一.简介
Pipeline管道计算模式:只是一种计算思想,在数据处理的整个流程中,就想水从管道流过一下,是顺序执行的。
二.特点
1.数据一直在管道中,只有在对RDD进行持久化【cache,persist...】或shuffle write时才会落地。
2.管道中的处理也是懒加载的,只有遇到action算子之后才会执行。
三.代码验证
package big.data.analyse.scala.pipeline import org.apache.log4j.{Level, Logger} import org.apache.spark.sql.SparkSession /** * Created by zhen on 2019/4/4. */ object RDDPipelineAnalyse { Logger.getLogger("org").setLevel(Level.INFO) // 设置日志级别 def main(args: Array[String]) { val spark = SparkSession.builder().appName("检测spark数据处理pipeline") .master("local[2]").getOrCreate() val sc = spark.sparkContext val rdd = sc.parallelize(Array(1,2,3,4,5,6)) println("rdd partition size : " + rdd.partitions.length) val rdd1 = rdd.map{ x => { println("map--------"+x) x * 10 }} val rdd2 = rdd1.filter{ x => { println("fliter========"+x) true } } rdd2.collect() sc.stop() } }
四.执行结果
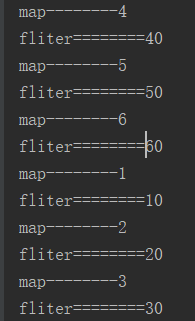
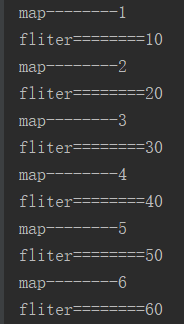
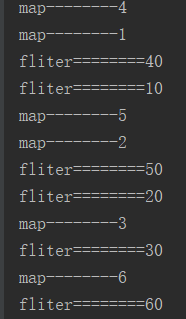
五.分析
管道处理是先进先出的,也就是先进先执行,这只对具体到每条数据而言,不同条数据的执行先后没有固定的顺序。
因此不能根据原始数据的顺序确定处理的顺序。