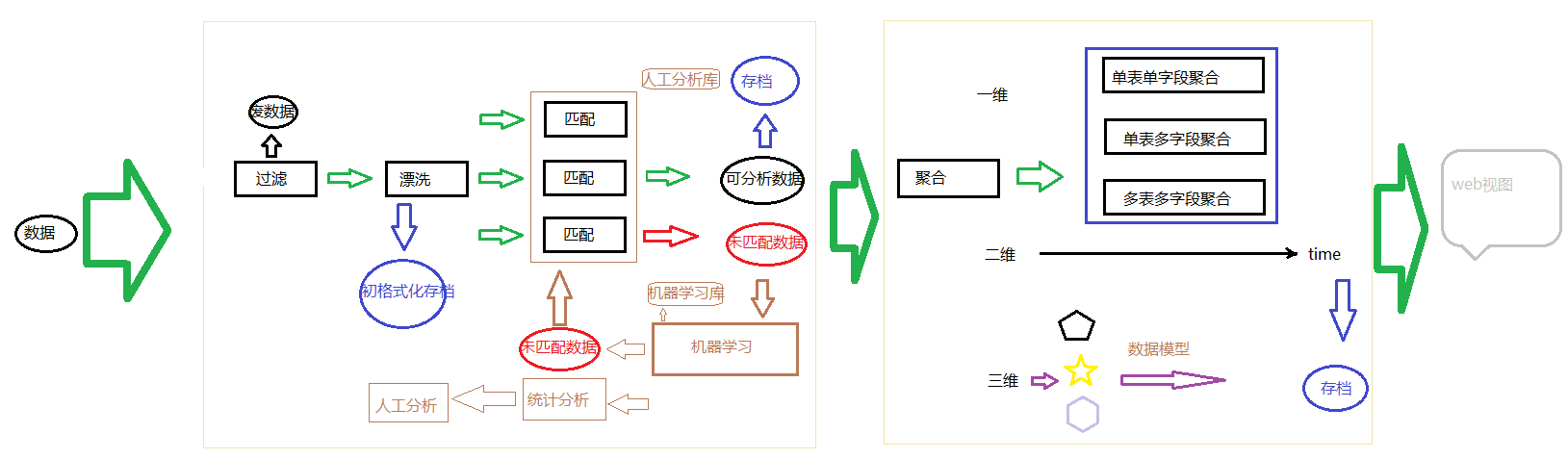
数据处理过程分为数据挖掘和数据分析,广义上说数据分析泛指整个过程,然而数据分析大的流程大致相同,如图:
数据挖掘一般都要经过过滤、漂洗、匹配三个过程:
1.过滤:主要将数据中的不适合分析的数据过滤掉,就好比产品流水线的残次品一样,对数据进行组粒度的过滤,其规则可按数据大小,字符长短;
2.漂洗:也称格式化,对数据进行分块,数据也有组成的,有时间、数据源、数据体等等,就好比头、身体、脚一样。将数据变成我们想要的格式,此过程也是打标签的过程,意将数据分类处理。
3.匹配:匹配就是抽取字段,将数据中的有用的地方抽取出来。(正则处理)由于数据的分类太多,无法完成所有的数据的匹配,这就需要机器自动识别。注意机器学习的结果并不精准,是故数据分开存储。
数据挖掘的过程也就是无格式数据和半格式化数据的格式化过程,换言之就是讲数据规则化。
数据挖掘过程结束后,就是数据分析阶段,其过程如图:

数据分析就是sql聚合操作,将数据格式化就是为了能够用sql语言去处理数据,换句话说就是,想怎么分析就怎么分析,只要你会操作数据库。
然而数据分析也有多层面的:按照维度划分为一维、二维、三维分析。
一维分析主要基于表查询,多个字段、单个字段、topN、分组等等的聚合函数
二维分析主要基于时间,为什么这么说呢,基于时间的分析就会复杂,多与预测有关系(预测那肯定不能人想,得机器想)
三维分析主要基于对象,对象怎么说,是将数据模型化,数据模型化就好比Java类一样,构造虚拟实体,基于实体的分析。
上述维度基于上一维度来说的。
有没有四维、五维,有木肯定有木,举个运维的例子:
例子:服务器运行情况
服务器A 2016-07-09 12:00:00 CPU:90% Mem:90%
应用程序A 2016-07-09 12:00:00 CPU:40% Mem:40% (men>60%才能正常运行)
应用程序B 2016-07-09 12:00:00 CPU:40% Mem:40% (men>30%才能正常运行)
服务器A系统 2016-07-09 12:00:00 CPU:10% Mem:10%
所以应用程序A就会运行不正常
整个数据处理流程的完整流程图: