时间序列数据库,简称时序数据库,Time Series Database,一个全新的领域,最大的特点就是每个条数据都带有Time列。
时序数据库到底能用到什么业务场景,答案是:监控系统。
Baidu一下,互联网监控系统,大家会发现小米、饿了吗等互联网巨头都在用时序数据库实现企业级的互联网监控系统。
很多人会说,用Zabbix不就搞定了,其实不是这样的,简单的主机资源监控、网络监控、小规模的部署环境,Zabbix能搞定。
如果在IDC 上千台服务器环境下,分布式应用架构、各种中间件,这种情况下我们要监控上千台服务的主机资源、网络、按不同纬度监控服务的性能、TPS,监控各类中间件,程序监控埋点。Zabbix就无法
满足需要了。此时,我们要独立搭建自己的监控体系了。说到这,每一个监控图表的背后,都有什么?
1. 时间轴
2. 数据值(不同指标纬度)
例如,一段时间内CPU使用率
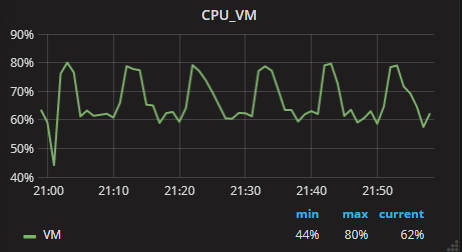
这时,各种Google、Baidu之后,你肯定会搜索到Influxdb、OpenTSDB等时序数据库。
Influxdb我们研究了很长的时间,准备用2篇文章,推荐给大家,本文中,我们分享一下Influxdb的关键特性、查询语法和使用场景。
一、Influxdb关键特性
1. 支持类似SQL的查询语法
2.提供了Http Api直接访问
3.存储超过10亿级别的时间序列数据
4.灵活的数据保留策略,可以定义到Database级别(只保留最热的数据)
5.内置管理接口和CMD
6.飞一般速度的聚合查询
7.按不同时间段进行聚合查询
8.内置持续查询功能,定时计算指定时间段的数据,插入到指定表中,可以理解为定时归集数据
9. 水平扩展,支持集群模式
二、Influxdb 版本和.Net支持
1. 根据我们的使用经验,V0.10版本是非常稳定的,V0.9.6我们用过,有内存泄漏问题
2. GitHub上有非常多的.Net Libraby,方便我们写入和读取数据

三、数据写入Write Data(Points)
Http API:
curl -i -XPOST 'http://localhost:8086/write?db=mydb' --data-binary 'cpu_load,host=server01,region=us-west value=0.64 1434055562000000000‘
db:mydb, 要写入的数据库
measurement:cpu_load,表
tag keys:host region tag value:server01 us-west
tag标签可以理解为维度,可选参数,用于标识不同的数据源,基于tag使查询更加简单和高效
Tags are indexed so queries on tag keys or tag values are more performant than queries on fields.
key field:value value field:0.64
Timestamp:1434055562000000000 可选参数、UTC
支持批量写入
支持同一个Timestamp写入不同的数据
Influxdb 支持存储结构灵活变化,可以在任意增加measure、tags、fields,但是每个tag、field的数据类型必须固定。
四、查询Query
Http API:
curl -G 'http://localhost:8086/query?pretty=true' --data-urlencode "db=mydb" --data-urlencode "q=SELECT value FROM cpu_load_short WHERE region='us-west‘
返回JSON格式数据
支持同时多个Query SQL
查询最大返回10000个点的数据,如果超过阈值,可以设置chunk_size
Measurement、Tag、Field、数据等大小写敏感,SQL关键字不区分大小写
支持算术计算:
SELECT (water_level * 2) + 4 from h2o_feet
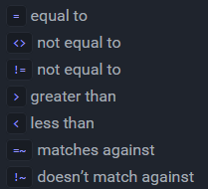
支持对Tags进行过滤查询,条件必须使用单引号
SELECT water_level FROM h2o_feet WHERE location = 'santa_monica'
Tag value 为空、不为空过滤
SELECT * FROM h2o_feet WHERE location !~ /.*/
SELECT * FROM h2o_feet WHERE location =~ /.*/
时间范围过滤
SELECT * FROM h2o_feet WHERE time > now() - 7d
Field value过滤
SELECT * FROM h2o_feet WHERE location = 'coyote_creek' AND water_level > 8
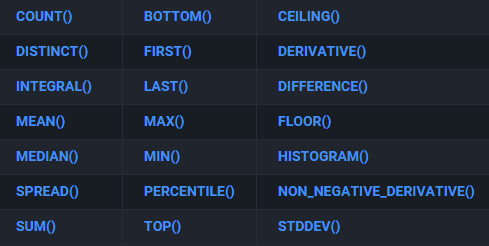
聚合函数、选择函数、转换函数
五、持续查询(Continuous Queries)
持续查询是Influxdb自动、周期的运行的查询,结果自动存储
设计持续查询的目的是为了规则采样数据,比如按天、按月采样数据
CREATE CONTINUOUS QUERY <cq_name> ON <database_name> [RESAMPLE [EVERY <interval>] [FOR <interval>]] BEGIN SELECT <function>(<stuff>)[,<function>(<stuff>)] INTO <different_measurement> FROM <current_measurement> [WHERE <stuff>] GROUP BY time(<interval>)[,<stuff>] END

六、 监控应用场景
通过上面几个部分的介绍,Influxdb的基本语法就可以掌握了。有什么作用:
1. 实时采集监控数据,按时间写入Influxdb
2. 按不同纬度聚合查询监控数据,用于监控展现
3. 持续查询,定时归集指定时间的数据,用于更大时间范围监控数据的展现
总结一下,场景结合实践,通过实际监控系统的应用,和大家分享了Influxdb的使用和技能。我们自己的监控系统就是通过这个套路一点点搭建起来的。
目前,我们的监控平台,2500个监控项,500台服务器实时监控,每日处理上T数据,几百个监控图表,Influxdb满足了我们日常超大规模监控的需要。
同时,Influxdb在大数据展现领域,也有不俗的表现,Druid的集成也很棒的
https://www.cnblogs.com/tianqing/p/7152940.html
...............................................................................................................
一、环境准备
- 同一网段内,3个CentOS 节点,相互可以ping通
- 3个节点CentOS配置Hosts文件,相互可以解析主机名
- Azure 虚拟机启用root用户
- influxdb-0.10.3-1.x86_64.rpm
- 设置端口8083 8086 8088 8091例外
二、一步一步搭建Influxdb集群
1. 在各个节点的主机上配置Hosts文件,这样可以保证每个节点直接的互相通讯

2. 各个节点主机安装InfluxDB rpm,只是安装不启动Influxdb

3. 三个节点主机上依次 编辑Influxdb.conf文件(.etc/influxdb/influxdb.conf)
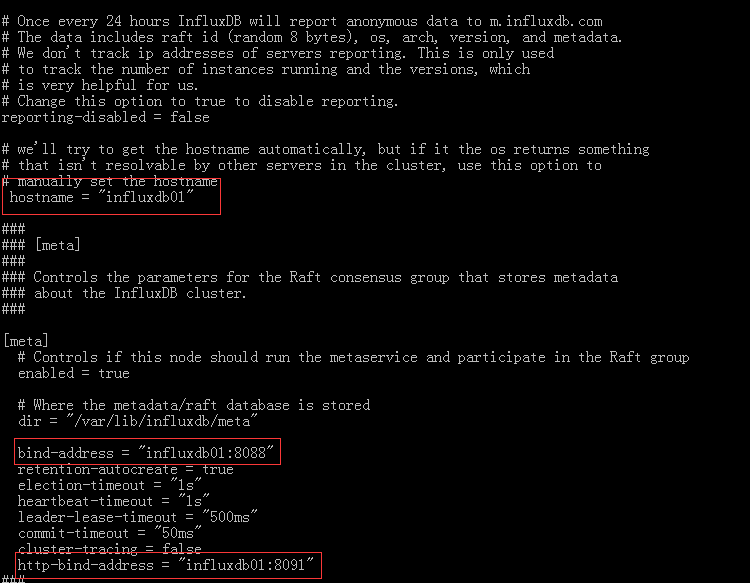
主要修改HostName、bind-address、http-bind-address三个选项
依次修改三个主机节点的配置文件
4. InfluxDB01机器上启动Influxdb
[root@influxdb01 influxdb]# sudo service influxdb start
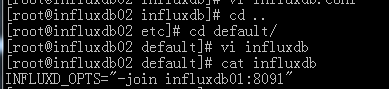
5. InfluxDB02上配置/etc/default/influxdb文件
加入influxdb01节点
INFLUXD_OPTS="-join influxdb01:8091"
6. InfluxDB02机器启动InfluxDB
[root@influxdb02 default]# sudo service influxdb start
7. InfluxDB03上配置/etc/default/influxdb文件
加入influxdb01节点
INFLUXD_OPTS="-join influxdb01:8091"

8. InfluxDB03机器启动InfluxDB
[root@influxdb03 default]# sudo service influxdb start
9.InfluxDB01上启动InfluxDB
Influx -host influxdb01

10. 查看Influxdb集群

三、Influxdb集群,我们遇到的坑
Influxdb集群模式下,数据在各个节点之间是同步的,即,我们可以选择任何一个节点写入,数据都可以再其他节点查询到。
搭建集群后,我们遇到的第一个问题就是数据不同步问题。其实,数据写入压力并不大!
数据不同步后重启集群,依然数据不同步。
数据写入时,必须是UTC时间,并且是Unix下的UTC时间格式。
批量写入的数据,有时候会很慢,原因是数据必须按时间降序排序好,再批量插入。
单机模式比集群模式稳定,同时最新的集群不开源了,商业版本支持。
多条批量写入的性能好,但是并发数有限制,批量数据的个数在1000以内最佳