最近参加了一次APMCM,题目给出了很多表格,我们需要对数据进行分析。显然,作为一名会python的大学生,肯定不会直接在表格上进行各种变动,本文就如何使用pandas对excel表格进行数据分析做一些介绍。
1.分析目标
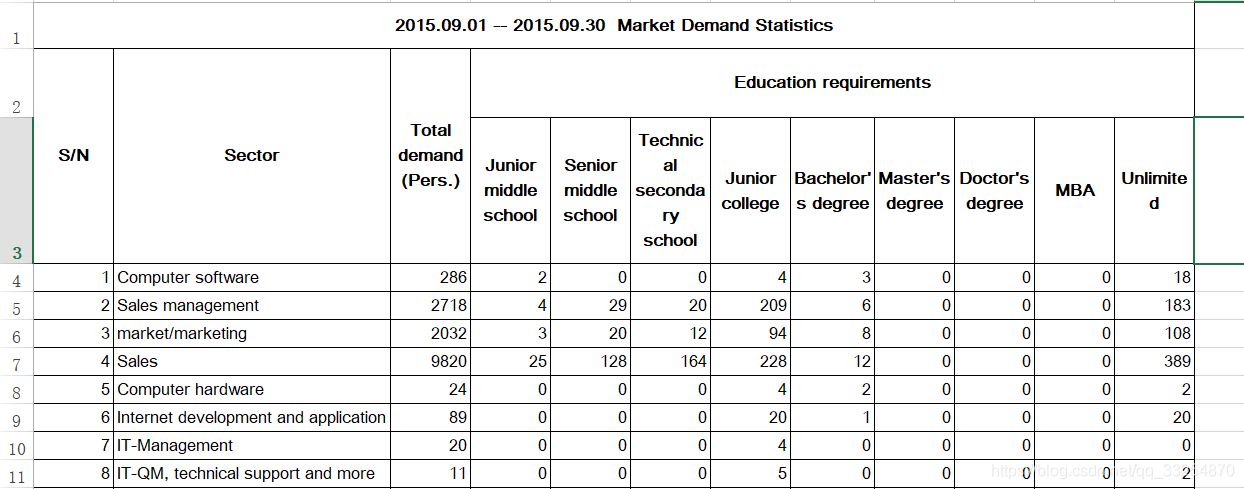 excel表格给出了各个月份各种职业的特征,但我们需要研究某一种职业随时间变化的规律,所以需要对所有表的某一种职业整理到一张表中。这正是我们的出发点。
excel表格给出了各个月份各种职业的特征,但我们需要研究某一种职业随时间变化的规律,所以需要对所有表的某一种职业整理到一张表中。这正是我们的出发点。
2.项目结构
3. 核心代码讲解
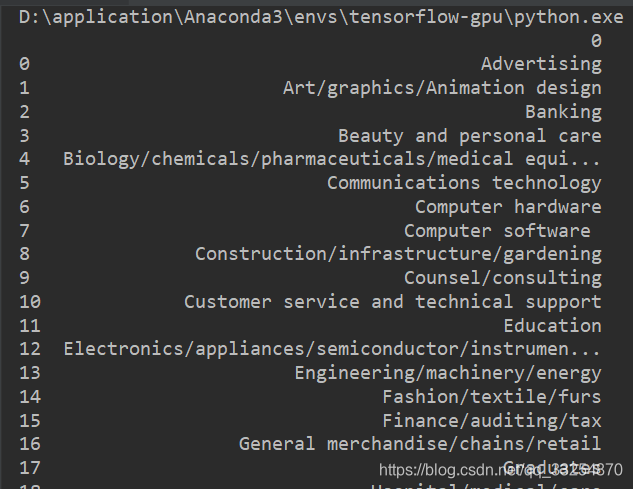
3.1 读取所有表中的职业
# 读取所有表中的职业(pros.xlsx中有所有职业)
pros_path = 'professions/pros.xlsx'
df = pd.read_excel(pros_path, header=None)
# 获取第一列病转化为列表
pros_list = df[0].values.tolist()
print(pros_list)
3.2 数据处理
for file in filenames:
# all excel
data = pd.read_excel(root_path + os.sep + dir + os.sep + file, header=None)
# 从第四行开始为有效数据
data = data[3:][1:]
# 由于后续要根据职业名称查找,所以此处需要将第一列作为索引
data.set_index(1)
csv_columns = [dir + os.sep + file.strip().split('.')[0]]
在一张表中不可能所有的信息都是我们所关注的,所以我们需要进行筛选,其中data = data[3:][1:]表明我们选取第四行、第一列之后的所有数据。注意:此操作之后索引并没有改变。
经过处理之后,看看生成的各类职业文件:
3.3 数据可视化
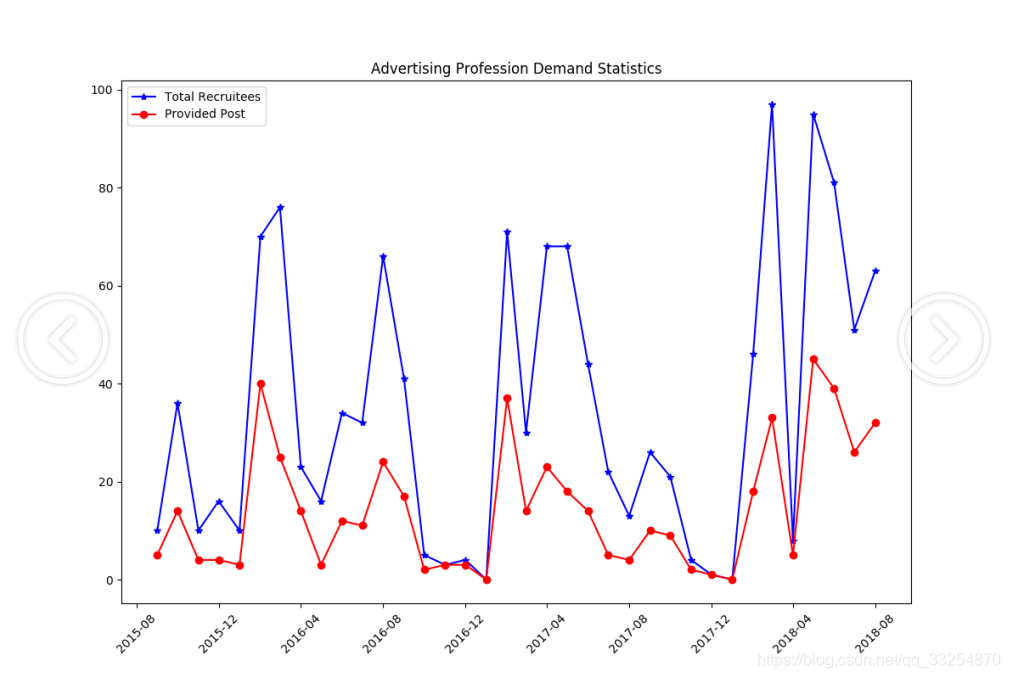
上一步提取出我们需要的文件后,接下来当然需要将数据进行可视化。我们统计两个指标:
1)第二列随时间变化曲线
2)第三列至第十列之和随时间变化曲线