IDEA 创建scala spark的Mvn项目
1.创建一个简单的Mvn项目
1.1新建项目File -> new -> project -> Maven

1.2 点击下一步,填写gid和aid

1.3 点击下一步,点击完成

mvn项目就建好了

1.4 不要忘记你的Mvn配置(File -> Setting 搜索Maven)

2 添加依赖(配置要和你的环境一致)
<properties>
<scala.version>2.10.5</scala.version>
<hadoop.version>2.6.5</hadoop.version>
</properties>
<repositories>
<repository>
<id>scala-tools.org</id>
<name>Scala-Tools Maven2 Repository</name>
<url>http://scala-tools.org/repo-releases</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>1.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.10</artifactId>
<version>1.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.10</artifactId>
<version>1.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency>

3.添加Scala libraries
File -> Project Structure

选择对应的版本(第一次选择应该下载,不过下载很慢,建议去官网下载Scala,然后选择目录)

点击 OK

项目下就引入scala

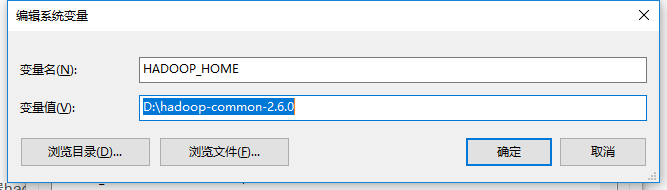
4. 配置hadoop,配置hadoop-common-2.6.0-bin,以免出现null/winutils
hadoop-common-2.6.0-bin下载:https://download.csdn.net/download/u014646662/10816318
配置环境变量:

5.可以写scala程序了

6 编写Scala类
package cn.com.tengen.test
import java.util.Scanner
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
class ScalaSparkContext(appName:String="Spark"){
val sc:SparkContext = getSparkContext()
def getSparkContext() = {
val conf = new SparkConf().setAppName(appName)
conf.setMaster("local")
val sc = new SparkContext(conf)
sc
}
def stop() = {
println("按回车键结束:")
val in = new Scanner(System.in)
in.nextLine()
sc.stop()
}
}
object ScalaSparkContext {
def main(args: Array[String]) {
val sparkContext = new ScalaSparkContext()
val sc = sparkContext.sc
val input = sc.textFile("F:\\stoke_data\\2018-10-08-09-32-44.txt").map(_.toLowerCase)
input
.flatMap(line => line.split("[,]"))
.map(word => (word, 1))
.reduceByKey((count1, count2) => count1 + count2)
.saveAsTextFile("aaaa")
sparkContext.stop()
}
}
运行后,在控制台中可以看到:
18/11/29 14:46:01 INFO Utils: Successfully started service 'SparkUI' on port 4040.
18/11/29 14:46:01 INFO SparkUI: Started SparkUI at http://172.16.66.1:4040
就进入web页面

注意:在sc.stop前可以访问