本文为翻译的文章,作者Shubham Aggarwal,原文:
https://linuxhint.com/elasticsearch-tutorial-beginners/
在这次课中,我们将会看到如何使用Elasticsearch以及它的用途是什么。我们将会详尽地看一下它所涉及的各种各样的术语并开始用它来工作。
Elasticsearch数据库
Elasticsearch是最流行的NoSQL数据库之一,用来存储和检索基于文本的数据。它基于Lucene检索技术,对于索引过的数据,能够在毫秒级别完成搜索。
根据Elasticsearch官网,下面是它的定义:
Elasticsearch是一个开源的,分布式的,RESTful风格的搜索分析引擎,能够解决越来越多的用户案例中的问题。
上面是关于Elasticsearch的一些概括性语言。让我们来详细了解其中的概念:
分布式:Elasticsearch把它包含的数据分成多个结点,并且内部使用主从算法。
RESTful: Elasticsearch通过REST API来支持数据库查询。这意味着我们可以使用简单的HTTP调用,以及象GET, POST, PUT, DELETE这样的HTTP方法来访问数据。
搜索分析引擎: ES支持在系统中运行高度分析型的查询,包括聚合查询以及多种类型的查询,象结构化,非结构化和地理查询。
水平扩展: 这种类型的扩展是指在一个已有的集群中添加更多的机器。这意味着ES能够在集群中接受更多的结点,并且系统升级时不会宕机。看看下图来理解扩展的概念:

开始使用Elasticsearch数据库
要开始使用Elasticsearch,必须要在机器上安装它。
确保Elasticsearch的安装有效,如果你想试验本节课后半部分的例子。
Elasticsearch:概念及组件
我们在本节会看到Elasticsearch中的核心组件和概念。理解这些概念对于掌握ES是如何工作的非常重要:
集群:一个集群是存放数据的机器(结点)集合。数据分布在多个结点,所以它能被复制,并且ES服务器不会发生单点失败的情况。集群的默认名称是elasticsearch,集群中的每个结点都通过URL和集群名称与集群连接,所以让集群的名字独特清楚非常重要。
结点:一个结点机器是服务器的一部分,被称为单机。它存储数据,并且与其他结点一起为集群提供索引和检索能力。基于水平扩展的概念,实际上我们能够在ES集群中添加无限个结点,以提供更强大的检索能力。
索引: 索引是具备某些相似特点的文档的集合。它与基于SQL环境的数据库非常相似。
类型: 类型用来区分同一个索引中的数据。比如,客户数据库/索引可以有多种类型,比如用户,支付类型等。注意,ES v6.0.0往后,不再支持类型。
文档: 文档是表示数据的最低层级的单元。把它想象成一个包含数据的JSON对象。在一个索引内部创建很多文档是有可能的。
Elasticsearch搜索的类型
Elasticsearch以其接近于实时检索的能力和被检索数据类型的灵活性而闻名。让我们开始学习如何运用多种数据类型来进行搜索。
结构化搜索: 这种类型的搜索运行在预先定义格式的数据之上,比如日期,时间,数字。预先定义格式带来了某些通用操作的灵活性,比如比较日期范围。有意思的是,文本数据也可以被结构化。当一个字段是几个固定值的时候,就会有这种现象发生。比如,数据库名字可以是 MySQL, MongoDB, Elasticsearch, Neo4J 等. 有了结构化搜索,搜索的答案就是是或否。
全文检索: 这种类型的搜索依赖于两个重要的因素:相关度和分析。通过相关度,为结果文档定义一个分数,我们能确定数据与查询的匹配度。这个分数是ES自身提供的。分析是把文本分解成标准化的标记,以创建一个反向索引。
多域检索: 随着ES中的分析查询越来越多,我们通常不会只处理简单的匹配查询。跨域查询并返回计分排序的数据集,这样的需求在增加。通过这种方式,数据能够以更加高效的方式呈现给终端用户。
邻近匹配: 现在的查询不仅仅是识别文本数据中是否包含了别的字符串,它在数据之间建立关联,以便能够进行评分并在上下文中进行匹配。比如:
Ball hit John
John hit the Ball
John bought a new Ball which was hit Jaen garden
当搜索Ball hit的时候,匹配查询会找到三条文档。而邻近匹配能够告诉我们,这两个单词在同一行上或者短文上相间隔的距离。
部分匹配: 我们经常需要运行部分匹配的查询。部分匹配允许我们运行只有一部分匹配的查询。为了让这个概念更具体化,我们来看看基于SQL的相似的查询:
SQL查询:部分匹配
WHERE name LIKE “%john%”
AND name LIKE “%red%”
AND name LIKE “%garden%”
在某些情况下,我们只需要运行部分匹配的查询,即使它们被认为是比较暴力的技巧。
与Kinana集成
当提及分析引擎的时候,我们经常需要在人工智能域运行分析查询。对于业务分析员和数据分析员来说,假定他们掌握一种编程语言以便让ES集群中的数据能够可视化的呈现,这样是不公平的。这个问题可以由Kibana来解决。
Kibana给BI提供了如此多的好处,使得人们能够在非常出色的可定制化的仪表盘上让数据可视化,并且交互式地查看数据。让我们看看其中的一些好处。
交互式图表
Kibana的核心就是象下面这样的交互式图表:

Kibana提供了多种类型的图表,比如饼图,旭日图,柱状图,以及更多的使用ES聚合能力的图表。
地图支持
Kibana支持完整的地理聚合功能,让我们可以对数据进行地理地图化。这难道不是很酷吗?
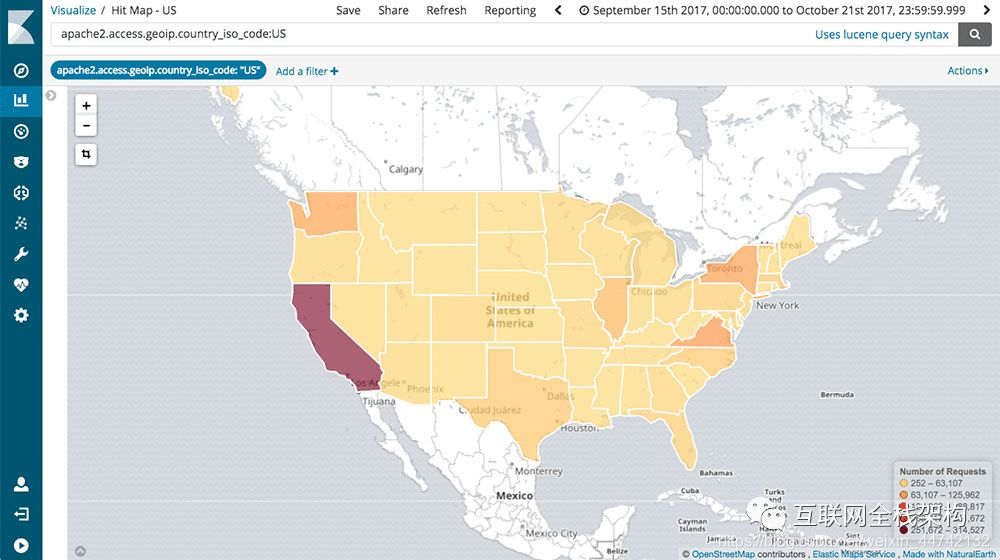
预制的聚合和过滤
有了预制的聚合和过滤,在Kibana仪表盘内拖拽并运行高度优化的查询是有可能的。只需要几次点击,就能运行聚合的查询并以交互式图表的形式来呈现结果。
简易的仪表盘发布
有了Kibana,通过Dashboard Only的模式,可以非常容易地把仪表盘在更多的受众中进行分享,且不用做任何改变。我们可以很容易地把仪表盘插入到我们的内部wiki或者web页面中。
使用Elasticseach
运行以下命令来观察实例的详细情况和集群的信息:
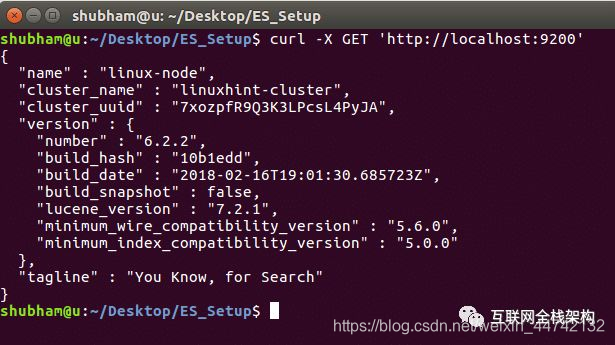
现在,我们可以用以下的命令来尝试往ES中插入数据:
curl
-X POST ‘http://localhost:9200/linuxhint/hello/1’
-H ‘Content-Type: application /json’
-d ‘{ “name” : “LinuxHint” }’
这是该命令返回的结果:

让我们现在来尝试获取数据:
curl -X GET ‘http://localhost:9200/linuxhint/hello/1’
当我们运行这个命令,我们得到以下的输出:

结论
在这次课中,我们着眼于如何开始使用ElasticSearch,它是一个非常棒的分析引擎,也提供了出色的接近于实时计算的自由文本检索。
欢迎关注微信公众号,获取更多信息。
