《铝型材表面瑕疵识别》
介绍:
铝型材是佛山南海的支柱性产业。在铝型材的实际生产过程中,由于各方面因素的影响,铝型材表面会产生裂纹、起皮、划伤等瑕疵,这些瑕疵会严重影响铝型材的质量。为保证产品质量,需要人工进行肉眼目测。然而,铝型材的表面自身会含有纹路,与瑕疵的区分度不高。传统人工肉眼检查十分费力,不能及时准确的判断出表面瑕疵,质检的效率难以把控。近年来,深度学习在图像识别等领域取得了突飞猛进的成果。铝型材制造商迫切希望采用最新的AI技术来革新现有质检流程,自动完成质检任务,减少漏检发生率,提高产品的质量,使铝型材产品的生产管理者彻底摆脱了无法全面掌握产品表面质量的状态。本次大赛选择南海铝型材标杆企业的真实痛点作为赛题场景,寻求解决方案,助力企业实现转型升级,提升行业竞争力。
数据源:
大赛数据集里有1万份来自实际生产中有瑕疵的铝型材监测影像数据,每个影像包含一个或多种瑕疵。供机器学习的样图会明确标识影像中所包含的瑕疵类型。
竞赛规则:
使用某企业某一产线某一时间段获取的铝型材图片,训练算法来定位瑕疵所在位置以及判断瑕疵的类型。
瑕疵的衡量标准如下:
1. 型材表面应整洁,不允许有裂纹、起皮、腐蚀和气泡等缺陷存在。
2. 型材表面上允许有轻微的压坑、碰伤、擦伤存在,其允许深度装饰面≯0.03mm,非装饰面>0.07mm,模具挤压痕深度≯0.03mm。
3. 型材端头允许有因锯切产生的局部变形,其纵向长度不应超过10mm。
4. 工业生产过程中,不够明显的瑕疵也会被作为无瑕疵图片进行处理,不必拘泥于无瑕疵图片中的不够明显的瑕疵。
5. 初赛图片结果为单标签,即一张图片只有一种瑕疵。“其他”文件夹中的瑕疵初赛不要求细分,但是统一划分为一类,即“其他”。
6. 复赛图片分成单瑕疵图片、多瑕疵图片以及无瑕疵图片:单瑕疵图片指所含瑕疵类型只有一种的图片,但图片中可能出现多处相同类型的瑕疵;多瑕疵图片指所含瑕疵类型多于一种的图片;无瑕疵图片指瑕疵可忽略不计的图片,这些图片不需要标注。
7. 图片采用矩形框进行标注,标注文件储存成json文件,采用utf-8的编码格式,可通过labelme标注工具直接打开。Labelme是一款开源标注工具,有关labelme和json文件格式的介绍请选手通过网络自行了解。
比赛规程:
1. 参考学习数据量:9月1日提供下载,300张图片,包含所有瑕疵的类型。用于参赛者设计图像识别算法和机器学习。
2. 初赛数据量:3000张图片,包含所有瑕疵的类型。参赛者可以将自己算法识别的结果上传系统,识别率高的前100支团队晋级。
3. 复赛数据量:5000张图片,包含所有瑕疵的类型。晋级复赛的参赛队伍在规定的时间内,通过算法自动识别照片中的瑕疵类型。综合计算识别张数、识别准确率、时长等因素计算出效率最高的6支队伍晋级决赛,参加在佛山南海举行的决赛答辩路演,产出最终获胜团队举行决赛颁奖。
4. 复赛训练数据于10月11日提供下载(md5: 387149fd95906365d1ed950eb687455a),4356张图片,包含单瑕疵图片,多瑕疵图片,无瑕疵图片,用于参赛者设计图像识别算法。图片所含瑕疵类型总计10种,分别为:不导电、擦花、角位漏底、桔皮、漏底、喷流、漆泡、起坑、杂色、脏点。
提交说明:
初赛:参赛者需要预测测试集中的图像的瑕疵类别,提交一份csv文件,不需要表头,参考提交样例sample文件。
复赛:参赛者需要检测测试集中每幅图像所有瑕疵的位置和类型,瑕疵的位置通过矩形检测框进行标记,需给出各个矩形检测框的置信度,并将检测结果保存为utf-8编码的json文件,参考提交样例sample文件。提交的json文件中需要有所有测试图片的结果,评分才有效,否则mAP为0。计算中文瑕疵标注统一换成英文标注,中英文瑕疵标注的对应关系如下所示:
| 中文瑕疵标注 | 英文瑕疵标注 |
| 不导电 | defect0 |
| 擦花 | defect1 |
| 角位漏底 | defect2 |
| 桔皮 | defect3 |
| 漏底 | defect4 |
| 喷流 | defect5 |
| 漆泡 | defect6 |
| 起坑 | defect7 |
| 杂色 | defect8 |
| 脏点 | defect9 |
评估指标:
初赛:预测平均每类准确率。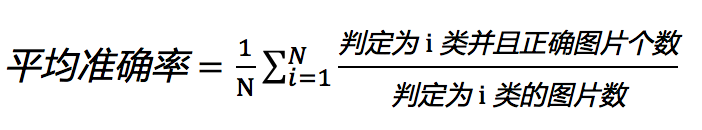
复赛:参照PASCALVOC的评估标准,计算10类瑕疵的mAP值作为赛手的分数。参考链接:https://github.com/rafaelpadilla/Object-Detection-Metrics。具体逻辑见evaluator文件。
1. 上述链接中对评价指标的文字描述和代码冲突时,以代码为准。
2. 需要指出,和上述链接代码不同的是:本次大赛计算mAP时,对同一个ground-truth框,重复预测n次,取置信度(confidence)最高的预测框作为TP(true positive)样本,其余的n-1个框都作为FP(False positive)样本进行处理。
3. 本次大赛参照2010年之后的PASCAL VOC评分标准,检测框和真实框的交并比(IOU)阈值设定为0.5,同时,采用Interpolating all points方法插值获得PR曲线,并在此基础上计算mAP的值。
注意事项:
1. 此次挑战赛禁止以下行为:
a) 比赛不倡导使用外部数据/模型进行竞赛,但如果需要使用外部数据/模型,外部数据必须是开源的,且有相关发表论文介绍和引用;而外部模型也必须开源,且由开源数据训练获得,并有相关发表论文介绍和引用。外部数据/模型都必须提供相应的下载链接,并附加文档说明,列出该外部数据/模型的相关引用论文(最少列出1篇)。
b) 人工标注/修改评测结果数据
c) 多账号刷分等
2. 如果抽查发现参赛队伍有造假、作弊、雷同等行为,将取消该队伍的参赛资格及奖励。
模型提交说明
1. 通过远程工具(如SSH),以root账户登录ECS服务器,IP和密码将随邮件通知;
如:ssh [email protected]
2. 通过远程传输工具(如SCP),上传训练预测阶段可执行脚本、相关代码、模型文件及README说明文件。该阶段强烈建议通过压缩打包上传,来保证稳定性和完整性;
如:scp -r code.zip [email protected]:/root/
3. 安装和部署必要的依赖库;
4. 进行必要的编译或测试,运行可执行脚本,确保在服务器本地可完整运行,并能复现最优提交结果。
代码提交规范标准
1. 数据文件夹 data/
选手无需提交数据文件,我们会把初赛复赛用到的所有原始文件(与官网上的文件和文件名一致,解压后)放到data文件夹下,选手生成的中间文件也放入该文件夹。注意的是,初始的时候data文件夹会被清空,并只放入原始文件。
data
|--guangdong_round2_train_20181011
|--单瑕疵图片
|-- 不导电
|-- 擦花
...
|--多瑕疵图片
|--无瑕疵图片
|--guangdong_round2_test_a_20181011
|--guangdong_round2_test_b_20181106
2. 代码文件夹 code/
读入文件的路径尽量使用相对路径,比如 ../data/XX.jpg。
代码必须包含三部分:模型结构定义的源代码,训练代码,测试代码。不允许在训练或测试代码中直接调用没有源代码定义的模型文件(如.meta),否则直接淘汰。
训练代码和测试代码要求在执行shell脚本train.sh和test.sh后,能自动从data文件夹中读取文件进行模型训练和数据测试。且满足:
1)训练完成后,模型相关文件储存于submit文件夹下的model文件夹中;如果model文件夹存在训练好的模型,训练代码能自动读取该模型继续训练,并且在命令行或者开发环境中显示损失函数的值。如果model文件夹为空,训练代码自动创建模型进行初始化,并对模型进行训练。
2)测试只针对data/guangdong_round2_test_b_20181106下的图片,测试完成后,结果以大赛要求的json格式保存在submit目录中,测试结果文件命名为:赛手第二轮测试排名+results+测试时间.json,(时间格式见附注2),例如对于排名为18的赛手,根据附注2的方式,测试结果文件命名为18_results_20181106_103640.json。
注意,data文件夹中的样本数量不固定,训练代码和测试代码从data文件夹中读取文件,需要滤除非图片文件后,自动计算图片数量,确保训练和测试过程能正常进行。如果训练和测试不能通过,将被淘汰。
3. 结果输出文件夹 submit/
存储提交的json文件,包括两轮测试集的结果,命名方式为:
赛手第一轮测试排名+ Aresults.json,例如:18_Aresults.json
赛手第二轮测试排名+ Bresults.json,例如:18_Bresults.json
注意:
1)该命名方式只针对AB轮比赛的结果,和之前提及的测试代码结果生成的结果文件命名(赛手第二轮测试排名+results+测试时间.json)没有关系。
2)第一轮测试集的结果只作为参考,不要求能复现,但是第二轮的测试结果(即“赛手第二轮测试排名+ Bresults.json”)要求必须能够根据代码和提交模型复现,复现mAP误差小于1e-4,否则直接淘汰。
model文件夹,包含比赛训练的模型参数文件。在运行训练代码后,能看到该模型训练的损失函数值及各种相关指标。
4. 操作系统及主要package版本号
列明操作系统,列明程序中用到的主要package,以及他们的版本号,放入version.txt文件。非官方版本请列明package的出处。
附注:
1、提交代码文件夹结构举例:
project
|--README.md
|--data
|--code
|--model.py
|--train.sh
|--test.sh
|--submit
|--18_Aresults.json
|--18_Bresults.json
|--model
|-- XXX.meta
|--XXX.h5
|--checkpoint
...
README文件中需要说清楚以下几点:
1、算法设计的原理和思路,算法设计参考的论文,模型的训练方法等,有助于帮助复现的说明
2、基于模型组合的方法,请列举并说明每个模型
3、若算法设计过程使用外部开源数据集/开源模型,必须在Readme.md中提供以下说明,(如无说明,将视为比赛弃权):
1)开源数据集/开源模型的下载链接
2)开源数据集/开源模型的引用论文(至少一篇)
3)说明开源数据集或者开源模型在自己的算法中的位置和作用
4)若使用开源模型,必须说明开源模型的是否采用开源训练数据,并给出开源数据集的下载链接和引用论文
2、提交文件文件名代码举例:
import datetime
filename = "../submit/18_results_"+datetime.datetime.now().strftime('%Y%m%d_%H%M%S') + ".json"
数据集下载

链接:https://pan.baidu.com/s/1R2RW-ql0UoO_m5C0X_BYNA 提取码:w7tn
前六名创新点总结:
Ps: 决赛答辩的所有队伍均选用FPN + Faster-RCNN 故以下创新点针对于各队在此基础上的改动.
1- Are u ok: OHEM + SWA + DCN + OCNet
2-禾思科技: SWA + DCN + Generalized-RCNN + Dialted FPN + ROI Align + Focal Loss + IOU_AVG
3-都都都都都都: SWA + Dialted FPN + DPA+ MLBP + HEF + DB
4-打怪升级: box stacking + 结合MaskRcnn + caffe2go
5-数之联: OHEM + Scale Normalization + multi-layer Cascade-RCNN
6-风不动: DCN + ROI Align + batch级OHEM + RPN比例
其中的缩写 - 全称:
SWA: Stochastic Weight Averaging
DCN: Deformable Convolutional Network
OCNet: Object Context Network
OHEM: Online Hard Example Mining
DPA: Dual-path Aggregation (原)
MLBP: Multi-levels ROI-Align Pooling(原)
HEF: Hierachical Feature Ensembling
DB: 用传统方法de-background(原)
前六的参考文献小结:
dialted convolution: 论文 https://towardsdatascience.com/understanding-2d-dilated-convolution-operation-with-examples-in-numpy-and-tensorflow-with-d376b3972b25
OCNet: Object Context Network for Scene Parsing 论文 https://arxiv.org/pdf/1809.00916.pdf
github https://github.com/PkuRainBow/OCNet.pytorch OCNet在Cityscapes和ADE20K上实现了最先进的场景解析性能
Gated Bi-directional CNN for Object Detection 论文 http://www.cs.toronto.edu/~byang/papers/gbd_eccv16.pdf
Automatic Fabric Defect Detection with a Multi-Scale Convolutional Denoising Autoencoder Network Model. 论文 https://www.ncbi.nlm.nih.gov/pubmed/29614813
Cascade-RCNN 论文 https://arxiv.org/abs/1712.00726
github https://github.com/zhaoweicai/cascade-rcnn 知乎 https://zhuanlan.zhihu.com/p/35882192
原文:https://blog.csdn.net/qq_34739662/article/details/84145791
github https://github.com/YeahHuang/Al_surface_defect_detection detectron框架下的 Faster-RCNN + FPN (test&train data augmentation + bbox vote)
https://github.com/herbert-chen/tianchi_lvcai pytorch
https://github.com/Vipermdl/Faster-Rcnn_Tianchi_Guangdong.pytorch faster-rcnn(pytorch)算法
https://github.com/wangbinglin1995/tianchi kreas
更快的pytorch实现更快的r-cnn https://github.com/jwyang/faster-rcnn.pytorch/