_T、_TEXT、L、TEXT之间的区别
在分析前先对三者做一个简单的分类

_T、_TEXT、TEXT三者都是根据编译器的环境进行ANSI/UNICODE变换的,_T和_TEXT是根据_UNICODE来确定宏,而TEXT是根据UNICODE来确定宏,
(_UNICODE宏用于C运行期头文件,而UNICOED则用于Windows头文件,当编译源代码模块时,通常必须同时定义这两个宏)
第一种:L" "
在字符串前加一个大写字母L表示,告诉编译器这个字符串按照宽字符来存储,每个字符占2个字节
格式为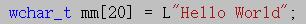 或者
或者 ,L的特点就是无论以什么方式编译,一律按照Unicode来编译(即每个字符占两个字节),这里说每个字符占两个字节,是因为Unicode字符集一般是指UTF-16编码的Unicode,但Unicode字符集不等于每个字符占两个字符
,L的特点就是无论以什么方式编译,一律按照Unicode来编译(即每个字符占两个字节),这里说每个字符占两个字节,是因为Unicode字符集一般是指UTF-16编码的Unicode,但Unicode字符集不等于每个字符占两个字符
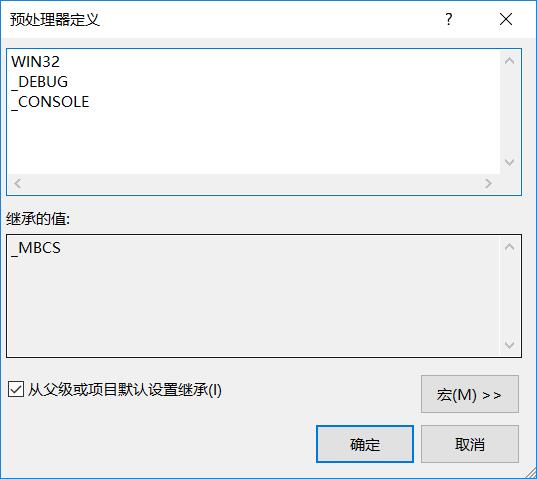
在VC2010Express下可以通过项目--属性--配置属性--常规来看编译方式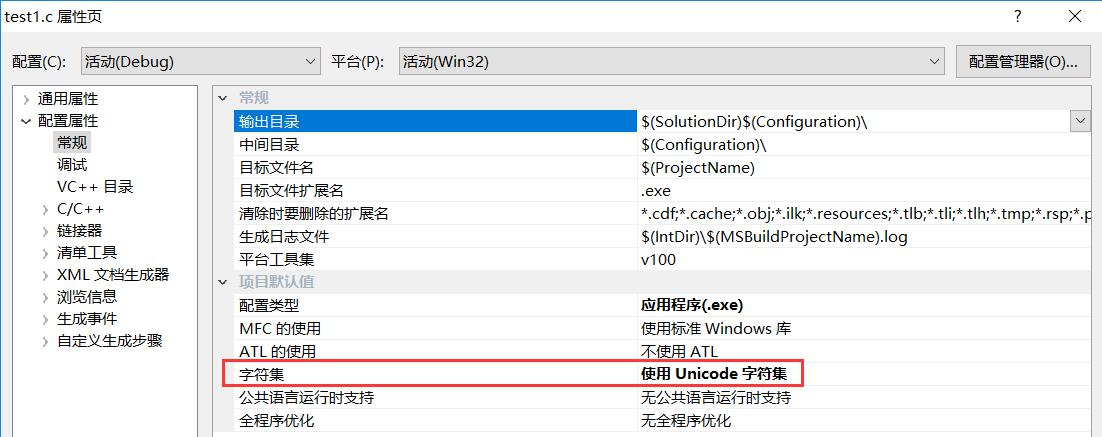
当使用Unicode字符集时,可以在C/C++--预处理器看到预编译宏_UNICODE和UNICODE
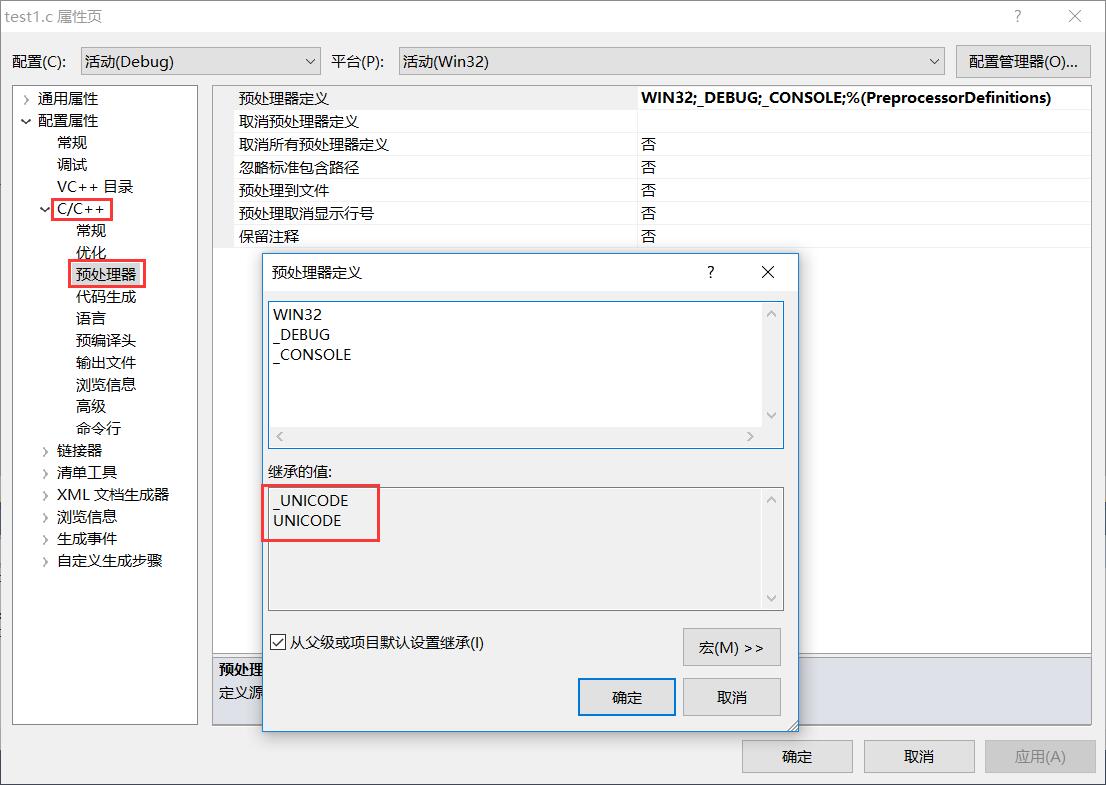
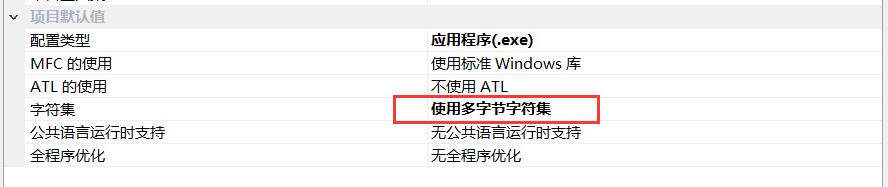
当设置为使用多字节字符集时,预编译宏会变为_MBCS
第二种:_T()和_TEXT()
_T和_TEXT都在头文件tchar.h中定义,在字符串之间加_TEXT或者是_T的效果是一样的,与L不同的是,如果项目使用了Unicode字符集(定义了UNICODE宏),则自动在字符串前面加上L,否则字符串不变
(意思是如果编译环境使用的多字符节字符集 或者是 未设置,那么字符串不变),_T和_TEXT是根据_UNICODE来确定宏的
在tchar.h中可以找到如下的宏定义
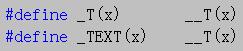
使用格式:(注意:圆括号是不能省略的)
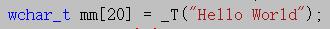
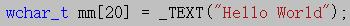
下面把环境改成多字节字符集
char ss[20] = _T("Hello World");
wchar_t mm[20] = L"Hello World";
printf("%s\n", ss);
wprintf(L"%s", mm);
上面的代码中ss这个窄字符数组后面的字符串前面加了一个_T,但因为环境是多字节字符集,_T并没有起作用,字符串内容不变仍然按照窄字符存储,而第二个宽字符数组mm就不能写成_T或者_TEXT
因为不能把一个窄字符串存储到一个宽字符数组中,如果写成 那么在编译阶段就会报错
那么在编译阶段就会报错
第三种:TEXT()
需要注意的是如果只#include<WinNT.h>编译器是会报错的,需要在#include<WinNT.h>前加上#include <Windows.h>才能使用TEXT,TEXT是根据UNICODE来确定宏的,因为当编译环境使用Unicode字符集时,
因为预编译宏包含了_UNICODE和UNICODE ,所以在使用Unicode字符集的环境下_T、_TEXT、TEXT都可以使用
,所以在使用Unicode字符集的环境下_T、_TEXT、TEXT都可以使用
使用格式: