在JDK集合框架中描述过,JDK存储一组Object的集合框架是Collection。而针对Collection框架的一组操作集合体是Collections,里面包含了多种针对Collection的操作,例如:排序、查找、交换、反转、复制等。
这一节讲述Collections的排序操作。
public static <T extends Comparable<? super T>> void sort(List list) {
list.sort(null);
}
Collections.sort方法调用的是List.sort方法,List.sort方法如下:
复制代码
@SuppressWarnings({“unchecked”, “rawtypes”})
default void sort(Comparator<? super E> c) {
Object[] a = this.toArray();
Arrays.sort(a, (Comparator) c); // Arrays的排序方法
ListIterator i = this.listIterator();
for (Object e : a) {
i.next();
i.set((E) e);
}
}
复制代码
看到这里可能会觉得奇怪,List是接口,但为什么会有实现方法,这是JDK 1.8的新特性。具体特性描述请参考:Java 8接口有default method后是不是可以放弃抽象类了?
在List.sort方法实现中,排序使用的是Arrays#sort(T[], java.util.Comparator<? super T>)方法,所以Collections的sort操作最终也是使用Arrays#sort(T[], java.util.Comparator<? super T>)方法。
复制代码
public static void sort(T[] a, Comparator<? super T> c) {
if (c == null) {
sort(a);
} else {
if (LegacyMergeSort.userRequested)
legacyMergeSort(a, c);
else
TimSort.sort(a, 0, a.length, c, null, 0, 0);
}
}
复制代码
Arrays#sort(T[], java.util.Comparator<? super T>)方法使用了3种排序算法:
java.util.Arrays#legacyMergeSort 归并排序,但可能会在新版本中废弃
java.util.ComparableTimSort#sort 不使用自定义比较器的TimSort
java.util.TimSort#sort 使用自定义比较器的TimSort
Arrays源码中有这么一段定义:
复制代码
/**
* Old merge sort implementation can be selected (for
* compatibility with broken comparators) using a system property.
* Cannot be a static boolean in the enclosing class due to
* circular dependencies. To be removed in a future release.
*/
static final class LegacyMergeSort {
private static final boolean userRequested =
java.security.AccessController.doPrivileged(
new sun.security.action.GetBooleanAction(
“java.util.Arrays.useLegacyMergeSort”)).booleanValue();
}
复制代码
该定义描述是否使用LegacyMergeSort,即历史归并排序算法,默认为false,即不使用。所以Arrays.sort只会使用java.util.ComparableTimSort#sort或java.util.TimSort#sort,这两种方法的实现逻辑是一样的,只是java.util.TimSort#sort可以使用自定义的Comparator,而java.util.ComparableTimSort#sort不使用Comparator而已。
顺便补充一下,Comparator是策略模式的一个完美又简洁的示例。总体来说,策略模式允许在程序执行时选择不同的算法。比如在排序时,传入不同的比较器(Comparator),就采用不同的算法。
Timsort算法
Timsort是结合了合并排序(merge sort)和插入排序(insertion sort)而得出的排序算法,它在现实中有很好的效率。Tim Peters在2002年设计了该算法并在Python中使用(TimSort 是 Python 中 list.sort 的默认实现)。该算法找到数据中已经排好序的块-分区,每一个分区叫一个run,然后按规则合并这些run。Pyhton自从2.3版以来一直采用Timsort算法排序,JDK 1.7开始也采用Timsort算法对数组排序。
Timsort的主要步骤:
判断数组的大小,小于32使用二分插入排序
复制代码
static void sort(Object[] a, int lo, int hi, Object[] work, int workBase, int workLen) {
// 检查lo,hi的的准确性
assert a != null && lo >= 0 && lo <= hi && hi <= a.length;
int nRemaining = hi - lo;
// 当长度为0或1时永远都是已经排序状态
if (nRemaining < 2)
return; // Arrays of size 0 and 1 are always sorted
// 数组个数小于32的时候
// If array is small, do a "mini-TimSort" with no merges
if (nRemaining < MIN_MERGE) {
// 找出连续升序的最大个数
int initRunLen = countRunAndMakeAscending(a, lo, hi);
// 二分插入排序
binarySort(a, lo, hi, lo + initRunLen);
return;
}
// 数组个数大于32的时候
......
复制代码
找出最大的递增或者递减的个数,如果递减,则此段数组严格反一下方向
复制代码
private static int countRunAndMakeAscending(Object[] a, int lo, int hi) {
assert lo < hi;
int runHi = lo + 1;
if (runHi == hi)
return 1;
// Find end of run, and reverse range if descending
if (((Comparable) a[runHi++]).compareTo(a[lo]) < 0) { // Descending 递减
while (runHi < hi && ((Comparable) a[runHi]).compareTo(a[runHi - 1]) < 0)
runHi++;
// 调整顺序
reverseRange(a, lo, runHi);
} else { // Ascending 递增
while (runHi < hi && ((Comparable) a[runHi]).compareTo(a[runHi - 1]) >= 0)
runHi++;
}
return runHi - lo;
}
复制代码
在使用二分查找位置,进行插入排序。start之前为全部递增数组,从start+1开始进行插入,插入位置使用二分法查找。最后根据移动的个数使用不同的移动方法。
复制代码
private static void binarySort(Object[] a, int lo, int hi, int start) {
assert lo <= start && start <= hi;
if (start == lo)
start++;
for ( ; start < hi; start++) {
Comparable pivot = (Comparable) a[start];
// Set left (and right) to the index where a[start] (pivot) belongs
int left = lo;
int right = start;
assert left <= right;
/*
* Invariants:
* pivot >= all in [lo, left).
* pivot < all in [right, start).
*/
while (left < right) {
int mid = (left + right) >>> 1;
if (pivot.compareTo(a[mid]) < 0)
right = mid;
else
left = mid + 1;
}
assert left == right;
/*
* The invariants still hold: pivot >= all in [lo, left) and
* pivot < all in [left, start), so pivot belongs at left. Note
* that if there are elements equal to pivot, left points to the
* first slot after them -- that's why this sort is stable.
* Slide elements over to make room for pivot.
*/
int n = start - left; // The number of elements to move 要移动的个数
// Switch is just an optimization for arraycopy in default case
// 移动的方法
switch (n) {
case 2: a[left + 2] = a[left + 1];
case 1: a[left + 1] = a[left];
break;
// native复制数组方法
default: System.arraycopy(a, left, a, left + 1, n);
}
a[left] = pivot;
}
}
复制代码
数组大小大于32时
数组大于32时, 先算出一个合适的大小,在将输入按其升序和降序特点进行了分区。排序的输入的单位不是一个个单独的数字,而是一个个的块-分区。其中每一个分区叫一个run。针对这些 run 序列,每次拿一个run出来按规则进行合并。每次合并会将两个run合并成一个 run。合并的结果保存到栈中。合并直到消耗掉所有的run,这时将栈上剩余的 run合并到只剩一个 run 为止。这时这个仅剩的 run 便是排好序的结果。
复制代码
static void sort(Object[] a, int lo, int hi, Object[] work, int workBase, int workLen) {
//数组个数小于32的时候
…
// 数组个数大于32的时候
/**
* March over the array once, left to right, finding natural runs,
* extending short natural runs to minRun elements, and merging runs
* to maintain stack invariant.
*/
ComparableTimSort ts = new ComparableTimSort(a, work, workBase, workLen);
// 计算run的长度
int minRun = minRunLength(nRemaining);
do {
// Identify next run
// 找出连续升序的最大个数
int runLen = countRunAndMakeAscending(a, lo, hi);
// If run is short, extend to min(minRun, nRemaining)
// 如果run长度小于规定的minRun长度,先进行二分插入排序
if (runLen < minRun) {
int force = nRemaining <= minRun ? nRemaining : minRun;
binarySort(a, lo, lo + force, lo + runLen);
runLen = force;
}
// Push run onto pending-run stack, and maybe merge
ts.pushRun(lo, runLen);
// 进行归并
ts.mergeCollapse();
// Advance to find next run
lo += runLen;
nRemaining -= runLen;
} while (nRemaining != 0);
// Merge all remaining runs to complete sort
assert lo == hi;
// 归并所有的run
ts.mergeForceCollapse();
assert ts.stackSize == 1;
}
复制代码
- 计算出run的最小的长度minRun
a) 如果数组大小为2的N次幂,则返回16(MIN_MERGE / 2);
b) 其他情况下,逐位向右位移(即除以2),直到找到介于16和32间的一个数;
复制代码
/**
* Returns the minimum acceptable run length for an array of the specified
* length. Natural runs shorter than this will be extended with
* {@link #binarySort}.
*
* Roughly speaking, the computation is:
*
* If n < MIN_MERGE, return n (it’s too small to bother with fancy stuff).
* Else if n is an exact power of 2, return MIN_MERGE/2.
* Else return an int k, MIN_MERGE/2 <= k <= MIN_MERGE, such that n/k
* is close to, but strictly less than, an exact power of 2.
*
* For the rationale, see listsort.txt.
*
* @param n the length of the array to be sorted
* @return the length of the minimum run to be merged
*/
private static int minRunLength(int n) {
assert n >= 0;
int r = 0; // Becomes 1 if any 1 bits are shifted off
while (n >= MIN_MERGE) {
r |= (n & 1);
n >>= 1;
}
return n + r;
}
复制代码
2. 求最小递增的长度,如果长度小于minRun,使用插入排序补充到minRun的个数,操作和小于32的个数是一样。
3. 用stack记录每个run的长度,当下面的条件其中一个成立时归并,直到数量不变:
runLen[i - 3] > runLen[i - 2] + runLen[i - 1]
runLen[i - 2] > runLen[i - 1]
复制代码
/**
* Examines the stack of runs waiting to be merged and merges adjacent runs
* until the stack invariants are reestablished:
*
* 1. runLen[i - 3] > runLen[i - 2] + runLen[i - 1]
* 2. runLen[i - 2] > runLen[i - 1]
*
* This method is called each time a new run is pushed onto the stack,
* so the invariants are guaranteed to hold for i < stackSize upon
* entry to the method.
*/
private void mergeCollapse() {
while (stackSize > 1) {
int n = stackSize - 2;
if (n > 0 && runLen[n-1] <= runLen[n] + runLen[n+1]) {
if (runLen[n - 1] < runLen[n + 1])
n–;
mergeAt(n);
} else if (runLen[n] <= runLen[n + 1]) {
mergeAt(n);
} else {
break; // Invariant is established
}
}
}
复制代码
关于归并方法和对一般的归并排序做出了简单的优化。假设两个 run 是 run1,run2 ,先用 gallopRight在 run1 里使用 binarySearch 查找run2 首元素 的位置k,那么 run1 中 k 前面的元素就是合并后最小的那些元素。然后,在run2 中查找run1 尾元素 的位置 len2,那么run2 中 len2 后面的那些元素就是合并后最大的那些元素。最后,根据len1 与len2 大小,调用mergeLo 或者 mergeHi 将剩余元素合并。
复制代码
/**
* Merges the two runs at stack indices i and i+1. Run i must be
* the penultimate or antepenultimate run on the stack. In other words,
* i must be equal to stackSize-2 or stackSize-3.
*
* @param i stack index of the first of the two runs to merge
*/
@SuppressWarnings(“unchecked”)
private void mergeAt(int i) {
assert stackSize >= 2;
assert i >= 0;
assert i == stackSize - 2 || i == stackSize - 3;
int base1 = runBase[i];
int len1 = runLen[i];
int base2 = runBase[i + 1];
int len2 = runLen[i + 1];
assert len1 > 0 && len2 > 0;
assert base1 + len1 == base2;
/*
* Record the length of the combined runs; if i is the 3rd-last
* run now, also slide over the last run (which isn't involved
* in this merge). The current run (i+1) goes away in any case.
*/
runLen[i] = len1 + len2;
if (i == stackSize - 3) {
runBase[i + 1] = runBase[i + 2];
runLen[i + 1] = runLen[i + 2];
}
stackSize--;
/*
* Find where the first element of run2 goes in run1. Prior elements
* in run1 can be ignored (because they're already in place).
*/
int k = gallopRight((Comparable<Object>) a[base2], a, base1, len1, 0);
assert k >= 0;
base1 += k;
len1 -= k;
if (len1 == 0)
return;
/*
* Find where the last element of run1 goes in run2. Subsequent elements
* in run2 can be ignored (because they're already in place).
*/
len2 = gallopLeft((Comparable<Object>) a[base1 + len1 - 1], a,
base2, len2, len2 - 1);
assert len2 >= 0;
if (len2 == 0)
return;
// Merge remaining runs, using tmp array with min(len1, len2) elements
if (len1 <= len2)
mergeLo(base1, len1, base2, len2);
else
mergeHi(base1, len1, base2, len2);
}
复制代码
4. 最后归并还有没有归并的run,知道run的数量为1。
Timsort介绍
Timsort是一种混合、稳定高效的排序算法,源自合并排序和插入排序,旨在很好地处理多种真实数据。它由Tim Peters于2002年实施使用在Python编程语言中。该算法查找已经排序的数据的子序列,并使用该知识更有效地对其余部分进行排序。这是通过将已识别的子序列(称为运行)与现有运行合并直到满足某些条件来完成的。从版本2.3开始,Timsort一直是Python的标准排序算法。如今,Timsort 已是是 Python、 Java、 Android平台 和 GNU Octave 的默认排序算法。
思想
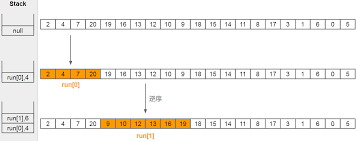
针对现实中需要排序的数据分析看,大多数据通常是有部分已经排好序的数据块,Timsort 就利用了这一特点。Timsort 称这些已经排好序的数据块为 “run”,我们可以将其视为一个一个的“分区”。在排序时,Timsort迭代数据元素,将其放到不同的 run 里,同时针对这些 run ,按规则进行合并至只剩一个,则这个仅剩的 run 即为排好序的结果。
换句话说,就是分析待排序数据,根据其本身的特点,将排序好的(不管是顺序还是逆序)子序列的分为一个个run分区,当然,这个分区run也存在一定的约束,即根据序列会产生一个minrun,如果原始的run小于minrun的长度,用插入排序扩充run,直到达到条件,之后使用归并排序来合并多个run。

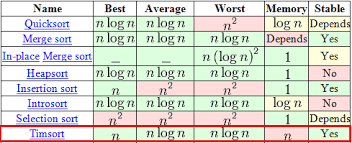
本质上 Timsort 是一个经过大量优化的归并排序,而归并排序已经到达了最坏情况下,比较排序算法时间复杂度的下界,所以在最坏的情况下,Timsort 时间复杂度为 O(nlogn) O(nlogn)O(nlogn)。在最佳情况下,即输入已经排好序,它则以线性时间运行O(n) O(n)O(n)。可以看出Timsort是目前最好的排序方式。
本质上 Timsort 是一个经过大量优化的归并排序,而归并排序已经到达了最坏情况下,比较排序算法时间复杂度的下界,所以在最坏的情况下,Timsort 时间复杂度为 O(nlogn) O(nlogn)O(nlogn)。在最佳情况下,即输入已经排好序,它则以线性时间运行O(n) O(n)O(n)。可以看出Timsort是目前最好的排序方式。
原文:https://blog.csdn.net/sinat_35678407/article/details/82974174