super、多继承、mro(实质为c3)算法
mro即 method resolution order (方法解释顺序)
在新生类中多重继承使用新算法C3
mro即 method resolution order (方法解释顺序),主要用于在多继承时判断属性的路径(来自于哪个类)。(实质上是C3算法)
在新生类中有一个方法为 类名.mro() 用来查看类多继承时查找的顺序
在python2版本中,从python2.3开始引入了新生类与经典类的区别,在之前的版本中都只有一个经典类,基本思想是根据每个祖先类的继承结构,编译出一张列表,包括搜索到的类,按策略删除重复的(深度优先算法)。但是,在维护单调性方面失败过(顺序保存),所以从2.3版本,采用了新算法C3,解决python2.3以前版本的深度优先中重写无效问题以及python2.3版本中广度优先中的单调性问题。创建类时指定继承的类是object类是表示是新生类,不指定则表示是经典类。
python3中默认继承的是新生类。
为什么采用C3算法
C3算法最早被提出是用于Lisp的,应用在Python中是为了解决原来基于深度优先搜索算法不满足本地优先级,和单调性的问题。
本地优先级:指声明时父类的顺序,比如C(A,B),如果访问C类对象属性时,应该根据声明顺序,优先查找A类,然后再查找B类。
单调性:如果在C的解析顺序中,A排在B的前面,那么在C的所有子类里,也必须满足这个顺序。
C3算法
判断mro要先确定一个线性序列,然后查找路径由由序列中类的顺序决定。所以C3算法就是生成一个线性序列。
如果继承至一个基类:
class B(A)
这时B的mro序列为[B,A]
如果继承至多个基类
class B(A1,A2,A3 …)
这时B的mro序列 mro(B) = [B] + merge(mro(A1), mro(A2), mro(A3) …, [A1,A2,A3])
merge操作就是C3算法的核心。
遍历执行merge操作的序列,如果一个序列的第一个元素,是其他序列中的第一个元素,或不在其他序列出现,则从所有执行merge操作序列中删除这个元素,合并到当前的mro中。
merge操作后的序列,继续执行merge操作,直到merge操作的序列为空。
如果merge操作的序列无法为空,则说明不合法。
例子:
class A(O):pass
class B(O):pass
class C(O):pass
class E(A,B):pass
class F(B,C):pass
class G(E,F):pass
A、B、C都继承至一个基类,所以mro序列依次为[A,O]、[B,O]、[C,O]
mro(E) = [E] + merge(mro(A), mro(B), [A,B])
= [E] + merge([A,O], [B,O], [A,B])
执行merge操作的序列为[A,O]、[B,O]、[A,B]
A是序列[A,O]中的第一个元素,在序列[B,O]中不出现,在序列[A,B]中也是第一个元素,所以从执行merge操作的序列([A,O]、[B,O]、[A,B])中删除A,合并到当前mro,[E]中。
mro(E) = [E,A] + merge([O], [B,O], [B])
再执行merge操作,O是序列[O]中的第一个元素,但O在序列[B,O]中出现并且不是其中第一个元素。继续查看[B,O]的第一个元素B,B满足条件,所以从执行merge操作的序列中删除B,合并到[E, A]中。
mro(E) = [E,A,B] + merge([O], [O])
= [E,A,B,O]
实现C3算法代码
#-*- encoding:GBK -*-#
def mro_C3(*cls):
if len(cls)==1:
if not cls[0].__bases__:
return cls
else:
return cls+ mro_C3(*cls[0].__bases__)
else:
seqs = [list(mro_C3(C)) for C in cls ] +[list(cls)]
res = []
while True:
non_empty = list(filter(None, seqs))
if not non_empty:
return tuple(res)
for seq in non_empty:
candidate = seq[0]
not_head = [s for s in non_empty if candidate in s[1:]]
if not_head:
candidate = None
else:
break
if not candidate:
raise TypeError("inconsistent hierarchy, no C3 MRO is possible")
res.append(candidate)
for seq in non_empty:
if seq[0] == candidate:
del seq[0]
super
如果是在经典类中多继承时,查找方法和属性的规律是先查找此类中有没有,如果没有则查找父类继承的类中,如果继承的第一个类中所有继承的全都没有,则按照此方法在从左到右查找该类继承的类的所有的方法(只包含直接在该类中定义的,),以此类推到查找到为止,或者查找全部都没有报错。(深度搜索)
class P1:
def foo(self):
print 'p1-foo'
class P2:
def foo(self):
print 'p2-foo'
def bar(self):
print 'p2-bar'
class C1(P1, P2):
pass
class C2(P1, P2):
def bar(self):
print 'C2-bar'
class D(C1, C2):
pass
d = D()
d.foo() # 输出 p1-foo
d.bar() # 输出 p2-bar
实例d调用foo()时,搜索顺序是 D => C1 => P1
实例d调用bar()时,搜索顺序是 D => C1 => P1 => P2
经典类的搜索方式:从左到右,深度优先
以下主要新生类解决多继承问题
类的初始化函数也遵循下列方法
Python3中super()的参数传递
super([type[, object-or-type]])
super() 在使用时至少传递一个参数,且这个参数必须是一个类。
通过super()获取到的是一个代理对象,通过这个对象去查找父类或者兄弟类的方法。
1、super()不写参数的情况
class Base:
def __init__(self):
print('Base.__init__')
class A(Base):
def __init__(self):
super().__init__()
print('A.__init__')
class B(Base):
def __init__(self):
super().__init__()
print('B.__init__')
class C(Base):
def __init__(self):
super().__init__()
print('C.__init__')
class D(A, B, C):
def __init__(self):
super().__init__() # 等同于 super(D, self).__init__()
print('D.__init__')
D()
print(D.mro())
输出结果为:
Base.__init__
C.__init__
B.__init__
A.__init__
D.__init__
[<class '__main__.D'>, <class '__main__.A'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.Base'>, <class 'object'>]
super() 在一个定义的类中使用时,可以不写参数,Python会自动根据情况将两个参数传递给super。
在Python3中的类都是新式类,广度优先的查找顺序,在定义一个类时就会生成一个MRO列表(经典类没有MRO列表,深度优先),查找顺序就是按照这个列表中的类的顺序从左到右进行的。
2、super(type) 只传递一个参数的情况
class Base:
def __init__(self):
print('Base.__init__')
class A(Base):
def __init__(self):
super().__init__()
print('A.__init__')
class B(Base):
def __init__(self):
super().__init__()
print('B.__init__')
class C(Base):
def __init__(self):
super().__init__()
print('C.__init__')
class D(A, B, C):
def __init__(self):
super(B).__init__() # 值传递一个参数
print('D.__init__')
D()
print(D.mro())
结果为:
D.__init__
[<class '__main__.D'>, <class '__main__.A'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.Base'>, <class 'object'>]
其他方法都没有被调用。
super() 只传递一个参数时,是一个不绑定的对象,不绑定的话它的方法是不会有用的
3、super(type, obj) 传递一个类和一个对象的情况
class Base:
def __init__(self):
print('Base.__init__')
class A(Base):
def __init__(self):
super().__init__()
print('A.__init__')
class B(Base):
def __init__(self):
super().__init__()
print('B.__init__')
class C(Base):
def __init__(self):
super().__init__()
print('C.__init__')
class D(A, B, C):
def __init__(self):
super(B, self).__init__() # self是B的子类D的实例
print('D.__init__')
D()
print(D.mro())
输出结果为:
Base.__init__
C.__init__
D.__init__
[<class '__main__.D'>, <class '__main__.A'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.Base'>, <class 'object'>]
super() 的参数为一个类和一个对象的时候,得到的是一个绑定的super对象。但是obj必须是type的实例或者是子类的实例。
从结果可以看出,只是查找了B类之后的类的方法,
即super()是根据第二个参数(obj)来计算MRO,根据顺序查找第一个参数(类)之后的类的方法
4、super(type1, type2) 传递两个类的情况
class Base:
def __init__(self):
print('Base.__init__')
class A(Base):
def __init__(self):
super().__init__()
print('A.__init__')
class B(Base):
def __init__(self):
super().__init__()
print('B.__init__')
class C(Base):
def __init__(self):
super().__init__()
print('C.__init__')
class D(A, B, C):
def __init__(self):
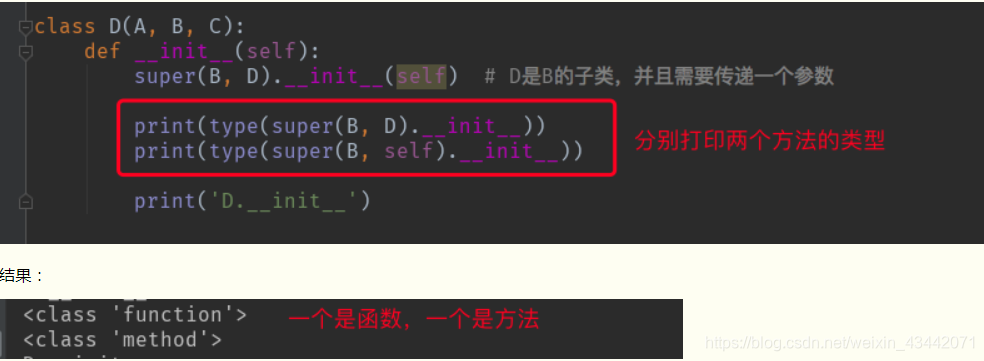
super(B, D).__init__(self) # D是B的子类,并且需要传递一个参数
print('D.__init__')
D()
print(D.mro())
输出结果为:
Base.__init__
C.__init__
D.__init__
[<class '__main__.D'>, <class '__main__.A'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.Base'>, <class 'object'>]
super()传递两个类type1和type2时,得到的也是一个绑定的super对象,但这需要type2是type1的子类,且如果调用的方法需要传递参数时,必须手动传入参数,因为super()第二个参数是类时,得到的方法是函数类型的,使用时不存在自动传参,第二个参数是对象时,得到的是绑定方法,可以自动传参。
以上内容有转载于借鉴于:
https://blog.csdn.net/longwen_zhi/article/details/80037161
https://blog.csdn.net/kaikai136412162/article/details/80856016
http://www.cnblogs.com/yanlin-10/p/10272338.html