用到的知识点有:
1,二叉堆Heap的设计,实现堆排序
2,二叉树的链式构造
3,Huffman编码以及Huffman树的构建
4,二进制文件I/O流 的读写
5,比特输出流的类设计
程序目录:
1 /**设计一个Heap类 2 * 顺序存储结构,用数组线性表来建立 3 * 堆的性质:1,完全二叉树 4 * 2,根节点的值大于或等于左右孩子的值 5 * 用于堆排序 6 * 方法有: 7 * 1,增加一个新的节点 8 * 2,删除根节点 9 * 泛型程序设计 10 * E继承自Comparable接口 比较方法compareTo 11 */ 12 13 import java.util.ArrayList; 14 15 public class Heap<E extends Comparable<E>>{ 16 /**数组线性表用于存储堆中的元素 */ 17 private ArrayList<E> list = new ArrayList<>(); 18 /**构造一个空的二叉堆 */ 19 public Heap(){ 20 } 21 /**用指定的对象数组构造二叉堆 */ 22 public Heap(E[] objects){ 23 for(int i=0; i<objects.length; i++){ 24 add(objects[i]); 25 } 26 } 27 /**添加新的节点到堆中 */ 28 public void add(E e){ 29 /**将节点添加到堆末尾 */ 30 list.add(e); 31 32 /**重构堆 */ 33 int indexOfCurrent = list.size() - 1; 34 int indexOfParent; 35 /**当当前节点更新到根节点时退出循环 */ 36 while(indexOfCurrent > 0){ 37 /**得到父节点的下标 */ 38 indexOfParent = (indexOfCurrent -1 ) / 2; 39 40 if(list.get(indexOfCurrent).compareTo(list.get(indexOfParent)) > 0){ 41 /**将当前节点和父节点交换 */ 42 E temp = list.get(indexOfCurrent); 43 list.set(indexOfCurrent, list.get(indexOfParent)); 44 list.set(indexOfParent, temp); 45 } 46 else{ 47 break; //当当前节点小于等于父节点退出循环 48 } 49 /**更新当前节点的下标 */ 50 indexOfCurrent = indexOfParent; 51 } 52 } 53 /**删除根节点 并返回该值 */ 54 public E remove(){ 55 if(list.size() == 0) return null; 56 /**末尾元素赋值给根节点元素之后,删除堆的末尾元素 */ 57 E root = list.get(0);//暂存根节点的元素 58 list.set(0, list.get(list.size() - 1) ); 59 list.remove(list.size() - 1); 60 61 /**根节点为当前节点 */ 62 int indexOfCurrent = 0; 63 int indexOfSon; 64 65 /**重构二叉堆 当当前节点为叶节点时退出循环*/ 66 while(indexOfCurrent < list.size()){ 67 int indexOfLeft = indexOfCurrent*2 + 1; 68 int indexOfRight = indexOfCurrent*2 + 2; 69 70 /**选出左右孩子中较大的一个作为子节点 */ 71 if(indexOfLeft == list.size() - 1){ //只有左孩子 72 indexOfSon = indexOfLeft; 73 } 74 else if(indexOfLeft > list.size() - 1 ){ //无孩子 75 break; 76 } 77 else{ //有左右孩子 78 if(list.get(indexOfLeft).compareTo(list.get(indexOfRight)) > 0){ 79 indexOfSon = indexOfLeft; 80 } 81 else{ 82 indexOfSon = indexOfRight; 83 } 84 } 85 86 87 if(list.get(indexOfCurrent).compareTo(list.get(indexOfSon)) < 0){ 88 /**将当前节点和子节点交换 */ 89 E temp = list.get(indexOfSon); 90 list.set(indexOfSon, list.get(indexOfCurrent)); 91 list.set(indexOfCurrent, temp ); 92 } 93 else{ 94 break;//当前节点大于等于子节点退出循环 95 } 96 /**更新当前节点的下标 */ 97 indexOfCurrent = indexOfSon; 98 } 99 100 return root; 101 } 102 /**返回堆的大小 */ 103 public int getSize(){ 104 return list.size(); 105 } 106 }
1 /** 2 * 实现一个BitOutputStream类 3 * 作用:能将比特流写入到输出流当中 4 */ 5 6 import java.io.*; 7 8 class BitOutputStream{ 9 private FileOutputStream output; 10 private int value = 0; 11 private int mask = 1; 12 private int count = 0; //标记填充比特的个数 13 /**构造方法 */ 14 public BitOutputStream(File file)throws IOException{ 15 output = new FileOutputStream(file); 16 } 17 /**存储一个字节变量形式的比特 18 * 每次只能写入一个字节的数据 19 * 所以每存满一个字节的比特,就写入 20 */ 21 public void writeBit(char bit)throws IOException{ 22 count ++; 23 value = value << 1; 24 if(bit == '1'){ 25 value = value | mask; 26 } 27 if(count == 8){ 28 output.write(value); 29 count = 0; //在写入一个字节后 填充比特数置为0 30 } 31 } 32 /**调用writeBit(char bit)字符串划分成单个字符 */ 33 public void writeBit(String bit)throws IOException{ 34 for(int i=0; i<bit.length(); i++){ 35 writeBit(bit.charAt(i)); 36 } 37 } 38 /**最后的字节既未填满也未空 必须调用close()写入剩余比特流 */ 39 public void close()throws IOException{ 40 if(count > 0){ 41 value = value << (8 - count); 42 output.write(value);//写入低位一个字节 43 } 44 output.close(); 45 } 46 }
1 /**定义内部类Tree用于构建Huffman树 2 * 要求实现能通过权重比较树的大小 3 * 实现Comparable接口 4 * 改写compareTo方法 5 */ 6 public class Tree implements Comparable<Tree>{ 7 Node root; 8 /**构造方法 */ 9 public Tree(int weight, char element){ //单个节点的树 10 root = new Node(weight, element); 11 } 12 public Tree(Tree t1,Tree t2){ //两个子树合并成一个树 13 root = new Node(); //空的根节点 14 root.left = t1.root; //连接子树 15 root.right = t2.root; 16 root.weight = t1.root.weight + t2.root.weight; //权重相加 17 } 18 /**改写compareTo方法 19 * 比较树根节点的权值 20 */ 21 @Override 22 public int compareTo(Tree t){ 23 if(root.weight < t.root.weight) return 1; 24 else if(root.weight == t.root.weight) return 0; 25 else return -1; 26 } 27 28 /**定义Tree的内部类Node 29 * 用于定义树的节点 30 */ 31 class Node{ 32 char element; //存储叶节点的字符 33 int weight; //该字符的权重 34 Node left; //左子树 35 Node right; //右子树 36 String code = ""; //该字符的编码 37 38 public Node(){ 39 } 40 public Node(int weight,char element){ 41 this.weight = weight; 42 this.element = element; 43 } 44 } 45 }
1 /** 2 * 实现一个压缩文件的类:Compress 3 */ 4 5 import java.io.*; 6 7 public class Compress{ 8 private int[] counts = new int[256]; 9 private String[] codes = new String[256]; 10 private Tree huffmanTree= new Tree(); 11 12 public Compress(){} 13 14 /**获得文件每个字符的权重 */ 15 public void setCharacterFrequency(String str)throws IOException { 16 File file = new File(str); 17 FileInputStream input = new FileInputStream(file); 18 int r; 19 while((r = input.read()) != -1){ 20 counts[r]++; 21 } 22 input.close(); 23 } 24 /**构造哈夫曼树 */ 25 public void setHuffmanTree(){ 26 Heap<Tree> heap = new Heap<>(); 27 28 for(int i=0; i<256; i++){ 29 if(counts[i]!=0){ 30 heap.add(new Tree(counts[i],(char)i)); 31 } 32 } 33 while(heap.getSize() > 1){ 34 Tree t1 = heap.remove(); 35 Tree t2 = heap.remove(); 36 heap.add(new Tree(t1,t2)); 37 } 38 huffmanTree = heap.remove(); 39 } 40 /**得到哈夫曼编码 */ 41 public void setCode(){ 42 if(huffmanTree.root == null)return; 43 assignCode(huffmanTree.root); 44 } 45 public void assignCode(Tree.Node root){ 46 if(root.left != null){ 47 root.left.code = root.code + "0"; 48 assignCode(root.left); 49 50 root.right.code = root.code + "1"; 51 assignCode(root.right); 52 } 53 else{ 54 codes[(int)root.element] = root.code; 55 } 56 } 57 /**==============压缩文件============= */ 58 public void compress(String str1,String str2)throws IOException{ 59 File file1 = new File(str1);//源文件 60 File file2 = new File(str2);//目标文件 61 FileInputStream input = new FileInputStream(file1); 62 BitOutputStream output = new BitOutputStream(file2); 63 int r; //ASCII码 64 while((r = input.read()) != -1){ 65 output.writeBit(codes[r]); 66 } 67 input.close(); 68 output.close(); 69 } 70 }
1 /**测试Compress类**/ 2 3 import java.io.IOException; 4 5 public class TestCompress{ 6 public static void main(String[] args) throws IOException { 7 //创建压缩对象 8 Compress myCompress = new Compress(); 9 //统计字符出现次数 10 myCompress.setCharacterFrequency("C:/Users/Administrator/Desktop/testHuffman.txt"); 11 //构造哈夫曼树 12 myCompress.setHuffmanTree(); 13 //得到哈夫曼编码 14 myCompress.setCode(); 15 //压缩文件 16 myCompress.compress("C:/Users/Administrator/Desktop/testHuffman.txt", 17 "C:/Users/Administrator/Desktop/testHuffman.zip"); 18 } 19 }
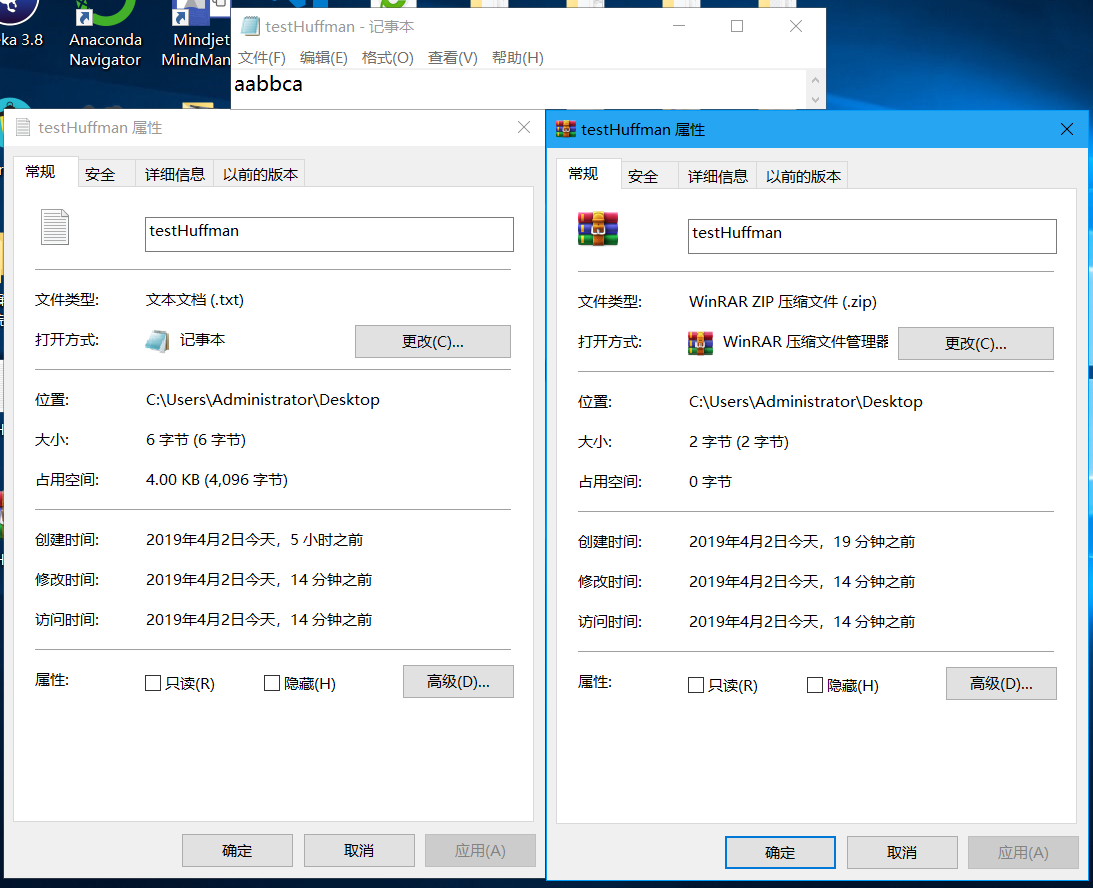
接下来我测试了压缩更大的文件
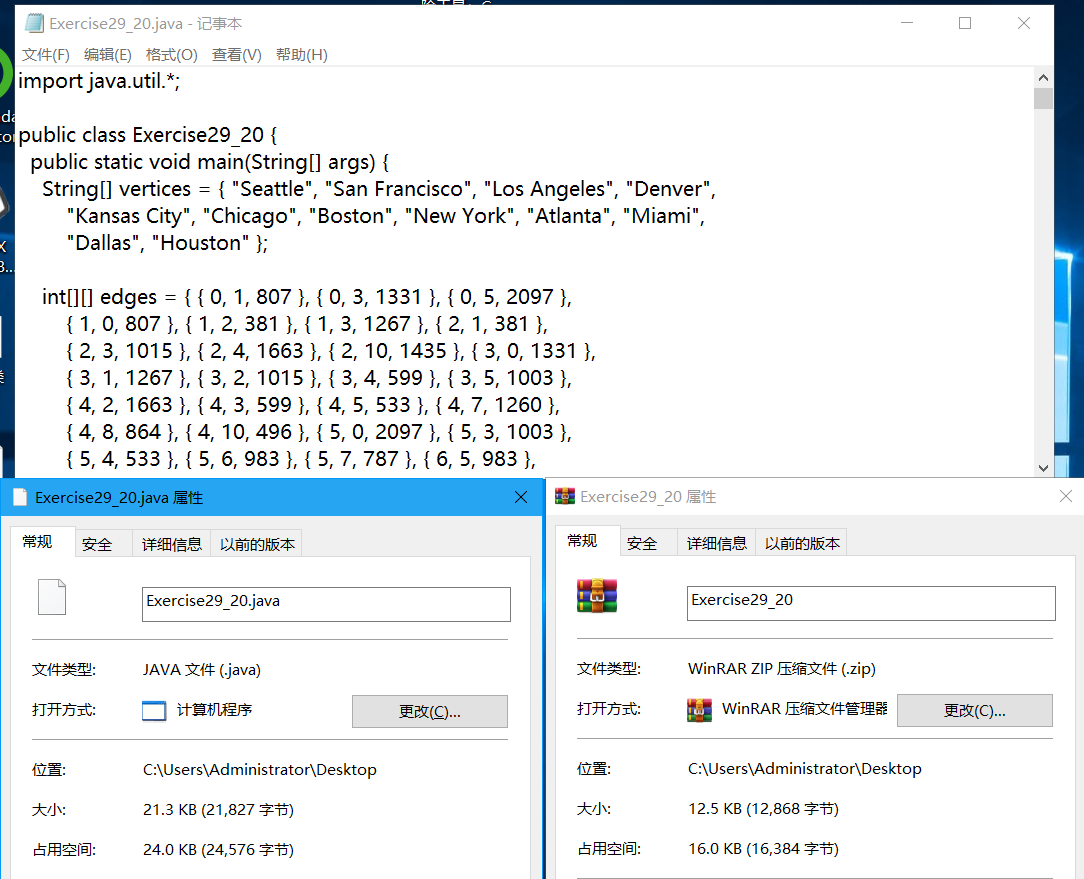
我们可以看到,压缩效率实际上由文件中字符重复出现的频率所决定

但不得不说,学完了数据结构的二叉树、哈夫曼树,算法的堆排序,java语言程序设计的二进制文件输入输出流之后就可以做一个压缩文件的小项目,不得不说很有意思!
后续会出相应的解压缩程序。