不知道找工作怎么复习,不管面试了,一点一点开始学,首先从数据结构开始
学习内容:编程之法:面试和算法心得或The art of programming by July
>表小结或个人笔记
表示问题
文章目录
1. 程序员如何准备面试中的算法
…
一、第一部分 数据结构
1. 第一章 字符串
本章导读:
本章重点介绍6个经典的字符串问题:旋转字符串、字符串包含、字符串转成整数、回文判断、最长回文子串、字符串的全排列,这6个问题要么从暴力解法入手,然后逐步优化,要么多种思路多种解法。
读完本章后会发现,好的思路都是在充分考虑到问题本身的特征的前提下,或巧用合适的数据结构,或选择合适的算法降低时间复杂度( 避免不必要的操作),或选用效率更高的算法。
小结:
优化思路:1. 问题本身特征; 2. 合适的数据结构; 3. 合适的算法(避免不必要的操作); 4. 高效的算法
1.1 旋转字符串:(1). 一个一个旋转 (2). 反1反2反12
1.2 字符串包含:(1). 逐个比较查找 (2). 排序后查找 (3). 素数乘积判断(理论) (4). hashTable+位运算
1.3 字符串转换成整数:整数溢出( n > MAX_INT / 10 || n == MAX_INT/10 && c > MAX_INT % 10 )
1.4 回文判断:(1). 头尾向中间扫;(2). 中间向两边扫;(3). 单向链表判断回文
1.5 最长回文子串: (1). 中心向两边拓展; (2) Manacher算法
1.6 字符串的全排列: (1). 递归 (2). 字典序排列法(next_permutaion, 一找最后一个升序a[i], 二找比a[i]稍大的a[j], 三交换(i,j),四翻转(i+1)后部分)
1.1 旋转字符串
题目描述
给定一个字符串,要求把字符串前面的若干个字符移动到字符串的尾部,如把字符串“abcdef”前面的2个字符’a’和’b’移动到字符串的尾部,使得原字符串变成字符串“cdefab”。请写一个函数完成此功能,要求对长度为n的字符串操作的时间复杂度为 O(n),空间复杂度为 O(1)。
=====================================================================
分析与解法
解法一: 暴力位移法
思想: 把需要移动的字符串一个一个移动到字符串的尾部
void LeftShiftOne(char* s, int n)
{
char t = s[0];
for (int i = 1; i < n; i++){
s[i-1] = s[i];
}
s[n-1] = t;
}
void LeftRotateString(char* s, int n, int m)
{
while (m--){
LeftShiftOne(s, n);
}
}
针对长度为n的字符串,假设需移动m个字符,那么总共需要mn次操作,同时设立一个变量保存第一个字符
时间复杂度:O(mn),空间复杂度O(1)
解法二:三步反转法
思想:将一个字符串分成X和Y两个部分,在每部分字符串上定义反转操作,如XT即把X的所有字符反转(如,X=“abc”,那么XT=“cba”),那么就得到下面的结论:(XTYT)T=YX,显然就解决了字符串的反转问题。
例如,字符串 abcdef ,若要让def翻转到abc的前头,只要按照下述3个步骤操作即可:
- 首先将原字符串分为两个部分,即X:abc,Y:def;
- 将X反转,X->XT,即得:abc->cba;将Y反转,Y->YT,即得:def->fed。
- 反转上述步骤得到的结果字符串XTYT,即反转字符串cbafed的两部分(cba和fed)给予反转,cbafed得到defabc,形式化表示为(XTYT)T=YX,这就实现了整个反转。
如下图所示:

void ReverseString(char* s, int from, int to){
while ( from < to) {
char t = s[from];
s[from++] = s[to];
s[to--] = t;
}
}
void LeftRotateString(char* s, int n, int m){
m %= n; //若要左移动大于n位,那么和%n是等价的
ReverseString(s, 0, m-1);
ReverseString(s, m, n-1);
ReverseString(s, 0, n-1);
}
时间复杂度:O(n),空间复杂度O(1)
举一反三
1、 链表翻转。给出一个链表和一个数k,比如,链表为1→2→3→4→5→6,k=2,则翻转后2→1→6→5→4→3,若k=3,翻转后3→2→1→6→5→4,若k=4,翻转后4→3→2→1→6→5,用程序实现。
2、编写程序,在原字符串中把字符串尾部的m个字符移动到字符串的头部,要求:长度为n的字符串操作时间复杂度为O(n),空间复杂度为O(1)。 例如,原字符串为”Ilovebaofeng”,m=7,输出结果为:”baofengIlove”。
3、单词翻转。输入一个英文句子,翻转句子中单词的顺序,但单词内字符的顺序不变,句子中单词以空格符隔开。为简单起见,标点符号和普通字母一样处理。例如,输入“I am a student.”,则输出“student. a am I”。
1.2 字符串包含
题目描述
给定两个分别由字母组成的字符串A和字符串B,字符串B的长度比字符串A短。请问,如何最快地判断字符串B中所有字母是否都在字符串A里?
为了简单起见,我们规定输入的字符串只包含大写英文字母,请实现函数bool StringContains(string &A, string &B)
比如,如果是下面两个字符串:
String 1:ABCD
String 2:BAD
答案是true,即String2里的字母在String1里也都有,或者说String2是String1的真子集。
如果是下面两个字符串:
String 1:ABCD
String 2:BCE
答案是false,因为字符串String2里的E字母不在字符串String1里。
同时,如果string1:ABCD,string 2:AA,同样返回true。
==================================================================
分析与解法
解法一:逐个比较
思想:针对string2中每个字符,逐个与string1中每个字符比较
bool StringContain(string &a, string &b){
for (int i = 0; i < b.length(); ++i) {
int j;
for (j = 0; ( j < a.length()) && (a[j] != b[i]); ++j)
;
if ( j >= a.length())
return false;
}
return true;
}
假设string1长度为n,string2长度为m,则需要O(m*n)次操作。
解法二: 排序后扫描
如果允许排序的话,我们可以考虑下排序。
思想:比如可先对这两个字符串的字母进行排序,然后再同时对两个字串依次轮询。 两个字串的排序需要(常规情况)O(m log m) + O(n log n)次操作,之后的线性扫描需要O(m+n)次操作。
bool StringContain(string &a, string &b){
sort(a.begin(), a.end());
sort(b.begin(), b.end());
for (int pa = 0, pb = 0; pb < b.length();){
while ((pa < a.length()) && (a[pa] < b[pb]))
++pa;
if((pa >= a.length()) || (a[pa] > b[pb]))
return false;
//a[pa] == b[pb]
++pb;
}
return true;
}
解法三:素数乘积
思路总结如下:
- 按照从小到大的顺序,用26个素数分别与字符’A’到’Z’一一对应。
- 遍历长字符串,求得每个字符对应素数的乘积。
- 遍历短字符串,判断乘积能否被短字符串中的字符对应的素数整除。
- 输出结果。
如前所述,算法的时间复杂度为O(m+n) 的最好的情况为O(n)(遍历短的字符串的第一个数,与长字符串素数的乘积相除,即出现余数,便可退出程序,返回false),n为长字串的长度,空间复杂度为O(1)。
此种素数相乘的方法看似完美,但缺点是素数相乘的结果容易导致整数溢出。
//此方法只有理论意义,因为整数乘积很大,有溢出风险
bool StringContain(string &a,string &b)
{
const int p[26] = {2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 53, 59,61, 67, 71, 73, 79, 83, 89, 97, 101};
int f = 1;
for (int i = 0; i < a.length(); ++i)
{
int x = p[a[i] - 'A'];
if (f % x)
{
f *= x;
}
}
for (int i = 0; i < b.length(); ++i)
{
int x = p[b[i] - 'A'];
if (f % x)
{
return false;
}
}
return true;
}
易错:
for循环stringA时忘记去重,if (f % x) { f*=x;}
解法四:hashtable+位运算
思路:可以先把长字符串a中的所有字符都放入一个Hashtable里,然后轮询短字符串b,看短字符串b的每个字符是否都在Hashtable里,如果都存在,说明长字符串a包含短字符串b,否则,说明不包含。
再进一步,我们可以对字符串A,用位运算(26bit整数表示)计算出一个“签名”,再用B中的字符到A里面进行查找。
// “最好的方法”,时间复杂度O(n + m),空间复杂度O(1)
bool StringContain(string &a,string &b)
{
int hash = 0;
for (int i = 0; i < a.length(); ++i)
{
hash |= (1 << (a[i] - 'A'));
}
for (int i = 0; i < b.length(); ++i)
{
if ((hash & (1 << (b[i] - 'A'))) == 0)
{
return false;
}
}
return true;
}
这个方法的实质是用一个整数代替了hashtable,空间复杂度为O(1),时间复杂度还是O(n + m)。
举一反三
1、变位词
如果两个字符串的字符一样,但是顺序不一样,被认为是兄弟字符串,比如bad和adb即为兄弟字符串,现提供一个字符串,如何在字典中迅速找到它的兄弟字符串,请描述数据结构和查询过程。
1.3 字符串转换成整数
题目描述
输入一个由数字组成的字符串,把它转换成整数并输出。例如:输入字符串"123",输出整数123。
给定函数原型int StrToInt(const char *str) ,实现字符串转换成整数的功能,不能使用库函数atoi。
=============================================================
分析与解法
此题的基本思路便是:从左至右扫描字符串,把之前得到的数字乘以10,再加上当前字符表示的数字。
缺陷版本1
int StrToInt(const char *str)
{
int n = 0;
while (*str != 0)
{
int c = *str - '0';
n = n * 10 + c;
++str;
}
return n;
}
显然,上述代码忽略了以下细节:
- 空指针输入
- 正负符号
- 非法字符
- 整型溢出
溢出问题的处理
当发生溢出时,取最大或最小的int值。即大于正整数能表示的范围时返回MAX_INT:2147483647;小于负整数能表示的范围时返回MIN_INT:-2147483648。
而后,你可能会编写如下代码段处理溢出问题:
缺陷版本2
// sign:正负号;n:最终转换结果;c表示当前数字
//当发生正溢出时,返回INT_MAX
if ((sign == '+') && (c > MAX_INT - n * 10)){
n = MAX_INT;
break;
}
//发生负溢出时,返回INT_MIN
else if ((sign == '-') && (c - 1 > MAX_INT - n * 10)){
n = MIN_INT;
break;
}
但当上述代码转换" 10522545459"会出错,因为正常的话理应得到MAX_INT:2147483647,但程序运行结果将会是:1932610867。
为什么呢?因为当给定字符串" 10522545459"时,而MAX_INT是2147483647,即MAX_INT(2147483647) < n10(1052254545\10),所以当扫描到最后一个字符‘9’的时候,执行上面的这行代码:c > MAX_INT - n * 10 已无意义,因为此时(MAX_INT - n * 10)已经小于0,程序已经出错。
解决方法:
针对这种由于输入了一个很大的数字转换之后会超过能够表示的最大的整数而导致的溢出情况,我们有两种处理方式可以选择:
- 一个取巧的方式是把转换后返回的值n定义成long long,即long long n;
- 另外一种则是只比较n和MAX_INT / 10的大小,即:
- 若n > MAX_INT / 10,那么说明最后一步转换时,n*10必定大于MAX_INT,所以在得知n > MAX_INT / 10时,当即返回MAX_INT。
- 若n == MAX_INT / 10时,那么比较最后一个数字c跟MAX_INT % 10的大小,即如果n == MAX_INT / 10且c > MAX_INT % 10,则照样返回MAX_INT。
一直以来,我们努力的目的归根结底是为了更好的处理溢出,但上述第二种处理方式考虑到直接计算n 10 + c 可能会大于MAX_INT导致溢出,那么便两边同时除以10,只比较n和MAX_INT / 10的大小,从而巧妙的规避了计算n*10这一乘法步骤,转换成计算除法MAX_INT/10代替,不能不说此法颇妙。
如此我们可以写出正确的处理溢出的代码:
c = *str - '0';
if (sign > 0 && (n > MAX_INT / 10 || (n == MAX_INT / 10 && c > MAX_INT % 10))){
n = MAX_INT;
break;
}
else if (sign < 0 && (n > (unsigned)MIN_INT / 10 || (n == (unsigned)MIN_INT / 10 && c > (unsigned)MIN_INT % 10))){
n = MIN_INT;
break;
}
完整代码
int StrToInt(const char* str)
{
static const int MAX_INT = (int)((unsigned)~0 >> 1);
static const int MIN_INT = -(int)((unsigned)~0 >> 1) - 1;
unsigned int n = 0;
//判断是否输入为空
if (str == 0)
{
return 0;
}
//处理空格
while (isspace(*str))
++str;
//处理正负
int sign = 1;
if (*str == '+' || *str == '-')
{
if (*str == '-')
sign = -1;
++str;
}
//确定是数字后才执行循环
while (isdigit(*str))
{
//处理溢出
int c = *str - '0';
if (sign > 0 && (n > MAX_INT / 10 || (n == MAX_INT / 10 && c > MAX_INT % 10)))
{
n = MAX_INT;
break;
}
else if (sign < 0 && (n >(unsigned)MIN_INT / 10 || (n == (unsigned)MIN_INT / 10 && c > (unsigned)MIN_INT % 10)))
{
n = MIN_INT;
break;
}
//把之前得到的数字乘以10,再加上当前字符表示的数字。
n = n * 10 + c;
++str;
}
return sign > 0 ? n : -n;
}
举一反三
- 实现string到double的转换
分析:此题虽然类似于atoi函数,但毕竟double为64位,而且支持小数,因而边界条件更加严格,写代码时需要更加注意。
1.4 回文判断
题目描述
我们的第一个问题就是:判断一个字串是否是回文?
============================================================
分析与解法
解法一:头尾扫描
思想:从字符串头尾开始向中间扫描字串,如果所有字符都一样,那么这个字串就是一个回文
bool IsPalindrome(const char *s, int n)
{ // 非法输入
if (s == NULL || n < 1)
return false;
const char* front,*back;
// 初始化头指针和尾指针
front = s;
back = s+ n - 1;
while (front < back) {
if (*front != *back){
return false;
}
++front;
--back;
}
return true;
}
时间复杂度:O(n),空间复杂度:O(1)
解法二:中间向两边扫
思想:我们可以先从中间开始、然后向两边扩展查看字符是否相等。
bool IsPalindrome2(const char *s, int n){
if (s == NULL || n < 1)
return false;
const char* first, *second;
// m定位到字符串的中间位置
int m = ((n >> 1) - 1) >= 0 ? (n >> 1) - 1 : 0;
first = s + m;
second = s + n - 1 - m;
while (first >= s){
if (*first!= *second){
return false;
}
--first;
++second;
}
return true;
}
时间复杂度:O(n),空间复杂度:O(1)。
虽然本解法二的时空复杂度和解法一是一样的,但很快我们会看到,在某些回文问题里面,这个方法有着自己的独到之处,可以方便的解决一类问题。什么独到之处???
举一反三:单向链表是否回文
1、判断一条单向链表是不是“回文”
分析:对于单链表结构,可以用两个指针从两端或者中间遍历并判断对应字符是否相等。但这里的关键就是如何朝两个方向遍历。由于单链表是单向的,所以要向两个方向遍历的话,可以采取经典的快慢指针的方法,即先位到链表的中间位置,再将链表的后半逆置,最后用两个指针同时从链表头部和中间开始同时遍历并比较即可。
2、判断一个栈是不是“回文”
分析:对于栈的话,只需要将字符串全部压入栈,然后依次将各字符出栈,这样得到的就是原字符串的逆置串,分别和原字符串各个字符比较,就可以判断了。
1.5 最长回文子串
题目描述
给定一个字符串,求它的最长回文子串的长度。
分析与解法
最容易想到的办法是枚举所有的子串,分别判断其是否为回文。这个思路初看起来是正确的,但却做了很多无用功,如果一个长的子串包含另一个短一些的子串,那么对子串的回文判断其实是不需要的。
解法一: 中心拓展
如果一段字符串是回文,那么以某个字符为中心的前缀和后缀都是相同的,例如以一段回文串“aba”为例,以b为中心,它的前缀和后缀都是相同的,都是a。
思想:我们是否可以可以枚举中心位置,然后再在该位置上用扩展法,记录并更新得到的最长的回文长度呢?答案是肯定的
int LongestPalindrome(const char *s, int n){
int i, j, max,c;
if (s == 0 || n < 1)
return 0;
max = 0;
for (i = 0; i < n; ++i) { // i is the middle point of the palindrome
for (j = 0; (i - j >= 0) && (i + j < n); ++j){ // if the length of the palindrome is odd
if (s[i - j] != s[i + j])
break;
c = j * 2 + 1;
}
if (c > max)
max = c;
for (j = 0; (i - j >= 0) && (i + j + 1 < n); ++j){ // for the even case
if (s[i - j] != s[i + j + 1])
break;
c = j * 2 + 2;
}
if (c > max)
max = c;
}
return max;
}
代码稍微难懂一点的地方就是内层的两个 for 循环,它们分别对于以 i 为中心的,长度为奇数和偶数的两种情况,整个代码遍历中心位置 i 并以之扩展,找出最长的回文。
解法二、Manacher算法 O(N)
Manacher算法
参考:http://www.felix021.com/blog/read.php?2040 。
-
首先通过在每个字符的两边都插入一个特殊的符号,将所有可能的奇数或偶数长度的回文子串都转换成了奇数长度。比如 abba 变成 #a#b#b#a#, aba变成 #a#b#a#。
-
此外可以在字符串的开始加入另一个特殊字符,这样就不用特殊处理越界问题,比如$#a#b#a#。
以字符串12212321为例,插入#和$这两个特殊符号,变成了 S[] = “$#1#2#2#1#2#3#2#1#”,然后用一个数组 P[i] 来记录以字符S[i]为中心的最长回文子串向左或向右扩张的长度(包括S[i])。
比如S和P的对应关系:
-> S # 1 # 2 # 2 # 1 # 2 # 3 # 2 # 1 #
-> P 1 2 1 2 5 2 1 4 1 2 1 6 1 2 1 2 1
可以看出,P[i]-1正好是原字符串中最长回文串的总长度,为5。 -
如何计算P[i] - 1呢?
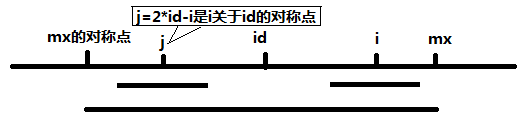
Manacher算法增加两个辅助变量id和mx,其中 id 为已知的 {右边界最大} 的回文子串的中心,mx则为id+P[id],也就是这个子串的右边界。然后可以得到一个非常神奇的结论,这个算法的关键点就在这里了:如果mx > i,那么P[i] >= MIN(P[2 * id - i], mx - i)。就是这个串卡了我非常久。实际上如果把它写得复杂一点,理解起来会简单很多:
//记j = 2 * id - i,也就是说 j 是 i 关于 id 的对称点(j = id - (i - id)) if (mx - i > P[j]) P[i] = P[j]; else /* P[j] >= mx - i */ P[i] = mx - i; // P[i] >= mx - i,取最小值,之后再匹配更新。
当 mx - i > P[j] 的时候,以S[j]为中心的回文子串包含在以S[id]为中心的回文子串中,由于 i 和 j 对称,以S[i]为中心的回文子串必然包含在以S[id]为中心的回文子串中,所以必有 P[i] = P[j],见下图。
当 P[j] >= mx - i 的时候,以S[j]为中心的回文子串不一定完全包含于以S[id]为中心的回文子串中,但是基于对称性可知,下图中两个绿框所包围的部分是相同的,也就是说以S[i]为中心的回文子串,其向右至少会扩张到mx的位置,也就是说 P[i] >= mx - i。至于mx之后的部分是否对称,就只能老老实实去匹配了。
对于 mx <= i 的情况,无法对 P[i]做更多的假设,只能P[i] = 1,然后再去匹配了。
于是代码如下:
//输入,并处理得到字符串s
int p[1000], mx = 0, id = 0;
memset(p, 0, sizeof(p));
for (i = 1; s[i] != '\0'; i++) {
p[i] = mx > i ? min(p[2*id-i], mx-i) : 1;
while (s[i + p[i]] == s[i - p[i]])
p[i]++;
if (i + p[i] > mx) {
mx = i + p[i];
id = i;
}
}
//找出p[i]中最大的
#UPDATE@2013-08-21 14:27
@zhengyuee 同学指出,由于 P[id] = mx,所以 S[id-mx] != S[id+mx],那么当 P[j] > mx - i 的时候,可以肯定 P[i] = mx - i ,不需要再继续匹配了。不过在具体实现的时候即使不考虑这一点,也只是多一次匹配(必然会fail),但是却要多加一个分支,所以上面的代码就不改了。
1.6 字符串的全排列
题目描述
输入一个字符串,打印出该字符串中字符的所有排列。
例如输入字符串abc,则输出由字符a、b、c 所能排列出来的所有字符串abc、acb、bac、bca、cab 和 cba。
分析与解法
解法一、递归实现
思想:从集合中依次选出每一个元素,作为排列的第一个元素,然后对剩余的元素进行全排列
void CalcAllPermutaion(cahr* perm, int from, int to){
if ( to <= 1)
return;
if ( from == to){
for (int i = 0; i <= to; ++i)
cout << perm[i];
cout << endl;
}else {
for (int j = from; j <= to; ++j){
swap(perm[j], perm[from];
CalcAllPermutaion(perm, from+1, to);
swap(perm[j], perm[from]);
}
}
}
解法二、字典序排列
-
那有没有这样的算法,使得
- 起点: 字典序最小的排列, 1-n , 例如12345
- 终点: 字典序最大的排列,n-1, 例如54321
- 过程: 从当前排列生成字典序刚好比它大的下一个排列
答案是肯定的:有,即是STL中的next_permutation算法。
-
下一个排列:假设(A)x(B)的下一个排列是(A)y(B’)
> A尽可能长
> y尽可能小
> B’中的字符按由小到大自增排列
如何找x和y呢?我们可以从左至右逐个扫描每个数,看哪个能增大(至于如何判定能增大,是根据如果一个数右面有比它大的数存在,那么这个数就能增大)增大到它右面比它大的那一系列数中最小的那个数. -
next_permutaion算法
- 定义
- 升序:相邻两个位置ai < ai + 1, ai称为该升序的首位
- 步骤(二找、一交换、一翻转)
- 找到排列中最后(最右) 一个升序的首位位置i,x = ai
- 找到排列中第i为右边最后一个比ai大的位置j,y = aj
- 交换x, y
- 把第(i + 1)位到最后的部分翻转
以21543为例,x = 1, y = 3, 交换得到23541,翻转得到23145
bool CalcAllPermutaion(char* perm, int num){ int i; for( i = num - 2; (i >=0) && (perm[i] >= perm[i+1]);--i){ ; } if (i < 0){ return false; } int k; for ( k = num - 1; (k > i) && (perm[k] <= perm[i]); --k) ; swap(perm[i], perm[k]); reverse(perm+i+1,perm+num); return true; }然后在主函数里循环判断和调用calcAllPermutation函数输出全排列即可.
- 定义
解法总结
由于全排列总共有n!种排列情况,所以不论解法一中的递归方法,还是上述解法二的字典序排列方法,这两种方法的时间复杂度都为O(n!)
类似问题
- 已知字符串里的字符是互不相同的,现在任意组合,比如ab,则输出aa,ab,ba,bb,编程按照字典序输出所有的组合。
分析:非简单的全排列问题(跟全排列的形式不同,abc全排列的话,只有6个不同的输出)。 本题可用递归的思想,设置一个变量表示已输出的个数,然后当个数达到字符串长度时,就输出。
//copyright@ 一直很安静 && World Gao
//假设str已经有序
void perm(char* result, char* str, int size, int resPos)
{
if (resPos == size)
printf("%s\n",result);
else{
for (int i = 0; i < size; ++i)
{
result[resPos] = str[i];
perm(result, str, size, resPos + 1);
}
}
}
-
如果不是求字符的所有排列,而是求字符的所有组合,应该怎么办呢?当输入的字符串中含有相同的字符串时,相同的字符交换位置是不同的排列,但是同一个组合。举个例子,如果输入abc,它的组合有a、b、c、ab、ac、bc、abc。
-
写一个程序,打印出一下的序列。
(a),(b),©,(d),(e)…(z)
(a,b),(a,c),(a,d),(a,e)…(a,z),(b,c),(b,d)…(b,z),(c,d)…(y,z)
(a,b,c),(a,b,d)…(a,b,z),(a,c,d)…(x,y,z)
…(a,b,c,d,…x,y,z)
1.7 本章字符串和链表的习题
https://wizardforcel.gitbooks.io/the-art-of-programming-by-july/content/01.10.html