编码问题
字符编码:将字符映射到一个二进制字符串的过程,有各种映射规则,如最早的ASCII,国际通用的unicode等。
ASCII
存储统一码的低字节,每个字符占一个字节(8-1=7位)。
比如,"1"的统一码是0x0031,其ascii码是49。"2"的ascii码是是32,"a"的ascii码是97,"A"的ascii码是65。
文本文件写入字符“111”即写进3个49的二进制字符串,因为文件保存的是字符的编码。
后来发展为国际标准 ISO-646。
unicode编码 万国码(ISO-10646)
每个字符占用4个字节,对中文支持不太好。
utf-8编码
1 个汉字字符存储需要3个字节,1 个英文字符存储需要 1 个字节。
如“学”对应 “-27, -83, -90” ,而英文字母 “J” 对应 “74” 。
汉字对应的字节值为负数,原因在于每个字节是 8 位,最大值不能超过 127(2的8次方-1),而汉字转换为字节后超过 了127(用了第8位),会溢出,以负数的形式显示。
gbk 编码 中国的
1 个汉字字符存储需要 2 个字节,1 个英文字符存储需要 2 个字节。如“学”对应 “-47 -89” ,而英文字母 “J” 对应 “74” 。
GB2312中文系统浏览器都默认用它解码。修改为其他解码方式,参考下图:
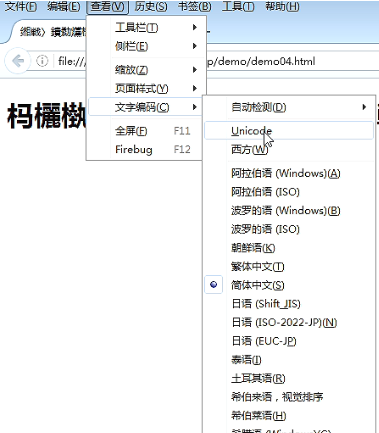
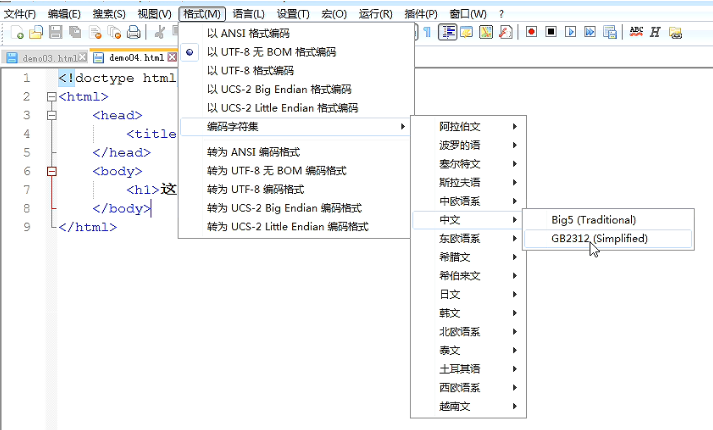
编辑器修改参考:
ansi编码:
智能编码
在中文机器上,直接创建时的编码方式是GB2312,如下图:

从其他地方考来的,可以自动识别。