版权声明:路漫漫其修远兮,吾将上下而求索。 https://blog.csdn.net/Happy_Sunshine_Boy/article/details/89135292
1. 安装HDFS集群的具体步骤
1.1 集群节点规划
| 组件 |
描述 |
| 操作系统 |
CentOS-7-x86_64-DVD-1810.iso |
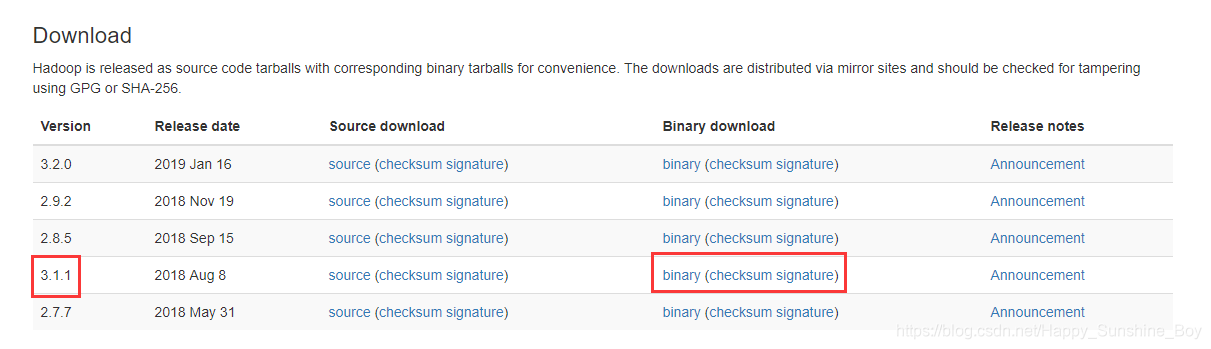
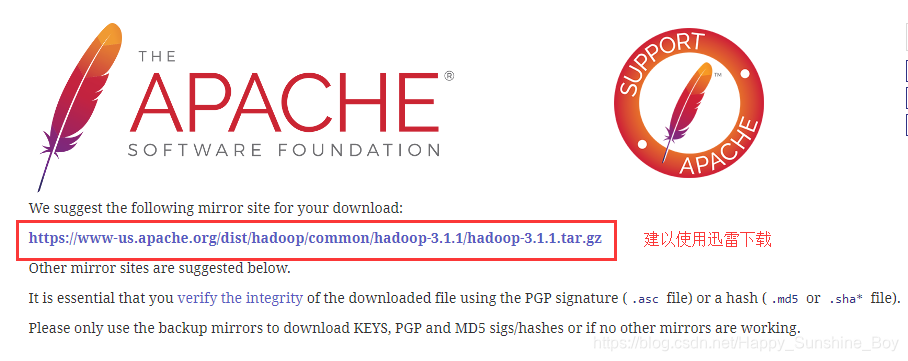
| Hadoop |
hadoop-3.1.1.tar.gz |
| OracleJDK8 |
jdk-8u121-linux-x64.tar.gz |
| X86 |
X86-64 |
| Hostname |
IP |
Functions |
内存 |
磁盘 |
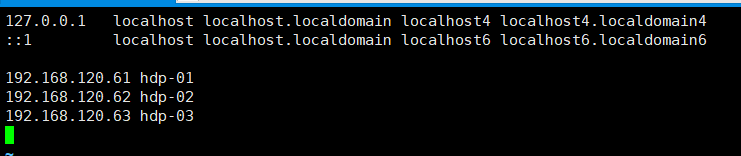
| hdp-01 |
192.168.121.61 |
namenode |
4G |
50G |
| hdp-02 |
192.168.121.62 |
datanode |
3G |
50G |
| hdp-03 |
192.168.121.63 |
datanode |
3G |
50G |
1.2 搭建hdp-01虚拟机
1.3 搭建HDFS集群
[root@hdp-01 ~]# rz # 上传hadoop安装包到hdp-01
[root@hdp-01 ~]# tar -zxvf hadoop-3.1.1.tar.gz -C /opt/ # 解压hadoop
# 配置环境变量
[root@hdp-01 hadoop-3.1.1]# vim /etc/profile
export HADOOP_HOME=/opt/hadoop-3.1.1
export PATH=$PATH:$HADOOP_HOME/bin
[root@hdp-01 hadoop-3.1.1]# source /etc/profile
| 要点 |
核心配置参数 |
| 1 |
指定hadoop的默认文件系统为:hdfs |
| 2 |
指定hdfs的namenode节点为哪台机器 |
| 3 |
指定namenode软件存储元数据的本地目录 |
| 4 |
指定datanode软件存放文件块的本地目录 |
# 指定hadoop的默认文件系统为:hdfs
[root@hdp-01 hadoop-3.1.1]# vim /opt/hadoop-3.1.1/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hdp-01:9000</value>
</property>
</configuration>
# 指定hdfs的namenode节点为哪台机器
# 指定namenode软件存储元数据的本地目录
# 指定datanode软件存放文件块的本地目录
[root@hdp-01 hadoop-3.1.1]# vim /opt/hadoop-3.1.1/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/hadoop/hdfs/name/</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>hdp-01:50070</value>
</property>
</configuration>
1.4 克隆虚拟机hdp-01
1.5 在hdp-01节点启动namenode进程
- 首先,初始化namenode的元数据目录
- 要在hdp-01上执行hadoop的一个命令来初始化namenode的元数据存储目录
- 创建一个全新的元数据存储目录
- 生成记录元数据的文件fsimage
- 生成集群的相关标识:如:集群id-clusterID
hadoop namenode -format
- 然后,启动namenode进程(在hdp-01上)
hdfs --daemon start namenode # 打开
hdfs --daemon stop namenode # 关闭
- 启动完后,首先用jps查看一下namenode的进程是否存在

- 然后,在windows中用浏览器访问namenode提供的web端口:50070
http://hdp-01:50070

- 然后,启动众datanode们(在任意地方):
hdfs --daemon start datanode # 打开
hdfs --daemon stop datanode # 关闭

1.6 安装启动YARN集群
- yarn集群中有两个角色:
- 主节点:Resource Manager 1台
- 从节点:Node Manager N台
- Resource Manager一般安装在一台专门的机器上,接受用户提交的分布式计算程序,并为其划分资源,管理、监控各个Node Manager上的资源情况,以便于均衡负载
- Node Manager应该与HDFS中的data node重叠在一起,管理它所在机器的运算资源(cpu + 内存)
负责接受Resource Manager分配的任务,创建容器、回收资源
| Hostname |
IP |
Functions |
| hdp-01 |
192.168.121.61 |
resource manager |
| hdp-02 |
192.168.121.62 |
node manager |
| hdp-03 |
192.168.121.63 |
node manager |
# 在hdp-01节点上修改文件
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hdp-01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
# 把yarn-site.xml配置文件发送到剩余节点
[root@hdp-01 hadoop]# scp yarn-site.xml hdp-02:$PWD
[root@hdp-01 hadoop]# scp yarn-site.xml hdp-03:$PWD
[root@hdp-01 hadoop]# vim mapred-site.xml # 通知框架MR使用YARN
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
[root@hdp-01 hadoop]# scp mapred-site.xml hdp-02:$PWD
[root@hdp-01 hadoop]# scp mapred-site.xml hdp-03:$PWD
# 启动yarn集群:start-yarn.sh (注:该命令应该在resourcemanager所在的机器上执行)
[root@hdp-01 hadoop-3.1.1]# ./sbin/start-yarn.sh
Starting resourcemanager
ERROR: Attempting to operate on yarn resourcemanager as root
ERROR: but there is no YARN_RESOURCEMANAGER_USER defined. Aborting operation.
Starting nodemanagers
ERROR: Attempting to operate on yarn nodemanager as root
ERROR: but there is no YARN_NODEMANAGER_USER defined. Aborting operation.
是因为缺少用户定义造成的,所以分别编辑开始和关闭脚本
$ vim sbin/start-yarn.sh
$ vim sbin/stop-yarn.sh
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
[root@hdp-01 sbin]# scp start-yarn.sh hdp-02:$PWD
[root@hdp-01 sbin]# scp start-yarn.sh hdp-03:$PWD
[root@hdp-01 sbin]# scp stop-yarn.sh hdp-02:$PWD
[root@hdp-01 sbin]# scp stop-yarn.sh hdp-03:$PWD
[root@hdp-01 hadoop-3.1.1]# ./sbin/start-yarn.sh
Starting resourcemanager
Last login: Tue Apr 9 13:29:23 CST 2019 from 192.168.120.1 on pts/1
Starting nodemanagers
Last login: Tue Apr 9 13:33:30 CST 2019 on pts/1
localhost: Warning: Permanently added 'localhost' (ECDSA) to the list of known hosts.
localhost: ERROR: JAVA_HOME is not set and could not be found.
[root@hdp-01 hadoop]# vim hadoop-env.sh # 指定JAVA_HOME
export JAVA_HOME=/opt/jdk1.8.0_121
[root@hdp-01 hadoop]# scp hadoop-env.sh hdp-02:$PWD
[root@hdp-01 hadoop]# scp hadoop-env.sh hdp-03:$PWD
[root@hdp-01 hadoop-3.1.1]# ./sbin/start-yarn.sh # 正常启动
Starting resourcemanager
Last login: Tue Apr 9 13:33:56 CST 2019 on pts/1
Starting nodemanagers
Last login: Tue Apr 9 13:42:34 CST 2019 on pts/1
[root@hdp-01 hadoop-3.1.1]#
[root@hdp-01 hadoop-3.1.1]# jps
26065 Jps
9218 NameNode
9346 DataNode
25591 ResourceManager
25916 NodeManager
# 分别在hdp-02、hdp-03节点启动YARN
[root@hdp-02 hadoop-3.1.1]# ./sbin/start-yarn.sh
[root@hdp-03 hadoop-3.1.1]# ./sbin/start-yarn.sh
- YARN正常启动,访问:192.168.120.61:8088