spark2.0出现了Dataset,一个更加智能的RDD(本质上还是RDD)。

这个Dataset操作更加
1.简单:支持标准SQL和简化的API

2.执行速度更快:spark作为一个编译器
3.也更加智能:Dataset结构化数据流

但是这个Dataset究竟怎么智能了呢?
Dataset相比RDD改进的一个重要的地方就是这个Dataset执行的时候会先生成执行计划。
那为什么生成执行计划就可以更快的执行了呢,生成的又是什么计划呢?
举个例子来说:
加入写一个求1到10000的累加和,现在有两种方法。
第一种方法是写一个for循环
第二种方法是直接打印1+2+3+…+10000
在执行中,第二种方法的执行效率是更高的,第一种方法还要循环,生成中间结果。
再举个例子:
写一个数据库的查询语句:
SELECT count(*) from store_sales where ss_item_sk = 1000
这句SQL语句的执行过程应该是:
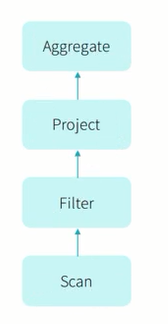
对于这个问题,最好的执行操作是:

而传统的数据库操作模型中每一步的操作都是一个迭代器,这样更加的通用,但是对于处理这种实际的问题时就会降低执行速度。因为他要调用更多的虚拟函数,要将更多的数据加载到内存,没有进行展开,没有进行pipelining。

那我们在写一个项目的时候,我们要考虑编程的统一性,泛用性。那么我们就会写很多很多的判断,循环来处理各种各样的情况。这样在我们执行的时候就会降低速度。
而spark2.0在执行的时候就会对这种情况进行优化

spark2.0会先制定执行计划,在Driver端将代码转换成菜鸟级别的代码(处理单一问题的代码),然后再提交给Executor进行执行,这样就会更快。