子节点,由于父节点的元素都出现在子节点,因此所有叶子节点包含了全量元素信息。并且每个叶子节点都有指向下一个节点的指针,形成量一个有序链表。

- 在索引之外,确是至关重要的特点。那就是卫星数据的位置。所谓卫星数据,值得是索引元素所指向的数据记录,比如数据库中的某一行,在B-树中,无论中间节点还是椰子节点都带有卫星数据。(卫星数据指的是一条纪录中除了关键字key以外的其他数据。因为一个纪录可能包含多个数据项,但是一般排序之类的算法只关心key,其他的项都是跟着key走,就像是卫星一样?!这些数据就称作卫星数据。)


B+树的好处主要体现在查询性能上:
- 单行查询:在单元素查询的时候,B+树会自顶向下逐层查找节点,最终找到匹配的叶子节点。如查找3。
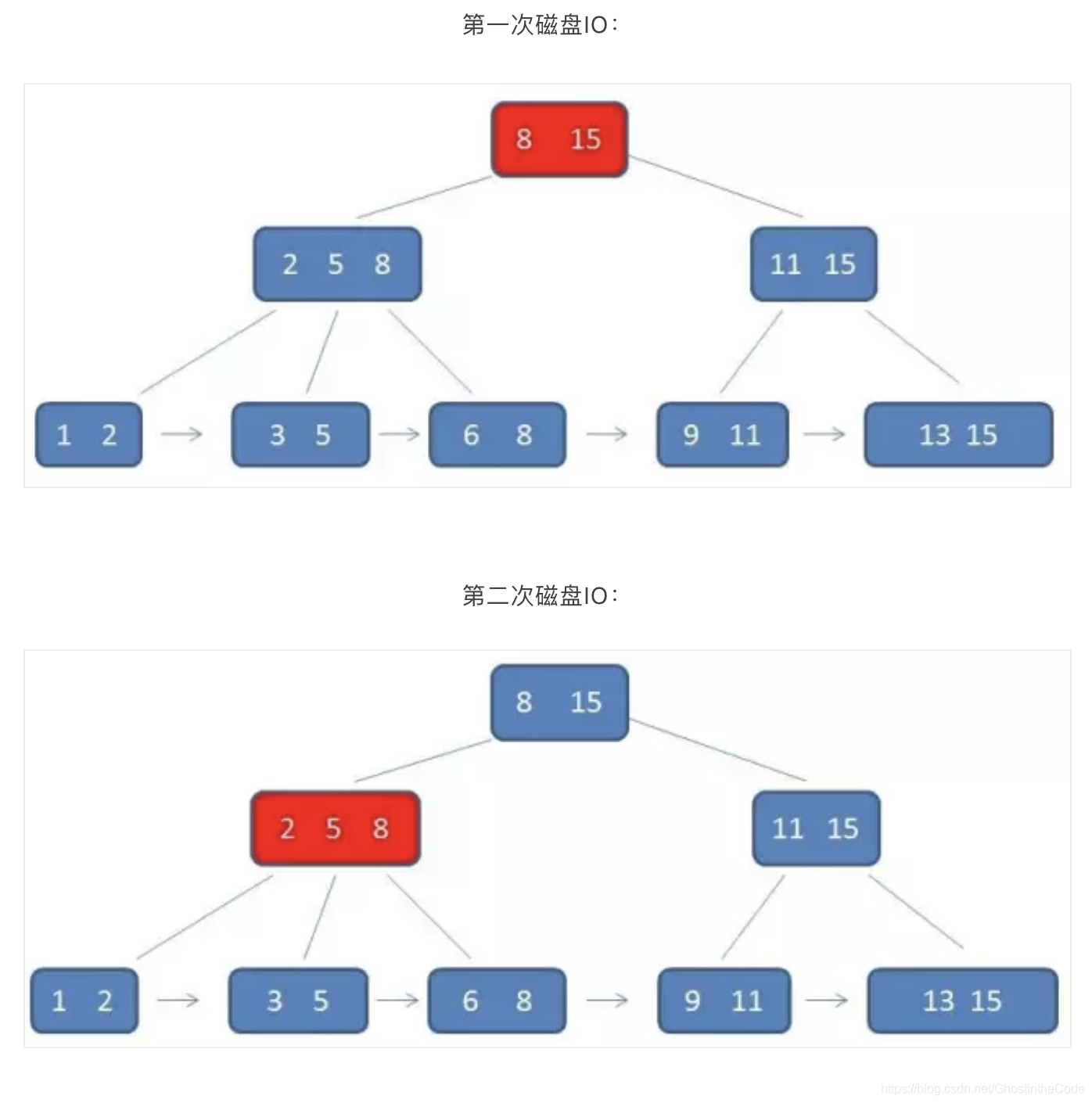

与B-树看起来差不多,其实有两点不同:
(1)B+树中看节点没有卫星数据,所以同样大小的磁盘页可以容纳更多的节点元素。这就意味着,数据量相同的情况下,B+树的结构比B-树更加“矮胖”,因此查询时IO次数也更少。
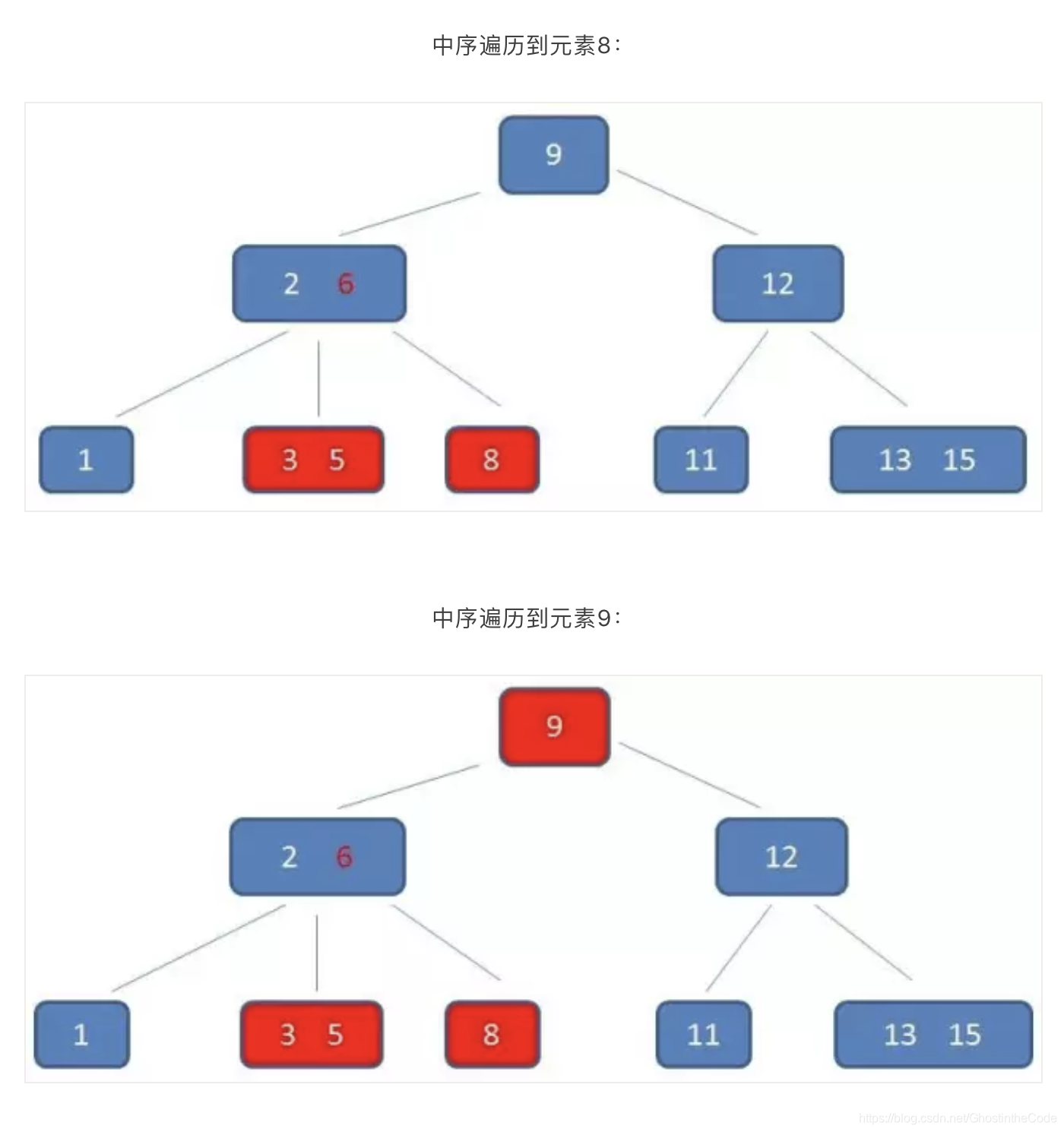
(2)B+树的查询必须最终查找到叶子节点,而B-树只要找到匹配元素即可,无论匹配元素处于中间节点还是叶子节点。因此B-树的查找性能并不稳定。而B+树的每次查找都是稳定的。(尽管每次都要查找到叶子节点,但是B+树矮胖,所以IO次数比B-树查找到叶子要少。) - 范围查找:B-树在进行范围查找的时候,只能依靠繁琐的中序遍历(先左,然后根,再右)。如查找3-11.
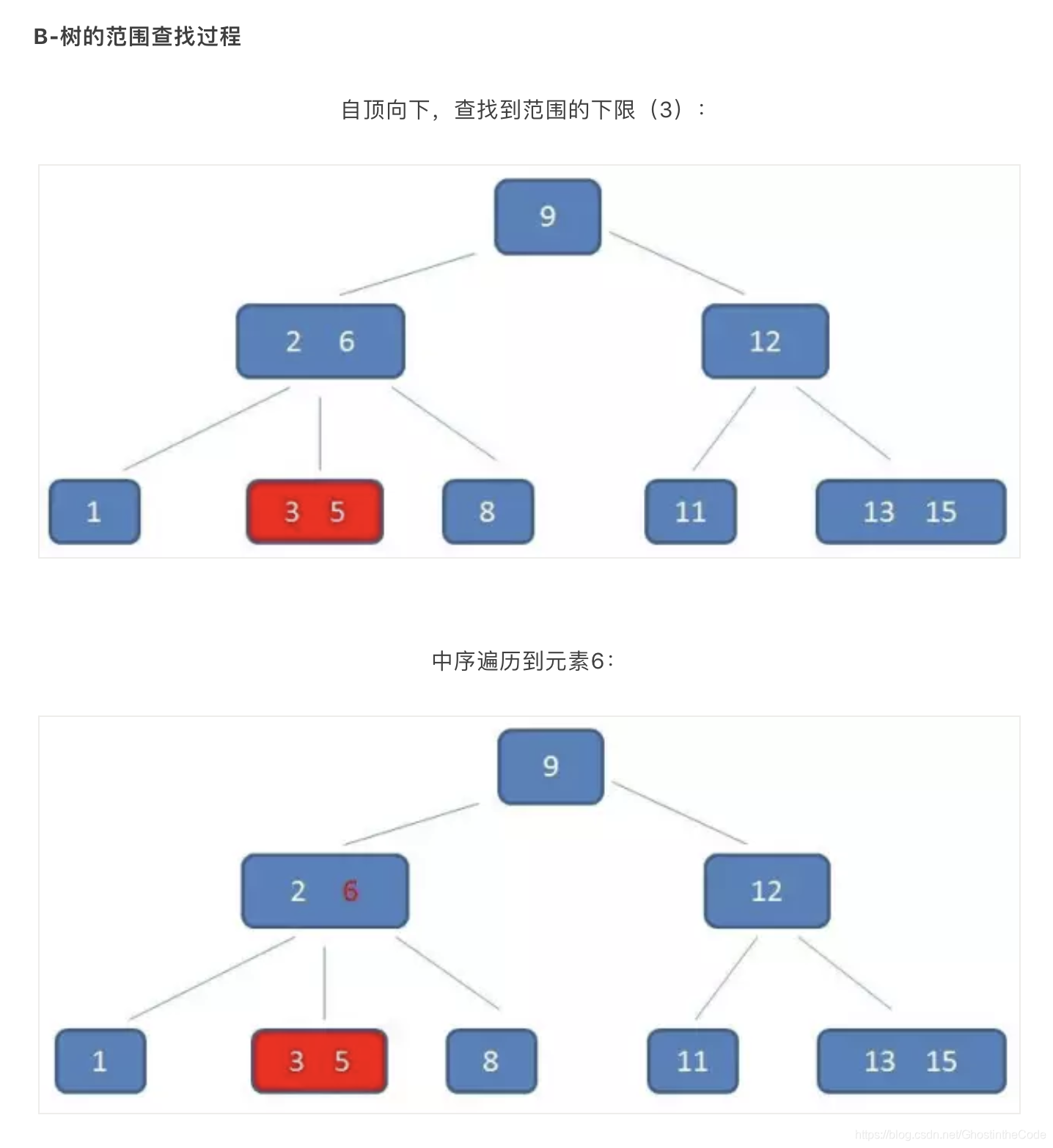

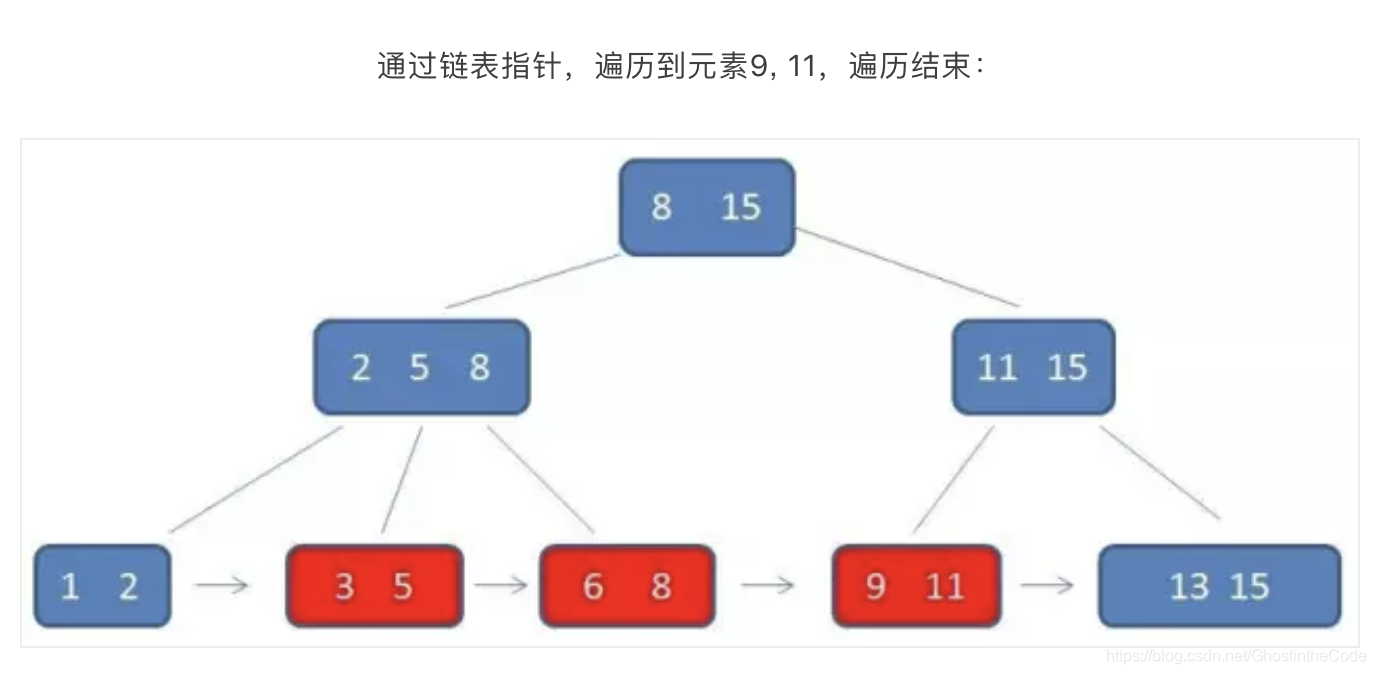
B+树的范围查找则简单得多,只需要在链表上左遍历即可:


拓展–B*树
内有B*树讲解
总的来说B*树是B+树的变体。在B+树基础上,为非叶子结点也增加链表指针,将结点的最低利用率从1/2提高到2/3;
总结
