1.Java有哪几种类型

1、
基本类型:int 二进制位数:32
包装类:java.lang.Integer
最小值:Integer.MIN_VALUE= -2147483648 (-2的31次方)
最大值:Integer.MAX_VALUE= 2147483647 (2的31次方-1)
2、
基本类型:short 二进制位数:16
包装类:java.lang.Short
最小值:Short.MIN_VALUE=-32768 (-2的15此方)
最大值:Short.MAX_VALUE=32767 (2的15次方-1)
3、
基本类型:long 二进制位数:64
包装类:java.lang.Long
最小值:Long.MIN_VALUE=-9223372036854775808 (-2的63次方)
最大值:Long.MAX_VALUE=9223372036854775807 (2的63次方-1)
4、
基本类型:float 二进制位数:32
包装类:java.lang.Float
最小值:Float.MIN_VALUE=1.4E-45 (2的-149次方)
最大值:Float.MAX_VALUE=3.4028235E38 (2的128次方-1)
5、
基本类型:double 二进制位数:64
包装类:java.lang.Double
最小值:Double.MIN_VALUE=4.9E-324 (2的-1074次方)
最大值:Double.MAX_VALUE=1.7976931348623157E308 (2的1024次方-1)
2.基本类型的装箱拆箱(×2)
-
装箱,拆箱的定义
- 装箱:将基本数据类型转换为包装器类型(JavaSE5之后提供了自动装箱的特性) 调用Integer.valueOf(x);
- 拆箱:将包装器类型转换为基本数据类型 调用Integer.intValue(obj)
| 基本数据类型 | 包装器类 |
|---|---|
| int(4Byte) | Integer |
| byte(1) | Byte |
| short(2) | Short |
| long(8) | Long |
| float(4) | Float |
| double(8) | Double |
| char(2) | Char |
| boolean(1字节) | Boolean |
细节注意:Integer的Valueof方法中调用了一个IntegerCache的静态类。静态类中针对数值为-128~127范围内的数据,返回指向IntegerCache.cache中已经存在的对象的引用;否则创建一个新的Integer对象。
new出来的对象肯定不等;(new Integer(1)!=new Integer(2))
自动装箱的可能相等(Integer c =1;Integer d =1 -> c==d true)
Boolean包装器valueOf方法中直接定义了TRUE和FALSE的两个静态成员变量(存于方法区),所以无论怎么new都是指向同一个
- 谈谈Integer i = new Integer(xxx)和Integer i =xxx;这两种方式的区别?
- 第一种方式不会触发自动装箱的过程;而第二种方式会触发;
- 在执行效率和资源占用上的区别。第二种方式的执行效率和资源占用在一般性情况下要优于第一种情况(注意这并不是绝对的)。
- 为什么要有基本类型和包装类型
- 基本类型存在的必要:java中new的对象存储在堆中,栈中保存其引用;但是对于一些常用并且短小的数据对象(如int),如果使用new创建将会存储在堆中,不是很有效。对于这些常用类型我们不用new创建,而是将变量的值保存在栈中,更加高效。
- 包装类型存在的必要:Java是面向对象的语言,基本类型不具有对象的特性。使用包装器类相当于将基本类型包装起来,使其具有方法和属性,丰富基本类型的操作
-
基本类型和包装类型的区别
- 存储方式和位置不同:基本类型存储的是数值,存放栈中,直接使用;包装器类存储的是对象存堆中,通过栈中引用使用
- 对象特性:基本类型不是对象,没有方法 ;包装器类是类具有方法
- 声明方式:基本类型可以直接赋值;包装器类需要new或者自动装箱
- 初始值:包装器类对象的初始值为null;基本类型的初始值不为null,根据具体类型而定
- 使用情形:基本类型直接赋值使用;包装类型常用于集合
Java学习笔记(六)–包装类、基本类型、拆箱、装箱:https://blog.csdn.net/zh15732621679/article/details/79623414
深入剖析Java中的装箱和拆箱: http://www.cnblogs.com/dolphin0520/p/3780005.html
3.String、StringBuffer和StringBuilder的区别
1、String是字符串常量,StringBuffer和StringBuilder都是字符串变量。后两者的字符内容可变,而前者创建后内容不可变。
2、String不可变是因为在JDK中String类被声明为一个final类。
3、StringBuffer是线程同步且安全的(用synchronized修饰),而StringBuilder是非同步且非线程安全的。
4.执行速度:StringBuilder > StringBuffer > String(String为常量不可更改所以最慢)
ps:线程安全会带来额外的系统开销,所以StringBuilder的效率比StringBuffer高。如果对系统中的线程是否安全很掌握,可用StringBuffer,在线程不安全处加上关键字Synchronize。
String:适用于少量的字符串操作的情况
StringBuilder:适用于单线程下在字符缓冲区进行大量操作的情况
StringBuffer:适用多线程下在字符缓冲区进行大量操作的情况
Tips:
- StringBuffer默认初始容量为s+16(不赋s时就是16);扩容:×2+2
- String的+拼接操作的底层实现:首先判断str1是否为空,然后new一个StringBuilder对象通过append连接之后toString:
StringBuilder(“null”).append(“abc”).toString();
4.Java中有哪几种创建线程的方式
4.1四种创建方式
- 继承Thread类创建(Tthread类的底层也是继承了Runnable接口)

- 实现Runnable接口创建
1.重写Runnable中run方法
public class MyRunnable extends OtherClass implements Runnable {
public void run() {
System.out.println("MyThread.run()");
}
}
2.实例化一个Thread对象,并传入自己的MyRunnable实例
MyRunnable myr = new MyThread();
Thread thread = new Thread(myr);
thread.start();
3.事实上,当传入一个Runnable target参数给Thread后,Thread对象的run()方法就会调用target.run():jdk源码
public void run() {
if (target != null) {
target.run();
}
}
- 实现Callable接口通过FutureTask包装器来创建(相较于实现Runnable接口的方式,方法可以有返回值,并且可以抛出异常)
重写Callable中的call方法
通过FutureTask包装器类创建对象,然后传入Thread对象实例中

- 线程池创建
java线程池详解:http://www.importnew.com/29813.html
java常用的几种线程池比较:https://www.cnblogs.com/aaron911/p/6213808.html
Tips1:通过继承Thread类创建和实现Runnable接口创建有什么区别
继承Runnable接口的3个优势:
- 适合多个相同程序代码的线程去处理同一个资源的情况
- 避免由于单继承带来的局限性
- 增强了程序的健壮性,代码可以被多个线程共享,代码与数据多礼
Tips2:线程中run和start方法的区别
调用start()方法后不会立刻执行,线程会被放到等待队列,等待CPU调度,线程进入就绪状态;调用run()方法后,直接执行线程的线程体(即run方法)。调用start()的原因是为了真正实现多线程运行
java Future接口介绍:https://blog.csdn.net/liutong123987/article/details/79377764
Java并发编程:Callable、Future和FutureTask原理解析:https://blog.csdn.net/codershamo/article/details/51901057
JAVA多线程实现的四种方式(该篇重点看线程池)
https://www.cnblogs.com/felixzh/p/6036074.html
4.2各自使用场景(?自己想的不一定对)
Thread:继承父类
Runable:对同一资源进行多线程竞争;类已经extends某个父类不能够继承Thread
Callable:要求有返回值
Pool:一个应用中多次使用线程,需要对线程进行统一管理,对线程有多种约束
5.线程池的了解
- 为什么提出线程池的概念?
在一个应用程序中可能需要多次使用线程,这将导致多次创建和销毁线程,这个过程消耗大量内存。而在java中内存十分宝贵,所以提出线程池的概念。线程池开辟了一种管理线程的概念,目的:节约内存 - 线程池内部参数
public ThreadPoolExecutor(int corePoolSize, //核心线程数,即使不被使用也不收回
int maximumPoolSize, //线程中可容纳的最大线程数
long keepAliveTime, //针对非和新县城来说,可以在贤臣池中存活的最长时间
TimeUnit unit, //计时单位
BlockingQueue<Runnable> workQueue, //等待队列,任务可以存储在等待队列中等待被执行(FIFO)
ThreadFactory threadFactory, //船舰现成的工厂
RejectedExecutionHandler handler)//拒绝策略

-
线程池的操作流程:
- 任务进来
- 判断核心线程池是否已满:若没满,加入核心线程池开始执行;否则执行3
- 判断任务队列是否已满:若没满,加入队列等待;否则,执行4
- 判断最大可容纳线程容量:若没超,开创非核心线程执行任务;否则执行handler拒绝策略(4种:直接丢弃,最老丢弃,调用者线程execute,抛出异常)。

-
四种常见的线程池:
1.CachedThreadPool:可缓存的线程池,该线程池中没有核心线程,非核心线程的数量为Integer.max_value,就是无限大,当有需要时创建线程来执行任务,没有需要时回收线程,适用于耗时少,任务量大的情况。2.SecudleThreadPool:周期性执行任务的线程池,按照某种特定的计划执行线程中的任务,有核心线程,但也有非核心线程,非核心线程的大小也为无限大。适用于执行周期性的任务。
3.SingleThreadPool:只有一条线程来执行任务,适用于有顺序的任务的应用场景。
4.FixedThreadPool:定长的线程池,有核心线程,核心线程的即为最大的线程数量,没有非核心线程 -
使用线程池的好处
1.使用new Thread的弊端:- 每次通过new创建对象,性能不佳;
- 缺乏对线程的统一管理,可能无限制新建线程,竞争加大,会导致资源紧缺司机或者oom
- 缺乏更多功能:定时执行,定期执行,线程中断
2.使用线程池的好处:
- 重用存在的线程,减少对象的创建和销毁,提升性能
- 有效控制最大并发线程数,提高资源利用率,避免过多竞争,堵塞
- 提供定时执行,定期执行,单线程和并发数控制。
6.java集合容器,讲一个你比较熟悉的
7.hashmap和concurrenthashmap
(1)ConcurrentHashMap对整个桶数组进行了分割分段(Segment),然后在每一个分段上都用lock锁进行保护,相对于HashTable的syn关键字锁的粒度更精细了一些,并发性能更好,而HashMap没有锁机制,不是线程安全的。
(2)HashMap的键值对允许有null,但是ConCurrentHashMap都不允许。
Java集合——HashMap、HashTable以及ConCurrentHashMap异同比较:https://www.cnblogs.com/zx-bob-123/archive/2017/12/26/8118074.html
面试必备:HashMap、Hashtable、ConcurrentHashMap的原理与区别:https://www.cnblogs.com/heyonggang/p/9112731.html
8.线程池的拒绝策略
- AbortPolicy:抛出异常
- DisCardPolicy:直接丢弃
- DisCardOldSetPolicy:丢弃最老的线程(队列中第一个)
- CallerRunsPolicy:用调用者线程执行(execute方法)
《Java线程池》:任务拒绝策略 :https://www.cnblogs.com/zhangtan/p/7607321.html
9.数据库优化
MySQL数据库优化的八种方式(经典必看):https://blog.csdn.net/zhangbijun1230/article/details/81608252
数据库SQL优化大总结之 百万级数据库优化方案:https://www.cnblogs.com/yunfeifei/p/3850440.html
MySQL优化技术——20条建议:https://blog.csdn.net/qq_37939251/article/details/83022638
MYSQL 八大优化方案: https://blog.csdn.net/liuyanqiangpk/article/details/79827239
数据库优化一般思路(个人经验之谈):https://blog.csdn.net/zhoupan301415/article/details/78257783
10.说一下堆和栈
java把内存划分为两种:堆内存和栈内存。
- 堆:主要用于存储实例化对象,数组。由JVM动态分配,一个JVM只有一个堆内存且线程共享;
- 栈:主要用于存储局部变量(基本数据类型)和对象的引用。线程私有。
在函数中定义的一些基本类型的变量和对象的引用变量都在函数的栈内存中分配。 当在一段代码块定义一个变量时,Java就在栈中为这个变量分配内存空间,当超过变量的作用域后,Java会自动释放掉为该变量所分配的内存空间,该内存空间可以立即被另作他用。
堆内存用来存放由new创建的对象和数组。在堆中分配的内存,由Java虚拟机的自动垃圾回收器来管理。
1.栈内存存储的是局部变量而堆内存存储的是实体;
2.栈内存的更新速度要快于堆内存,因为局部变量的生命周期很短;
3.栈内存存放的变量生命周期一旦结束就会被释放,而堆内存存放的实体会被垃圾回收机制不定时的回收。
Java堆和栈的区别,JVM堆和栈的介绍:https://blog.csdn.net/qq_41675686/article/details/80400775
11.线程安全问题
12.TCP四次挥手的timewait状态
网络是不可靠的,有可以最后一个ACK丢失。所以TIME_WAIT状态就是用来重发可能丢失的ACK报文。在Client发送出最后的ACK回复,但该ACK可能丢失。Server如果没有收到ACK,将不断重复发送FIN片段。所以Client不能立即关闭,它必须确认Server接收到了该ACK。Client会在发送出ACK之后进入到TIME_WAIT状态。Client会设置一个计时器,等待2MSL的时间。如果在该时间内再次收到FIN,那么Client会重发ACK并再次等待2MSL。所谓的2MSL是两倍的MSL(Maximum Segment Lifetime)。MSL指一个片段在网络中最大的存活时间,2MSL就是一个发送和一个回复所需的最大时间。如果直到2MSL,Client都没有再次收到FIN,那么Client推断ACK已经被成功接收,则结束TCP连接。
下面这个连接包括具体建立连接和释放连接的流程以及常见面试题
TCP的三次握手与四次挥手理解及面试题(很全面):https://blog.csdn.net/qq_38950316/article/details/81087809
Tips:为什么建立连接要三次握手
- 防止已过期的连接再次传到服务器,错误的建立连接
**举例:**如果采用两次的话,会出现下面这种情况。比如是A机要连到B机,结果发送的连接信息由于某种原因没有到达B机;于是,A机又发了一次,结果这次B收到了,于是就发信息回来,两机就连接。传完东西后,断开。
结果这时候,原先没有到达的连接信息突然再次传到了B机,于是B机发信息给A,然后B机就以为和A连上了,这个时候B机就在等待A传东西过去,而此时A已经没有信息可发,所以导致错误。 - TCP为了实现可靠传输,发送方和接收方都需要同步(SYN)序号。值得注意的是,同步序号不是从0开始,而是各自随机选择初始序列号。由于TCP是全双工的,通信双方都有能力接受和发送数据,因此双方都需要随机一个SYN序号并告诉对方,然后双方都要确认(三次而不是四次的原因是 服务器对客户的ack和服务器自身的SYN合并发送)如果只是两次握手, 至多只有连接发起方的起始序列号能被确认, 另一方选择的序列号则得不到确认。
举例:如果只是握手两次,客户端认为服务器已经准备好,不断发送数据;但是服务器没有收到来自客户端的确认,认为连接不成立,忽视来自客户的数据;最终导致客户端A一直重复发送数据而得不到服务器B的确认,服务器B一直忽视A发来的数据等待A对自己的确认,造成死锁)
Tcp为什么是三次握手而不是两次:https://blog.csdn.net/lengxiao1993/article/details/82771768
13.面向对象的三个特点(封装继承多态)
封装:将类的某些信息隐藏在类内部,不允许外部程序直接访问,而是通过该类提供的方法来实现对隐藏信息的操作和访问。
- 封装的好处: 只能通过规定的方法访问数据; 隐藏类的实例细节,方便修改和实现。
- 封装的过程:

继承:类与类的一种关系,是一种**“is a”**的关系。比如“狗”继承“动物”,这里动物类是狗类的父类或者基类,狗类是动物类的子类或者派生类。
- 继承的好处:子类拥有父类的所有属性和方法(除了private修饰的属性不能拥有)从而实现了实现代码的复用
- 方法重写,发生在继承,是运行时多态
多态:多种形态(比如接口的多种不同实现方式)
java中多态的两种表现
- 引用多态: 父类的引用可以指向本类的对象;父类的引用可以指向子类的对象;
- 方法多态: 根据上述创建的两个对象:本类对象和子类对象,同样都是父类的引用,当我们指向不同的对象时,它们调用的方法也是多态的。创建本类对象时,调用的方法为本类方法;创建子类对象时,调用的方法为子类重写的方法或者继承的方法;
JAVA基础——面向对象三大特性:封装、继承、多态 :https://www.cnblogs.com/hysum/p/7100874.html
14.死锁,如何产生的,发生条件
-
死锁定义:是指多个进程在运行过程中因争夺资源而造成的一种僵局,若无外力作用,它们都将无法再向前推进。
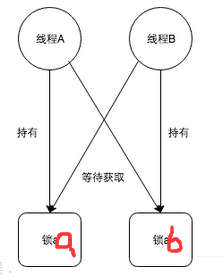
-
产生死锁的原因
-
竞争资源
- 临时资源:(硬件中断、信号、消息、缓冲区内的消息等)竞争临时资源,通常消息通信顺序进行不当,则会产生死锁
- 不可剥夺资源:比如打印机(可剥夺资源有:CPU,主存)
-
进程间顺序的非法推进
-
-
死锁发生条件
- 互斥条件:进程要求对所分配的资源进行排它性控制,即在一段时间内某资源仅为一进程所占用。
- 请求和保持条件:当进程因请求资源而阻塞时,对已获得的资源保持不放。
- 不剥夺条件:进程已获得的资源在未使用完之前,不能剥夺,只能在使用完时由自己释放。
- 环路等待条件:在发生死锁时,必然存在一个进程–资源的环形链。
-
解除死锁
- 剥夺资源:从其它进程剥夺足够数量的资源给死锁进程,以解除死锁状态;
- 撤消进程:可以直接撤消死锁进程或撤消代价最小的进程,直至有足够的资源可用,死锁状态.消除为止;所谓代价是指优先级、运行代价、进程的重要性和价值等。
-
预防死锁
- 资源一次性分配:一次性分配所有资源,这样就不会再有请求了:(破坏请求条件)
- 只要有一个资源得不到分配,也不给这个进程分配其他的资源:(破坏请保持条件)
- 可剥夺资源:即当某进程获得了部分资源,但得不到其它资源,则释放已占有的资源(破坏不可剥夺条件)
- 资源有序分配法:系统给每类资源赋予一个编号,每一个进程按编号递增的顺序请求资源,释放则相反(破坏环路等待条件)
以确定的顺序获得锁和超时放弃
-
检测死锁
首先为每个进程和每个资源指定一个唯一的号码; 然后建立资源分配表和进程等待表。 -
避免死锁
- 判断“系统安全状态”法:在进行系统资源分配之前,先计算此次资源分配的安全性。若此次分配不会导致系统进入不安全状态,则将资源分配给进程; 否则,让进程等待。
- 银行家算法:
首先需要定义状态和安全状态的概念。系统的状态是当前给进程分配的资源情况。因此,状态包含两个向量Resource(系统中每种资源的总量)和Available(未分配给进程的每种资源的总量)及两个矩阵Claim(表示进程对资源的需求)和Allocation(表示当前分配给进程的资源)。安全状态是指至少有一个资源分配序列不会导致死锁。当进程请求一组资源时,假设同意该请求,从而改变了系统的状态,然后确定其结果是否还处于安全状态。如果是,同意这个请求;如果不是,阻塞该进程知道同意该请求后系统状态仍然是安全的。
1、申请的贷款额度不能超过银行现有的资金总额
2、分批次向银行提款,但是贷款额度不能超过一开始最大需求量的总额
3、暂时不能满足客户申请的资金额度时,在有限时间内给予贷款
4、客户要在规定的时间内还款
银行家算法——概念和举例:https://blog.csdn.net/wyf2017/article/details/80068608
- 检查死锁的工具
- Jstack命令:java虚拟机自带的一种堆栈跟踪工具。jstack用于打印出给定的java进程ID或core file或远程调试服务的Java堆栈信息 .可以打印堆栈快照
- Jconsole:是JDK自带的监控工具,在JDK/bin目录下可以找到。它用于连接正在运行的本地或者远程的JVM,对运行在Java应用程序的资源消耗和性能进行监控
死锁面试题集合:https://blog.csdn.net/hd12370/article/details/82814348
15.线程和进程
- 进程是资源分配的单位,线程是执行的单位,线程不可以独立执行。线程是进程的一个执行序列
- 进程之间通信IPC,线程之间的通信可以通过读写进程数据段通信。线程通信的目的是:线程同步;进程通信的目的是为了交换数据。锁机制,信号量,信号机制
- 进程切换比线程切换慢
- 进程之间相互独立,同一个进程的各线程之间共享。一个进程内的线程对另一个进程不可见
进程线程通信的区别:https://www.cnblogs.com/xh0102/p/5710074.html
什么是线程?线程的优缺点和使用场景:https://blog.csdn.net/ffsiwei/article/details/81230374
16.内存池
17.tcp,udp特点,区别,应用场景(×2)
18.hashmap技术细节(×2)
19.java垃圾回收机制,怎么排查
19.1.gc了解多少/CMS工作步骤/CMS优缺点
20.Java如何使用线程?重写Run方法和实现Runable接口有什么不同?
21.如何进行线程管理
22.设计模式的了解(手写双重检查锁的单例模式 )
23.http和https的区别
24.详细讲一下浏览器输入网址到显示出网页的全部网络交互过程
25.线程池设计思路
26.消息队列概念及使用
27.一个100G的文件里,记录了不重复的数字,只给单台1G内存的主机,如何快速的查找某一个数字。
多线程分片:分多少片?
问题升级一下,这个数据集内数字可重复,找出重复次数最多的
28.画出线程的状态之间的转化

29.冒泡排序
30.new一个对象jvm内存区域的情况
31.sql注入在ssm框架里如何解决
32.cookie,session
33.tcl了解吗
34…线程池参数/调优/无界阻塞队列/和阻塞队列put、offer、add三种方法有何区别(就是是否阻塞,会不会抛出异常)
35.b+树的结构,说说插入元素操作如何进行,还提了一下叶子节点的连接
36.二叉树前序遍历
37.迭代器的实现?
38.深拷贝浅拷贝
39.类的继承,具体问的啥忘了,super的用法吧好像
40.除了修改构造函数,还能通过什么方法编辑一个类的属性?(当时心里mmp这啥问题,现在觉得大概是想让我说 @property或者slots)
41.数据库事务
42.双向链表实现
43.生产消费者模式(多线程)
44.String的底层hashcode怎么写的
45.-6的补码多少
46.看了那些源码(hashmap,string的equals)
47.多线程原理
synchronized,volatile
48.内存划分(补,非面试题)
Java中成员变量、局部变量、全局变量、静态变量存在位置及初始化:https://blog.csdn.net/sophia__yu/article/details/83578934
.