1.xsync集群分发脚本
首先确保集群配置了SSH免密登录。(详见5)
(a)在/home/atguigu目录下创建bin目录(/home/atguigu/bin),并在bin目录下xsync创建文件,文件内容如下:
[atguigu@hadoop102 ~]$ mkdir bin
[atguigu@hadoop102 ~]$ cd bin/
[atguigu@hadoop102 bin]$ touch xsync
[atguigu@hadoop102 bin]$ vi xsync
在该文件中编写如下代码
#!/bin/bash #1 获取输入参数个数,如果没有参数,直接退出 pcount=$# if((pcount==0)); then echo no args; exit; fi #2 获取文件名称 p1=$1 fname=`basename $p1` echo fname=$fname #3 获取上级目录到绝对路径 pdir=`cd -P $(dirname $p1); pwd` echo pdir=$pdir #4 获取当前用户名称 user=`whoami` #5 循环 for((host=103; host<105; host++)); do echo ------------------- hadoop$host -------------- rsync -rvl $pdir/$fname $user@hadoop$host:$pdir done
(b)修改脚本 xsync 具有执行权限
[atguigu@hadoop102 bin]$ chmod 777 xsync
(c)调用脚本形式:xsync 文件名称
[atguigu@hadoop102 bin]$ xsync /home/atguigu/bin
2设置启动集群(zookeeper hdfs yarn )
在/home/atguigu/bin创建start-cluster.sh,如果zookeeper不能启动,在zkEnv.sh加上

start-cluster.sh
#!/bin/bash user=`whoami` echo "=============== 开始启动所有节点服务 ===============" echo "=============== 正在启动Zookeeper...... ===============" for((host=102; host<=104; host++)); do echo "--------------- hadoop$host Zookeeper...... ----------------" ssh $user@hadoop$host '/opt/module/zookeeper-3.4.10/bin/zkServer.sh start' done echo "================ 正在启动HDFS ===============" ssh $user@hadoop102 '/opt/module/hadoop-2.7.2/sbin/start-dfs.sh' echo "================ 正在启动YARN ===============" ssh $user@hadoop103 '/opt/module/hadoop-2.7.2/sbin/start-yarn.sh' echo "================ hadoop102正在启动JobHistoryServer ===============" ssh $user@hadoop102 '/opt/module/hadoop-2.7.2/sbin/mr-jobhistory-daemon.sh start historyserver' done
(b)修改脚本 具有执行权限
[atguigu@hadoop102 bin]$ chmod 777 start-cluster.sh
3.关闭集群(zookeeper hdfs yarn )
在/home/atguigu/bin创建stop-cluster.sh
内容为
#!/bin/bash user=`whoami` echo "================ 开始停止所有节点服务 ===============" echo "================ hadoop102正在停止JobHistoryServer ===============" ssh $user@hadoop102 '/opt/module/hadoop-2.7.2/sbin/mr-jobhistory-daemon.sh stop historyserver' echo "================ 正在停止YARN ===============" ssh $user@hadoop103 '/opt/module/hadoop-2.7.2/sbin/stop-yarn.sh' echo "================ 正在停止HDFS ===============" ssh $user@hadoop102 '/opt/module/hadoop-2.7.2/sbin/stop-dfs.sh' echo "=============== 正在停止Zookeeper...... ===============" for((host=102; host<=104; host++)); do echo "--------------- hadoop$host Zookeeper...... ----------------" ssh $user@hadoop$host '/opt/module/zookeeper-3.4.10/bin/zkServer.sh stop' done
修改脚本 具有执行权限
[atguigu@hadoop102 bin]$ chmod 777 stop-cluster.sh
最后使用xsync 分发到其它集群上(切记要改变权限)
4.查看集群进程
在/home/atguigu/bin创建util.sh
内容为
#!/bin/bash for ip in hadoop102 hadoop103 hadoop104 do echo "------------------------------[ jps $ip ]-------------------------" ssh atguigu@$ip "source /etc/profile;jps" done
5.SSH免登录
无密钥配置
(1)免密登录原理,如图所示
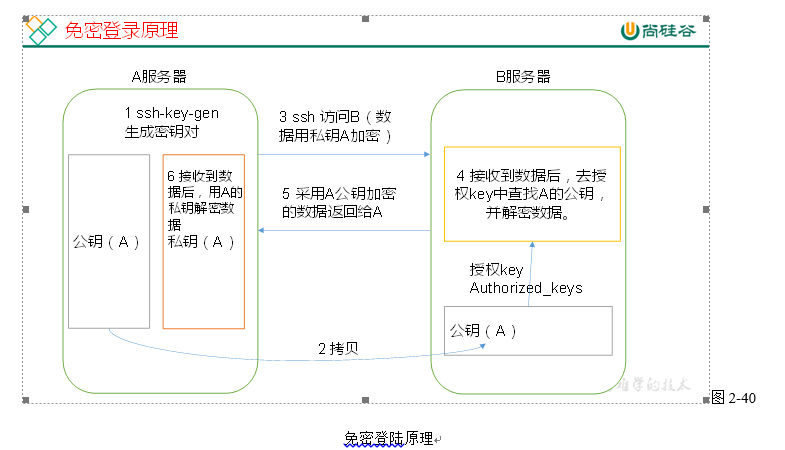
(2)生成公钥和私钥:
[atguigu@hadoop102 .ssh]$ ssh-keygen -t rsa
然后敲(三个回车),就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
(3)将公钥拷贝到要免密登录的目标机器上
[atguigu@hadoop102 .ssh]$ ssh-copy-id hadoop102
[atguigu@hadoop102 .ssh]$ ssh-copy-id hadoop103
[atguigu@hadoop102 .ssh]$ ssh-copy-id hadoop104
6.配置群起Zookeeper
在/home/用户名/bin下,创建zkstart.sh
#!/bin/bash user=`whoami` echo "=============== 正在启动Zookeeper...... ===============" for((host=102; host<=104; host++)); do echo "--------------- hadoop$host Zookeeper...... ----------------" ssh $user@hadoop$host '/opt/module/zookeeper-3.4.10/bin/zkServer.sh start' done
创建zkStop.sh
#!/bin/bash user=`whoami` echo "=============== 正在停止Zookeeper...... ===============" for((host=102; host<=104; host++)); do echo "--------------- hadoop$host Zookeeper...... ----------------" ssh $user@hadoop$host '/opt/module/zookeeper-3.4.10/bin/zkServer.sh stop' done
修改权限 chmod 777
7.配置kafka后台启动
在kafka目录下创建startkafka.sh
nohup bin/kafka-server-start.sh config/server.properties > kafka.log 2>&1 &
修改权限 chmod 777
./startkafka.sh 即可执行
只需要把startkafka.sh分发到各个机器,再独自启动即可
【注:
a. >kafka.log 将运行的日志写到kafka中, 2>&1 的意思就是将标准错误重定向到标准输出。
b. &:后台运行。当你只使用“&”时,关闭终端,进程会关闭。所以当你要让程序在后台不挂断运行时,需要将nohup和&一起使用。
c. 启动命令首位加上nohup,即使停掉crt,kafka、flume依然可以在后台执行,这样就不用每次登陆,重新运行启动命令了。如果需要停掉服务,只需运行 kill -9 [程序运行的号即可]
】