真实的处理过程,本来是公司内部分享用的,领导说这样写的得罪人、太扎眼,就写博客吧,木秀于林风必摧之。我懂。
上线过程中可能会遇到各种各样的问题,大多数的问题我们通过分析日志就可以得出结论,找到原因。
但是会出现一种问题我们很难通过日志找到原因:
系统刚上线各方面都很正常,但是由于某种操作触发或者运行一段时间之后出现接口卡顿,接口响应缓慢超时甚至假死等现象。
这种情况的出现大多伴随着系统硬件资源的使用率上升,如CPU和内存使用率突然急剧飙升,直接翻倍甚至占满硬件资源。
如果出现系统刚上线应用、接口表现正常,运行一段时间之后出现卡顿缓慢现象,而日志又没有表现出明显错误,或直接出现OOM,我们需要使用这种排查思路:
首先查看系统硬件资源使用情况,使用top命令可清晰查看,如图:

这是我们系统正常情况下 947 进程的使用情况,cpu使用率只有12.6 内存只有4.4,当系统出现问题的时候,我们再看系统的使用情况,如图:


26608与上图947为同一应用,发现cpu使用率直接飙升到100 % 内存使用情况翻倍,注意9.7是占用虚拟机的比例,但是我们单应用的jvm内存是不可以跟虚拟机的直接比较的,所以短时间内翻倍问题已经很大了。
这时候我们已经可以初步判定jvm的内存管理出现了问题,由于jvm的内存被不正常的对象大量抢占导致系统运行缓慢。
同时,我们数据中心的每台机器都是有zabbix监控(所有的数据中心都会有硬件资源监控系统,zabbix最为流行),我们同时可以提取zabbix的记录来做验证,如图我们举例一台:
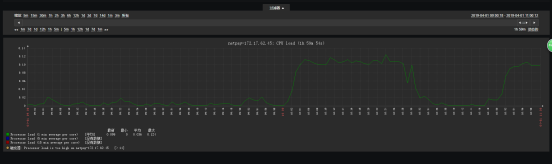
我们可以很清晰的看到在10点到10点12之间内存和CPU(有公司信息就不放了)的情况发生了急剧的增长,但是这和进入我们系统的流量不是正常的比例,由此我们可以断定我们的代码的jvm的内存管理出现了问题,即大概率出现了内存溢出。
关于内存溢出:大家肯定知道我们java应用的对象的创建是由我们管,但是回收大多数是由jvm通过一定的算法来实现的,如:最少使用、不可达、新生代的复制清除等等,也就是jvm会按照你现有对象占用的新生代或老年代的内存比例决定是否进行垃圾回收,每次垃圾回收都是需要STW的,但是当对象非正常产生的时候,jvm是回收不过来的,会造成不该有的对象直接占满、超过jvm设置大小,造成系统运行缓慢或者OOM。
如果出现了上述情况,我们必须、一定要保存dump文件!
因为dump是唯一可以反映java进程的内存情况的文件,也只有拿到当时的dump文件我们才可以分析出来造成我们本次上线的运行缓慢的原因,操作方式如图(测试环境):

1、执行 ps -ef | grep [应用名称] --获取 [pid]
2、执行 jmap -dump:format=b,file=website.dump [pid] 生成dump文件,生成时间可能较久
先拿到该应用的pid,然后借助于jdk的jmap工具获取dump文件。拿到dump文件之后就可以对应用的内存情况进行分析。
Dump文件需要借助特殊的工具进行分析,现在比较流行的是IBM Memory Analyzer和Eclipse Memory Analysis(MAT),我们用MAT来做演示。
这是我们系统运行正常时的截图,如图:
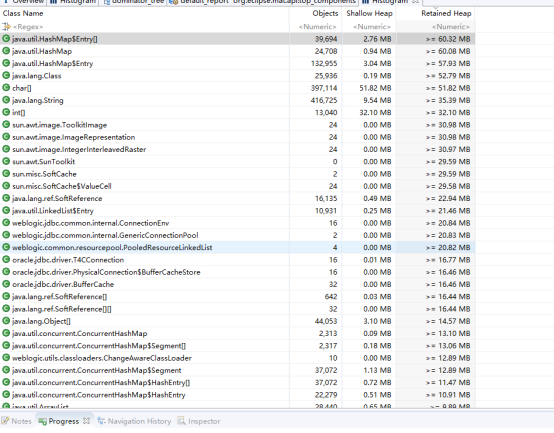
这是我们系统运行非正常的截图,如图:

在系统运行卡顿时,我们的char,String 的对象数量以及占用的内存空间发生了20倍的增长,同时我们自己的一个对象产生了202万个,Oracle的Driver对象也出现了不正常的增长,根据该对象的使用我们可以定位到问题出现的代码。
正常的应用千篇一律,有趣的问题万里挑一。