环境说明:Python 3
外部依赖:requests、bs4、BeautifulSoup
先看题目
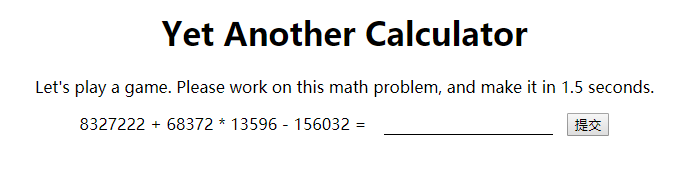
题目很简单,就是限时计算给出的算式并提交。
方法一、计算器一台。方法很简单只需要在1.5s内计算出结果再提交就行了,大约几千左右的APM就够了。
方法二、使用网络爬虫。
爬虫的话自然使用Python是最方便不过的,大体思路就是抓取公式->计算->提交。
既然是做题那么首先第一步肯定是化简,做题最讨厌的不是不会做而是把1+1做成∞+∞。我们先多刷新几次页面看一下。
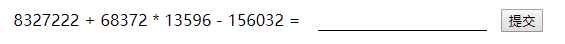
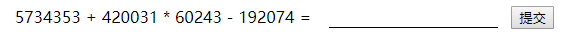
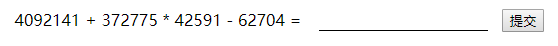
可以很明显看到公式采用的是x1+x2*x3-x4的固定格式。那这就简单多了,不需要判断运算符也不用修改运算顺序,直接省去了一个heap的工作量。再来看一下代码。

可以看到表单使用Get传值,传递对象是自己。GET使用URL传递参数,来测试一下URL。
提交前:

提交后:

可以看到answer的值被脚本通过URL捕获并显示相关内容。
现在的工作具体为抓取抓取公式->计算->生成URL->提交
先来完成前两步工作:
新建一个py文件,引入抓包用的requests和分析HTML结构的bs4.
import requests
from bs4 import BeautifulSoup
向指定页面发送GET请求并获取响应
response = requests.get("http://example.com/")
得到的response响应可以以content(二进制流)、text(文本)等多种格式输出,作为文本的时候还可以指定编码格式。
现以text格式输出一下看看结果。
print(response.text)

毫无疑问我们成功抓到了页面内容。下面需要获取公式。
soup = BeautifulSoup(response.text, "html.parser")
getString = soup.find(id="exp").string
Sum = int(getString.split()[2])
Sum *= int(getString.split()[4])
Sum += int(getString.split()[0])
Sum -= int(getString.split()[6])
先把获取的文本转成BeautifulSoup对象,通过字符串截取和强制转换变成单个数字并计算。由于已经确定运算符和运算规则这里就容易很多。然后把答案插入到URL并发送GET请求
response = requests.get("http://example.com/calculator/?answer=" + '%d' % Sum)
然后你会发现

提示问题页面还未建立,没有问题何来答案。
简述一下HTTP请求的规则:HTTP请求的三次握手
客户端向服务端发送syn=1,seq=client请求的ID;
服务端向客户端发送syn=1,seq=服务端请求的ID,ack=客户端请求的ID+1;
客户端向服务端发送syn=0,seq=客户端请求的ID+1,ack=服务端请求的ID+1,data\data…
所以简单来说就是HTTP向服务器发送请求时会有一个专属ID来让服务器和客户端保持连接,这个ID存在于cookies里面。如果不连同cookies发送给服务器,那么服务器就会认为是两个不同的客户发送的请求从而出现上面的错误。所以我们要做的是连同cookies一起发送。
先从response里面获取cookies并保存。
Cookies = response.cookies
修改二次请求
response = requests.get("http://example.com/?answer=" + '%d' % Sum, cookies=Cookies)
再来看一下结果

成功!
总结:这道题比较基础,简单的使用了Python的爬虫功能,主要是学习了HTTP请求的过程,关键在于cookies的传递。
后面打算写一篇关于POST传递的使用方式和详细的HTTP请求的相关知识