本文针对复杂数据网站进行数据爬取测试,本文使用的爬虫工具是psotman,通过postman来模拟和尝试生成post连接,以找出爬虫URL的准确形式,最后将代码整合后形成完整的批量化数据爬取代码。
1.爬取ctd药物数据网站上的drug数据:
ctd数很多生物研究常常使用的大型数据库之一,但是要想每次粘贴进去4000个药物名称进行批量查询和下载,往往会导致数据库的反应时间过长,文件过大中途与服务器断开连接,同时如果想要爬取的药物数目达到几万条,则手动的输出和点击查询会显得笨拙和重复无聊!本文针对复杂的数据库网页进行爬取,实现自动化批量查询和文件写入。
2.详细流程
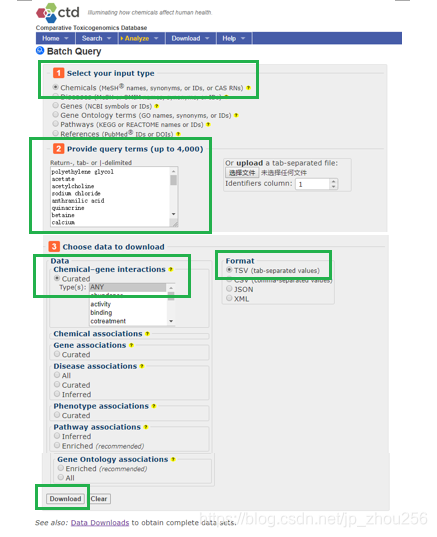
2.1.使用Chrome浏览器,输入网址:http://ctdbase.org/tools/batchQuery.go, 然后输入要查询的药物名称列表:此处仅给出10个供学习参考!
drug_list=
[polyethylene glycol
acetate
acetylcholine
sodium chloride
anthranilic acid
quinacrine
betaine
calcium
CO(2
citric acid],往ctd的网站中输入drug_list的信息。
2.2.先打开Chrom浏览器>点击Download>其余见下图:
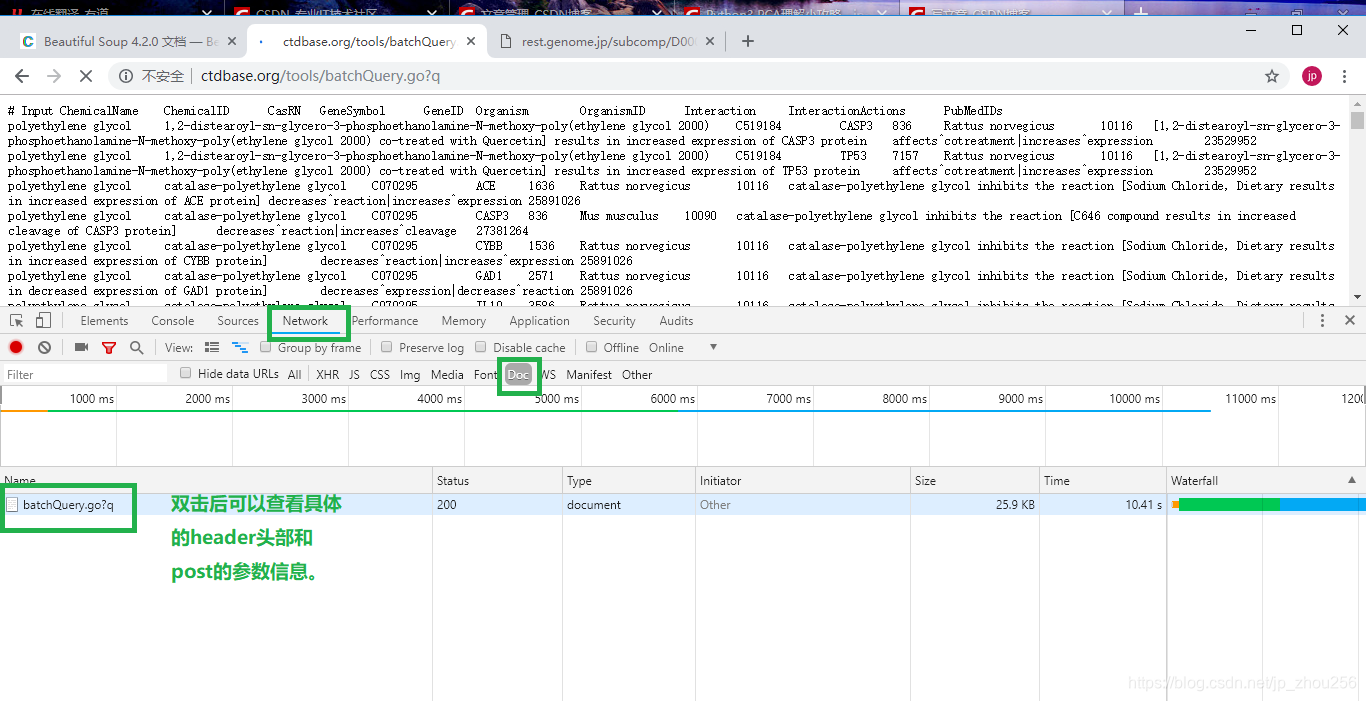
双击“batchQuery.go?q”打开页面,可以找到网页中点击Download后的post表单信息:
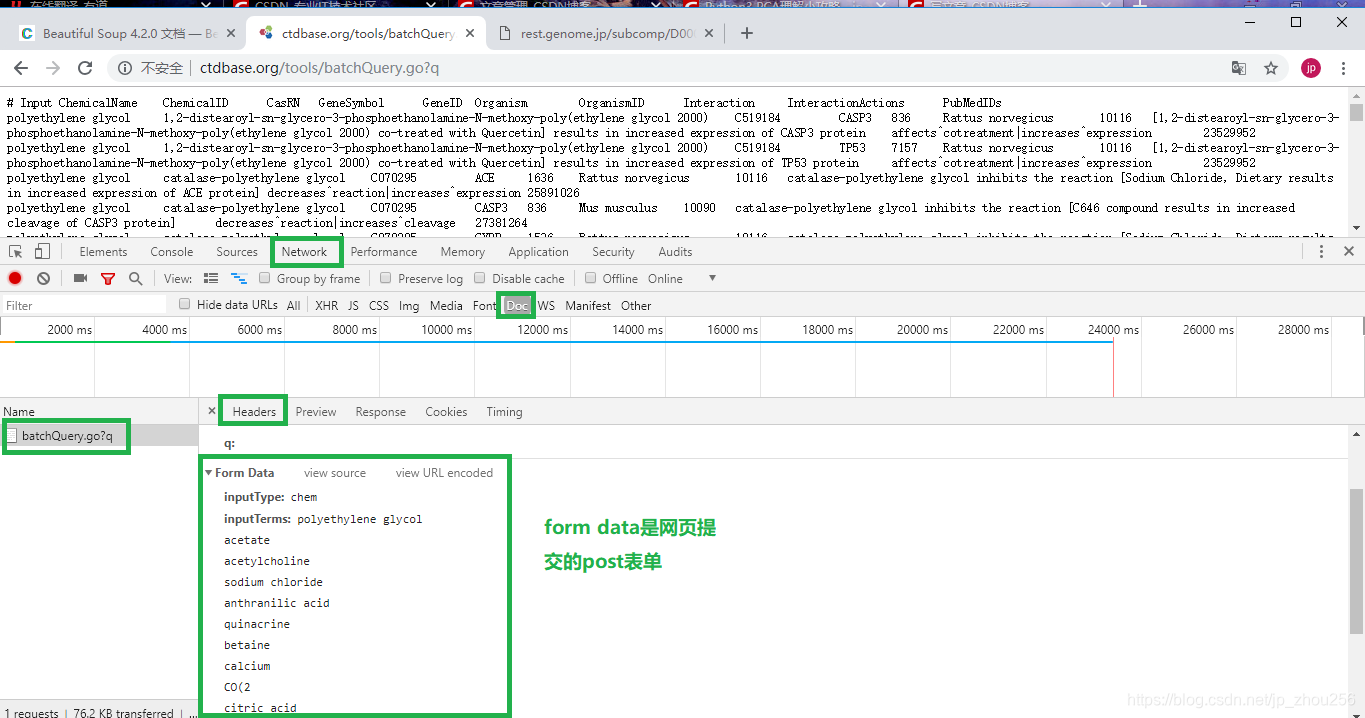
Form Data完整的表单数据
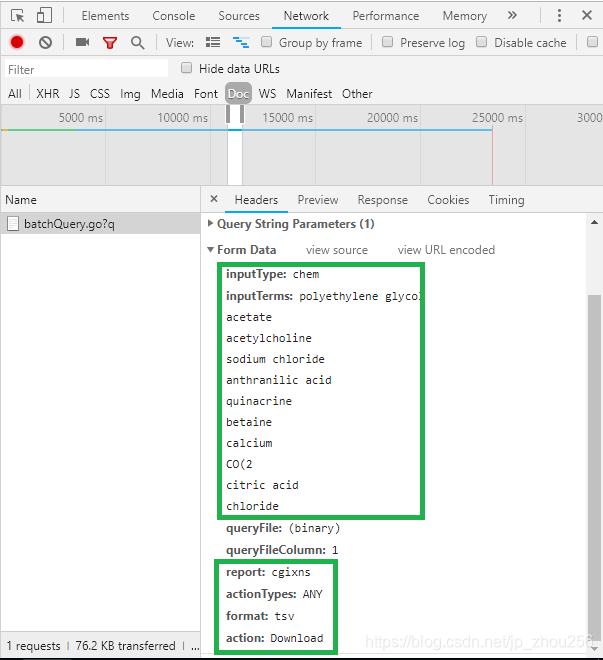 注:画了绿色方框的地方是要在postman中提交的参数字段及其对应值。
注:画了绿色方框的地方是要在postman中提交的参数字段及其对应值。
2.3.在postman中,模仿Form Data部分构造表单数据向网页提交post请求,看是否能够返回正确的response页面,如果可以则表单数据提交正确!之后我们就可以找到批量访问数据的URL的特点,并编写Python自动化程序实现对数据进行批量查询和下载并保存成文本文件的操作。
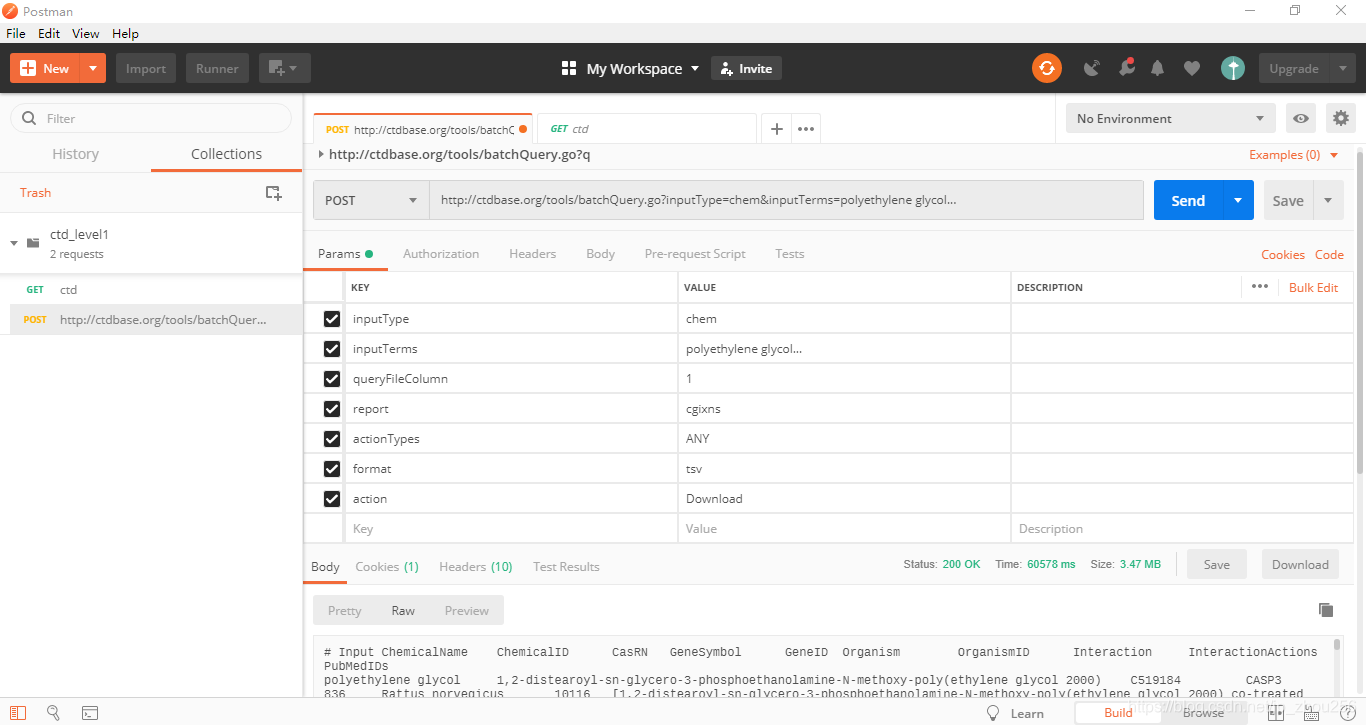
进入postman页面,粘贴入主要的URL domain部分,然后选择“POST”,并在Params中依次填写2.2节中最后绿色框中的内容字段及其对应值,然后点击send就可以查看post提交的结果是否正确。测试成功后,就可以将整个URL的规律找到,实现一个批量自动化的数据爬取程序!
注:对于一些新版网页来说,找到要爬取的字段的规律,可以直接右键>网页源代码>通过ctrl+F来查找指定的字段及其对应的标签,最后通过beautifulsoup4来实现网页标签的快速select操作。
3.代码
# -*- coding: utf-8 -*-
#使用postman传递参数后发现正确返回了结果
"""
http://ctdbase.org/tools/batchQuery.go?inputType=chem&inputTerms=
polyethylene
glycol
acetate
acetylcholine
sodium chloride
anthranilic acid
quinacrine
betaine
calcium
CO(2
citric acid
chloride
&queryFileColumn=1&report=cgixns&actionTypes=ANY&format=tsv&action=Download
"""
import requests
import random
import time
import pandas as pd
#4个数据的选项按钮对应的Id的标签名称
inputType='chem'
#要爬取的药物的名称
drug_name=pd.read_csv('E:/drug_name112.csv')
drug_name.columns=['ChemicalID', 'drugName']
drug_name=sorted(drug_name['drugName'])
#读取可用的IP地址
Valid_IPP=pd.read_csv('E:/valid_IP.csv')
valid_IP11=[]
for i in range(len(Valid_IPP)):
zhou=Valid_IPP.loc[i,:].tolist()
valid_IP11.append(zhou)
#批量数据的爬取
def scrapy_ctd_web(drug_name,valid_IP11):
for i in range(0,len(drug_name)-120,120): #1200
#for i in range(0,120,120):
index1=i
index2=i+120
#print(index1,index2)
drugname='' #拼接第二个参数的文本
count=0
outpath='E:/scrapy_web_ctd/'+str(int(index2/120))+'.txt'
for line in drug_name[index1:index2]:
count+=1
if count==120:
drugname+=line
break
drugname+=line
drugname+='\n'
print(drugname)
#拼接构造post的URL邻接地址
new_url='http://ctdbase.org/tools/batchQuery.go?inputType='+inputType+'&inputTerms='+drugname+'&queryFileColumn=1&report=cgixns&actionTypes=ANY&format=tsv&action=Download'
header={"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Encoding": "gb2312, utf-8",
"Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:64.0) Gecko/20100101 Firefox/64.0",
"Connection": "keep-alive",
"referer":"http://ctdbase.org/tools/batchQuery.go"}
with open(outpath,'w+') as fp:
try:
IP_item = random.choice(valid_IP11)
proxies={IP_item[0].lower():IP_item[1]}
res=requests.get(new_url,proxies=proxies, headers=header,timeout=12) #封装了浏览器头部,同时使用IP池技术做一定程度的反爬虫,timeout设置长一些可以容错:请求时间较长的数据可以爬取下来。
res.encoding='utf-8' #设置页面的编码方式
fp.write(res.text)
print('第{}---{},已经爬取成功!!!'.format(index1,index2))
print('可用IP为: ',IP_item[0].lower(),':',IP_item[1])
#print(res.text)
except:
k=0
while len(res.text)==0:
IP_item = random.choice(valid_IP11)
proxies={IP_item[0].lower():IP_item[1]}
res=requests.get(new_url,proxies=proxies, headers=header,timeout=12) #封装了浏览器头部,同时使用IP池技术做一定程度的反爬虫,timeout设置长一些可以容错:请求时间较长的数据可以爬取下来。
k+=1
time.sleep(5)
if k==10:
print('已经找寻了10次IP地址!!!')
break
if k!=10:
res.encoding='utf-8' #设置页面的编码方式
fp.write(res.text)
print('第{}---{},已经爬取成功!!!'.format(index1,index2))
print('可用IP为: ',IP_item[0].lower(),':',IP_item[1])
else:
continue
print('===========================================')
print('我爬完了!!!')
if __name__ == '__main__':
scrapy_ctd_web(drug_name,valid_IP11)
爬虫程序2代码实例
# -*- coding: utf-8 -*-
""" 爬取drugbank上的对应药物的drugbankID和Targets数据,并写入csv文件"""
import random
import socket
import urllib
import http.cookiejar
import os, sys
import json
from bs4 import BeautifulSoup
import chardet
current_dir = os.path.abspath(os.path.dirname(__file__))
sys.path.append(current_dir)
sys.path.append("..")
ERROR = {
'0': 'Can not open the url,checck you net',
'1': 'Creat download dir error',
'2': 'The image links is empty',
'3': 'Download faild',
'4': 'Build soup error,the html is empty',
'5': 'Can not save the image to your disk',
}
class BrowserBase(object):
def __init__(self):
socket.setdefaulttimeout(20)
def speak(self, name, content):
print( '[%s]%s' % (name, content))
def openurl(self, url):
"""
打开网页
"""
#req = urllib.request.Request(url, header)
cj = http.cookiejar.CookieJar()
#cookie_support = urllib.HTTPCookieProcessor(cj)
self.opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj))
# r = self.opener.open(req)
user_agents = [
'Mozilla/5.0 (Windows; U; Windows NT 5.1; it; rv:1.8.1.11) Gecko/20071127 Firefox/2.0.0.11',
'Opera/9.25 (Windows NT 5.1; U; en)',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)',
'Mozilla/5.0 (compatible; Konqueror/3.5; Linux) KHTML/3.5.5 (like Gecko) (Kubuntu)',
'Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.8.0.12) Gecko/20070731 Ubuntu/dapper-security Firefox/1.5.0.12',
'Lynx/2.8.5rel.1 libwww-FM/2.14 SSL-MM/1.4.1 GNUTLS/1.2.9',
"Mozilla/5.0 (X11; Linux i686) AppleWebKit/535.7 (KHTML, like Gecko) Ubuntu/11.04 Chromium/16.0.912.77 Chrome/16.0.912.77 Safari/535.7",
"Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:10.0) Gecko/20100101 Firefox/10.0 ",
]
agent = random.choice(user_agents)
self.opener.addheaders = [("User-agent", agent), ("Accept", "*/*"), ('Referer', '')]
try:
res = self.opener.open(url)
except :
raise Exception
else:
return res
class Spider(object):
link_set = set()
def __init__(self, BrowserBase):
self.BrowserBase = BrowserBase
def get_link(self, file, page=1):
splider = self.BrowserBase
result = splider.openurl(
'https://www.drugbank.ca/drugs?approved=1&c=name&d=up&page='+str(page)+'')
data = result.read().decode('utf-8', 'ignore')
#element = BeautifulSoup(data, 'lxml')
element = BeautifulSoup(data, 'lxml')
href_list = []
# name-value text-sm-center drug-name
for one in element.findAll("td", class_="name-value"):
if one != None:
one = str(one)
#print(one)
temp_index = one.index('href=')
#print(one[temp_index:])
start_index = one.index('=', temp_index)+2
end_index = one.index('>', start_index)
href = one[start_index: end_index-1]
print(href)
file.write(href)
file.write('\n')
href_list.append(href)
# all_content = all_content.replace(',', '&&').replace('\n', '$$')
#result = self.analyze_link(data)
print(href_list)
return href_list
'''
根据,研报的详情链接,获得研报的详情
'''
# card-header
def get_content(self, linkString='/drugs/DB00316'):
if self.link_set.__contains__(linkString):
return
self.link_set.add(linkString)
if linkString == '':
print('link is empty')
href = "https://www.drugbank.ca"+linkString
id_list = []
try:
result = self.BrowserBase.openurl(href).read()
#网页的编码判断
chardit = chardet.detect(result)
html = result.decode(chardit['encoding'], 'ignore')
element = BeautifulSoup(html, 'lxml')
for one in element.findAll("div", class_="card-header"):
if one == None:
continue
try:
one = str(one)
start_index = one.index('href=')
#print(one[start_index:])
end_index = one.index('">', start_index)
idString = one[start_index: end_index]
id = idString.split('/')[-1]
id_list.append(id)
print(id)
except Exception as e:
print('analyze error', one)
print('写入一个案例')
return id_list
except Exception as e:
print('error>>>', linkString)
return id_list
def analyze_link(self, jsonData="", outputFileName=""):
jsonString = jsonData
jsonStringStartIndex = jsonString.index('{')
jsonStringEndIndex = jsonString.rindex('}')
jsonString = jsonString[jsonStringStartIndex:jsonStringEndIndex+1]
result = json.loads(jsonString)
datas = result['data']
result = []
for one in datas:
one = one.replace('‚', '').replace('"', '')
result.append(one)
return result
def my_split(self, stencement, splider):
splits = stencement.split(',')
date = splits[1]
link = splits[2]
source = splits[4]
level = splits[6]
exception = splits[7]
title = splits[8]
industry = splits[9]
return [date, link, source, level, exception, title, industry]
def get_date(self, dateString):
dateString = dateString.replace(' ', '&')
date = dateString.split('&')[0].split('/')
year = date[0]
month = date[1]
day = date[2]
if len(month)<2:
month = '0'+month
if len(day)<2:
day = '0'+day
date = year+month+day
return date
if __name__ == '__main__':
spider = Spider(BrowserBase())
#Analyze.analyze(stockName)
file = None
all_link = []
try:
with open('C:/scrapy_web/output/drog.txt', 'w+') as temp_f:
#range(1, 103)
for i in range(1, 103):
linkList = spider.get_link(temp_f, page=i)
all_link.extend(linkList)
# 抓取详情页
with open('C:/scrapy_web/output/drog_id.csv', 'w+') as writer_f:
for link in all_link:
print('开始写 ',link,'药品')
dragName = link.split('/')[-1]
id_list = spider.get_content(linkString=link)
writer_f.write(dragName)
writer_f.write(',')
for id in id_list:
writer_f.write(id)
writer_f.write(',')
writer_f.write('\n')
spider.get_content()
except Exception as e:
print(e)
爬虫代码示例3
"""
1.drugbankID示例:DB00001,DB00002,DB00003,DB00004,DB00005,DB00006……
2.爬取drugbank上药物对应的drugbankID和Targets的数据,并将抓取的数据逐行写入文本。
"""
# -*- coding: utf-8 -*-
#1.读入drugbank_all_links文件的drugbankID作为搜索索引文件
import pandas as pd
data=pd.read_csv('E:/drugbank_dglinks.csv')
columns1=data.columns.tolist()
drugbankID=sorted(data['DrugBank ID'])
#2.读取验证好的可用IP地址
Valid_IPP=pd.read_csv('E:/valid_IP.csv')
valid_IP11=[]
for i in range(len(Valid_IPP)):
zhou=Valid_IPP.loc[i,:].tolist()
valid_IP11.append(zhou)
#3.爬取数据并写入文件
test_valid_IP=[]
zhouzhou=[]
unsucced=[]
from bs4 import BeautifulSoup
import requests
import random
import time
import pandas as pd
def web_scrapy(out_path,drugbankID,Proxy_header):
count=0
#with open(out_path, 'w+') as fp:
for drugbankId in drugbankID:
#drugbankId=drugbankID[0]
user_agents = [
'Mozilla/5.0 (Windows; U; Windows NT 5.1; it; rv:1.8.1.11) Gecko/20071127 Firefox/2.0.0.11',
'Opera/9.25 (Windows NT 5.1; U; en)',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)',
'Mozilla/5.0 (compatible; Konqueror/3.5; Linux) KHTML/3.5.5 (like Gecko) (Kubuntu)',
'Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.8.0.12) Gecko/20070731 Ubuntu/dapper-security Firefox/1.5.0.12',
'Lynx/2.8.5rel.1 libwww-FM/2.14 SSL-MM/1.4.1 GNUTLS/1.2.9',
"Mozilla/5.0 (X11; Linux i686) AppleWebKit/535.7 (KHTML, like Gecko) Ubuntu/11.04 Chromium/16.0.912.77 Chrome/16.0.912.77 Safari/535.7",
"Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:10.0) Gecko/20100101 Firefox/10.0 ",
]
agent = random.choice(user_agents)
#通过伪装成浏览器来实现反爬虫
header={"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Encoding": "gb2312, utf-8",
"Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2",
"User-Agent": agent,
"Connection": "keep-alive",
"referer":"rest.genome"}
count+=1
out_path1=out_path+drugbankId+'.txt' #逐个逐个的写入可以有效的防止IP反爬致死
with open(out_path1, 'w+') as fp:
try:
new_url='https://www.drugbank.ca/drugs/'+drugbankId
IP_item = random.choice(Proxy_header)
#IP_item=['https','219.234.5.128:3128']
res=requests.get(new_url) #封装了浏览器头部,同时使用IP池技术做一定程度的反爬虫,timeout设置长一些可以容错:请求时间较长的数据可以爬取下来。 res.encoding='utf-8' #设置页面的编码方式 fp.write(res.text)
proxies={IP_item[0].lower():IP_item[1]}
try:
res=requests.get(new_url,proxies=proxies, headers=header,timeout=12) #封装了浏览器头部,同时使用IP池技术做一定程度的反爬虫,timeout设置长一些可以容错:请求时间较长的数据可以爬取下来。
#res=requests.get(new_url, headers=header,timeout=12) #封装了浏览器头部,同时使用IP池技术做一定程度的反爬虫,timeout设置长一些可以容错:请求时间较长的数据可以爬取下来。
#test_valid_IP.append(IP_item)
res.encoding='utf-8' #设置页面的编码方式
soup=BeautifulSoup(res.text,'html.parser')
header=soup.select('.bond-list .row .col-sm-12 .col-md-7 a') #class内部含有空格只取前半部分
#遍历到我想要的所有TargetID
temp1=[drugbankId]
for line in header:
item=line.string #取到标签的content或者string
temp1.append(item)
#将temp1回写到文档中并换行
for line in temp1:
fp.write(line+'\t')
fp.write('\n')
fp.flush()
zhouzhou.append(temp1)
print('第{}是{},已经爬取成功!!!'.format(count,drugbankId))
#print('可用IP为: ',IP_item[0].lower(),':',IP_item[1])
time.sleep(1)
except:
k=0
while len(res.text)==0:
IP_item = random.choice(Proxy_header)
proxies={IP_item[0].lower():IP_item[1]}
res=requests.get(new_url,proxies=proxies, headers=header,timeout=12) #封装了浏览器头部,同时使用IP池技术做一定程度的反爬虫,timeout设置长一些可以容错:请求时间较长的数据可以爬取下来。
k+=1
if k==10:
print('已经找寻了10次IP地址!!!')
break
if k!=10:
test_valid_IP.append(IP_item)
res.encoding='utf-8' #设置页面的编码方式
soup=BeautifulSoup(res.text,'html.parser')
header=soup.select('.bond-list .row .col-sm-12 .col-md-7 a') #class内部含有空格只取前半部分
#遍历到我想要的所有TargetID
temp1=[drugbankId]
for line in header:
item=line.string #取到标签的content或者string
temp1.append(item)
#将temp1回写到文档中并换行
for line in temp1:
fp.write(line+'\t')
fp.write('\n')
fp.flush()
zhouzhou.append(temp1)
print('第{}是{},已经爬取成功!!!'.format(count,drugbankId))
#print('可用IP为: ',IP_item[0].lower(),':',IP_item[1])
time.sleep(1)
else:
print('没有爬取到数据!!!')
unsucced.append(drugbankId) #待查看
continue
except:
pass
print('===========================================')
print('我爬完了!!!')
out_path='E:/zhou/drugbank/'
#del valid_IP11[:4]
web_scrapy(out_path,drugbankID,valid_IP11)
with open('E:/scrapy_web_ctd/drugbank256.txt','w+') as fp:
for line in zhouzhou:
for i in range(len(line)-1):
fp.write(line[i])
fp.write(',')
fp.write(line[-1])
fp.write('\n')
fp.flush() #刷新一下
#zhou=[1,2,3,4,5,6]
#zhou[-1]