What is Apache Tez?
Apache Tez generalizes the MapReduce paradigm to execute a complex DAG (directed acyclic graph) of tasks. It also represents the next logical next step for Hadoop 2 and the introduction of with YARN and its more general-purpose resource management framework.
While MapReduce has served masterfully as the data processing backbone for Hadoop, its batch-oriented nature makes it unsuited for certain workloads like interactive query. Tez represents an alternate to the traditional MapReduce that allows for jobs to meet demands for fast response times and extreme throughput at petabyte scale. A great example of a benefactor of this new approach is Apache Hive and the work being done in theStinger Initiative
Motivation
Distributed data processing is the core application that Apache Hadoop is built around. Storing and analyzing large volumes and variety of data efficiently has been the cornerstone use case that has driven large scale adoption of Hadoop, and has resulted in creating enormous value for the Hadoop adopters. Over the years, while building and running data processing applications based on MapReduce, we have understood a lot about the strengths and weaknesses of this framework and how we would like to evolve the Hadoop data processing framework to meet the evolving needs of Hadoop users. As the Hadoop compute platform moves into its next phase with YARN, it has decoupled itself from MapReduce being the only application, and opened the opportunity to create a new data processing framework to meet the new challenges. Apache Tez aspires to live up to these lofty goals.
Key Design Themes
Higher-level data processing applications like Hive and Pig need an execution framework that can express their complex query logic in an efficient manner and then execute it with high performance. Apache Tez has been built around the following main design themes that solve these key challenges in the Hadoop data processing domain.
Ability to express, model and execute data processing logic
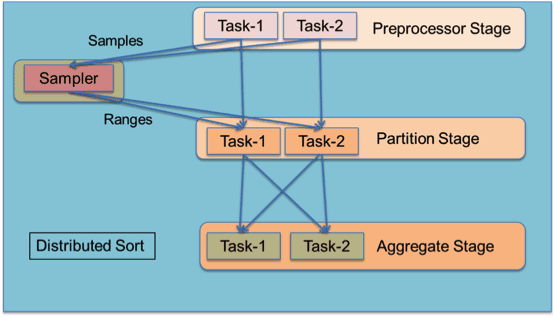 Tez models data processing as a dataflow graph with vertices in the graph representing application logic and edges representing movement of data. A rich dataflow definition API allows users to express complex query logic in an intuitive manner and it is a natural fit for query plans produced by higher-level declarative applications like Hive and Pig. As an example, the diagram shows how to model an ordered distributed sort using range partitioning. The Preprocessor stage sends samples to a Sampler that calculates sorted data ranges for each data partition such that the work is uniformly distributed. The ranges are sent to Partition and Aggregate stages that read their assigned ranges and perform the data scatter-gather. This dataflow pipeline can be expressed as a single Tez job that will run the entire computation. Expanding this logical graph into a physical graph of tasks and executing it is taken care of by Tez.
Tez models data processing as a dataflow graph with vertices in the graph representing application logic and edges representing movement of data. A rich dataflow definition API allows users to express complex query logic in an intuitive manner and it is a natural fit for query plans produced by higher-level declarative applications like Hive and Pig. As an example, the diagram shows how to model an ordered distributed sort using range partitioning. The Preprocessor stage sends samples to a Sampler that calculates sorted data ranges for each data partition such that the work is uniformly distributed. The ranges are sent to Partition and Aggregate stages that read their assigned ranges and perform the data scatter-gather. This dataflow pipeline can be expressed as a single Tez job that will run the entire computation. Expanding this logical graph into a physical graph of tasks and executing it is taken care of by Tez.
Flexible Input-Processor-Output task model
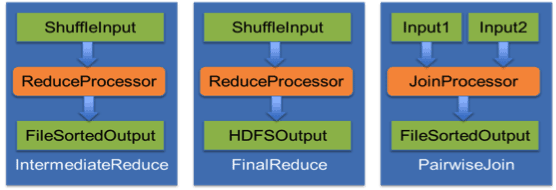 Tez models the user logic running in each vertex of the dataflow graph as a composition of Input, Processor and Output modules. Input & Output determine the data format and how and where it is read/written. Processor holds the data transformation logic. Tez does not impose any data format and only requires that a combination of Input, Processor and Output must be compatible with each other with respect to their formats when they are composed to instantiate a vertex task. Similarly, an Input and Output pair connecting two tasks should be compatible with each other. In the diagram, we can see how composing different Inputs, Outputs and Processors can produce different tasks.
Tez models the user logic running in each vertex of the dataflow graph as a composition of Input, Processor and Output modules. Input & Output determine the data format and how and where it is read/written. Processor holds the data transformation logic. Tez does not impose any data format and only requires that a combination of Input, Processor and Output must be compatible with each other with respect to their formats when they are composed to instantiate a vertex task. Similarly, an Input and Output pair connecting two tasks should be compatible with each other. In the diagram, we can see how composing different Inputs, Outputs and Processors can produce different tasks.
Performance via Dynamic Graph Reconfiguration
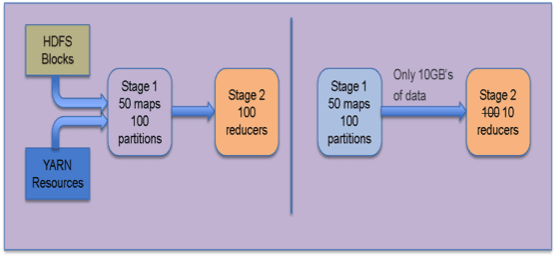 Distributed data processing is dynamic by nature and it is extremely difficult to statically determine optimal concurrency and data movement methods a priori. More information is available during runtime, like data samples and sizes, which may help optimize the execution plan further. We also recognize that Tez by itself cannot always have the smarts to perform these dynamic optimizations. The design of Tez includes support for pluggable vertex management modules to collect relevant information from tasks and change the dataflow graph at runtime to optimize for performance and resource usage. The diagram shows how Tez can determine an appropriate number of reducers in a MapReduce like job by observing the actual data output produced and the desired load per reduce task.
Distributed data processing is dynamic by nature and it is extremely difficult to statically determine optimal concurrency and data movement methods a priori. More information is available during runtime, like data samples and sizes, which may help optimize the execution plan further. We also recognize that Tez by itself cannot always have the smarts to perform these dynamic optimizations. The design of Tez includes support for pluggable vertex management modules to collect relevant information from tasks and change the dataflow graph at runtime to optimize for performance and resource usage. The diagram shows how Tez can determine an appropriate number of reducers in a MapReduce like job by observing the actual data output produced and the desired load per reduce task.
Performance via Optimal Resource Management
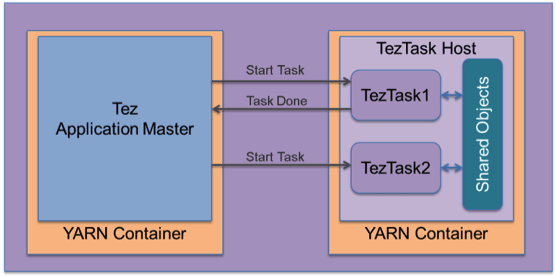 Resources acquisition in a distributed multi-tenant environment is based on cluster capacity, load and other quotas enforced by the resource management framework like YARN. Thus resource available to the user may vary over time and over different executions of the job. It becomes paramount to be able to efficiently use all available resources to run a job as fast as possible during one instance of execution and predictably over different instances of execution. The Tez execution engine framework allows for efficient acquisition of resources from YARN along with extensive reuse of every component in the pipeline such that no operation is duplicated unnecessarily. These efficiencies are exposed to user logic, where possible, such that users may also leverage this for efficient caching and avoid work duplication. The diagram shows how Tez runs multiple containers within the same YARN container host and how users can leverage that to store their own objects that may be shared across tasks.
Resources acquisition in a distributed multi-tenant environment is based on cluster capacity, load and other quotas enforced by the resource management framework like YARN. Thus resource available to the user may vary over time and over different executions of the job. It becomes paramount to be able to efficiently use all available resources to run a job as fast as possible during one instance of execution and predictably over different instances of execution. The Tez execution engine framework allows for efficient acquisition of resources from YARN along with extensive reuse of every component in the pipeline such that no operation is duplicated unnecessarily. These efficiencies are exposed to user logic, where possible, such that users may also leverage this for efficient caching and avoid work duplication. The diagram shows how Tez runs multiple containers within the same YARN container host and how users can leverage that to store their own objects that may be shared across tasks.
We hope this brief overview about the philosophy and design of Apache Tez will throw some light on the aspirations of the project and how we hope to work with the Apache Hadoop community to bring them to life. Apache Hive and Apache Pig projects have already show deep interest in integrating with Tez.
http://hortonworks.com/blog/apache-tez-a-new-chapter-in-hadoop-data-processing/