因为阅读网上的很多电子书存在翻页繁琐和查找不方便的问题,也很难在网站上做笔记。故查阅部分资料想要自己写一个小爬虫,然后可以将爬取到的电子书内容页面(html格式)最终保存成PDF格式。故编写如下爬虫代码来实现此功能。由于Python3和Python2.7的版本兼容性问题,from main import WKhtmlToPdf, wkhtmltopdf 始终未能或者成功,故只在正确爬取了电子书后,我并不能将很好的将已经处理成单页的PDF文件拼接起来合成一个大的PDF文件。但是,条条大路通罗马,我发现Adobe reader9.0可以直接帮助我解决PDF的拆分与合并问题。最终依然可以达到异曲同工的作用!
1.Adobe reader9.0直接做拆分
直接通过Adobe reader9.0打开要拆分的PDF,然后选择"文档">“拆分文档”>页数=1>确定>大功告成!
2.使用Adobe reader9.0直接做合并
“文件”>“合并”>“合并文件到单个PDF”>“添加文件”>通过上移和下调文件位置>合并文件>大功告成!
3.使用爬虫爬取网站电子书的HTML,转换成为PDF后,再做PDF文件的合并
原理很简单:通过查看网页源代码,发现网页布局上感兴趣的标签的规律,然后分别取到一级标题及其URL链接,二级标题及其URL链接,如此进行即可。说到这里,这种嵌套的逻辑使用多层字典即可很好的完成嵌套分层功能。本文爬取的网站为:http://python3-cookbook.readthedocs.io/zh_CN/latest/ ,此网站是学习Python3的最佳如本教程之一。
3.1.代码
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
import random
import time
import pandas as pd
import os
import sys
#from imp import reload
#reload(MyModule)
#from main import WKhtmlToPdf, wkhtmltopdf
#wkhtmltopdf在界面执行失败,所以使用命令行试试。
import re
import pdfkit
from PyPDF2 import PdfFileMerger
def parse_title_and_url(html):
"""
python3-cookbook电子网页转为PDF,提取一二级标题。
"""
base_url = html
res=requests.get(base_url)
res.encoding='utf-8' #设置页面的编码方式
soup=BeautifulSoup(res.text,'html.parser')
book_name = ''
chapter_info = []
book_name = soup.find('div', class_='wy-side-nav-search').a.text
menu = soup.find_all('div', class_='wy-menu')
chapters = menu[0].ul.find_all('li', class_='toctree-l1')
for chapter in chapters: #这里获得只是一级目录
info = {}
# 获取一级标题和url
# 标题中含有'/'和'*'会保存失败
info['title'] = chapter.a.text.replace('/', '').replace('*', '')
info['url'] = base_url + chapter.a.get('href')
info['child_chapters'] = [] #装在二级标题
#new_url1='http://python3-cookbook.readthedocs.io/zh_CN/latest/chapters/p01_data_structures_algorithms.html'
new_url1=base_url + chapter.a.get('href')
res1=requests.get(new_url1) #二级目录
res1.encoding='utf-8' #设置页面的编码方式
soup=BeautifulSoup(res1.text,'html.parser')
try:
menu2 = soup.find_all('div', class_='toctree-wrapper compound')
chapters2 = menu2[0].ul.find_all('li', class_='toctree-l1')
except:
continue
for chapter1 in chapters2: #这里获得只是一级目录
info1 = {}
# 获取一级标题和url
# 标题中含有'/'和'*'会保存失败
info1['title'] = chapter1.a.text.replace('/', '').replace('*', '')
info1['url'] = base_url + chapter1.a.get('href')[3:] #取出URL拼接中存在的'../'
info1['child_chapters'] = []
info['child_chapters'].append(info1)
chapter_info.append(info)
return chapter_info
html='http://python3-cookbook.readthedocs.io/zh_CN/latest/'
chapter_info=parse_title_and_url(html)
#获取章节内容
def get_one_page(url):
"""
解析URL,获取需要的html内容
:param url: 目标网址
:return: html
"""
res1=requests.get(url) #二级目录
res1.encoding='utf-8' #设置页面的编码方式
return res1.text
html_template = """
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
</head>
<body>
{content}
</body>
</html>
"""
def get_content(url):
"""
解析URL,获取需要的html内容
:param url: 目标网址
:return: html
"""
html = get_one_page(url)
soup = BeautifulSoup(html, 'html.parser')
content = soup.find('div', attrs={'itemprop': 'articleBody'}) #这里没有改变
html = html_template.format(content=content)
return html
#获取章节内容
#循环保存下来每一个网页
#for i in range(len(chapter_info)):
# for j in range(len(chapter_info[i]['child_chapters'])):
# url11=chapter_info[i]['child_chapters'][j]['url']
# #chapter_info[0]['child_chapters'][0]['url']
# #url11='http://python3-cookbook.readthedocs.io/zh_CN/latest/c01/p01_unpack_sequence_into_separate_variables.html'
# html11=get_content(url11)
# chapter_info[i]['child_chapters'][j]['child_chapters'].append(html11)
def save_pdf(html, filename):
"""
把所有html文件保存到pdf文件
:param html: html内容
:param file_name: pdf文件名
:return:
"""
options = {
'page-size': 'Letter',
'margin-top': '0.75in',
'margin-right': '0.75in',
'margin-bottom': '0.75in',
'margin-left': '0.75in',
'encoding': "UTF-8",
'custom-header': [
('Accept-Encoding', 'gzip')
],
'cookie': [
('cookie-name1', 'cookie-value1'),
('cookie-name2', 'cookie-value2'),
],
'outline-depth': 10,
}
pdfkit.from_string(html, filename, options=options)
def parse_html_to_pdf():
"""
解析URL,获取html,保存成pdf文件
:return: None
"""
try:
#for chapter in chapter_info[:1]:
for chapter in chapter_info[1:]:
ctitle = chapter['title']
url = chapter['url']
# 文件夹不存在则创建(多级目录)
dir_name ='E:/ququ/'+ctitle+'/'
print(ctitle)
print(url)
print(dir_name)
if not os.path.exists(dir_name):
os.makedirs(dir_name)
html = get_content(url)
#padf_path = os.path.join(dir_name, ctitle + '.pdf')
save_pdf(html, dir_name+ctitle + '.pdf')
children = chapter['child_chapters']
if children:
for child in children:
html = get_content(child['url'])
pdf_path = dir_name+child['title'] + '.pdf'
save_pdf(html, pdf_path)
except Exception as e:
print(e)
parse_html_to_pdf()
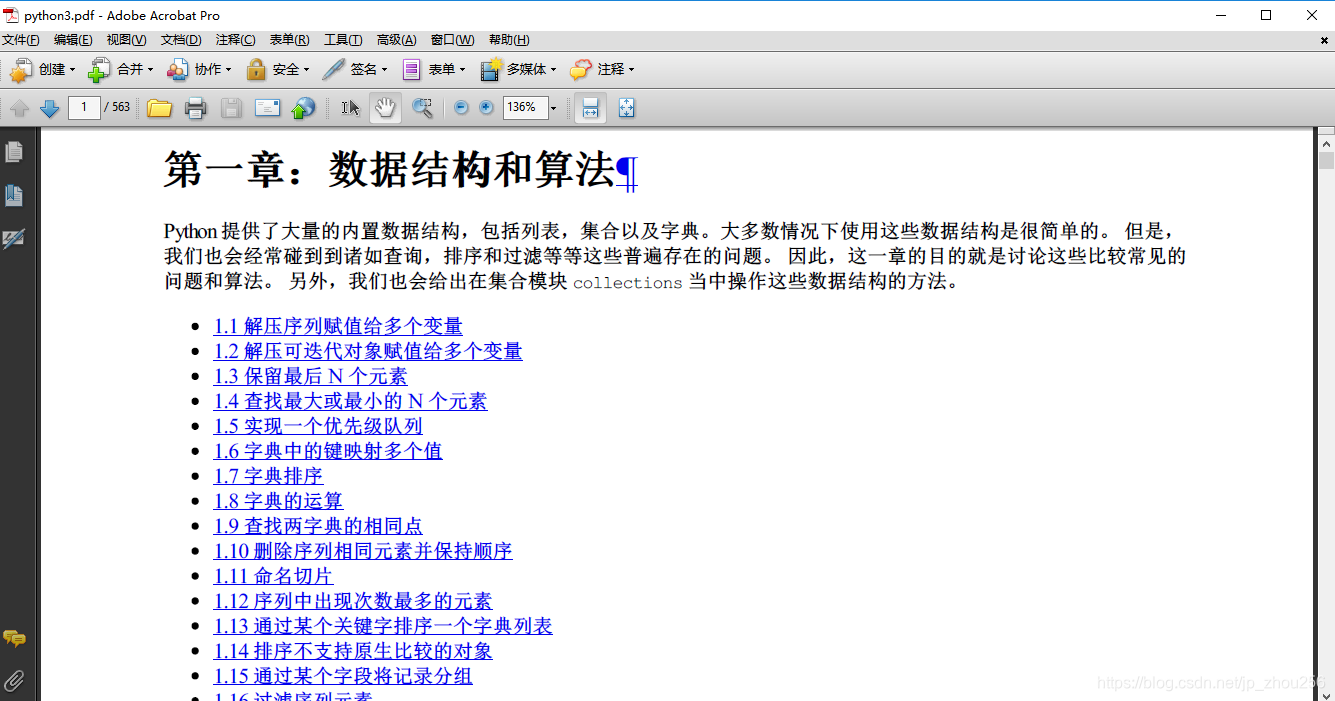
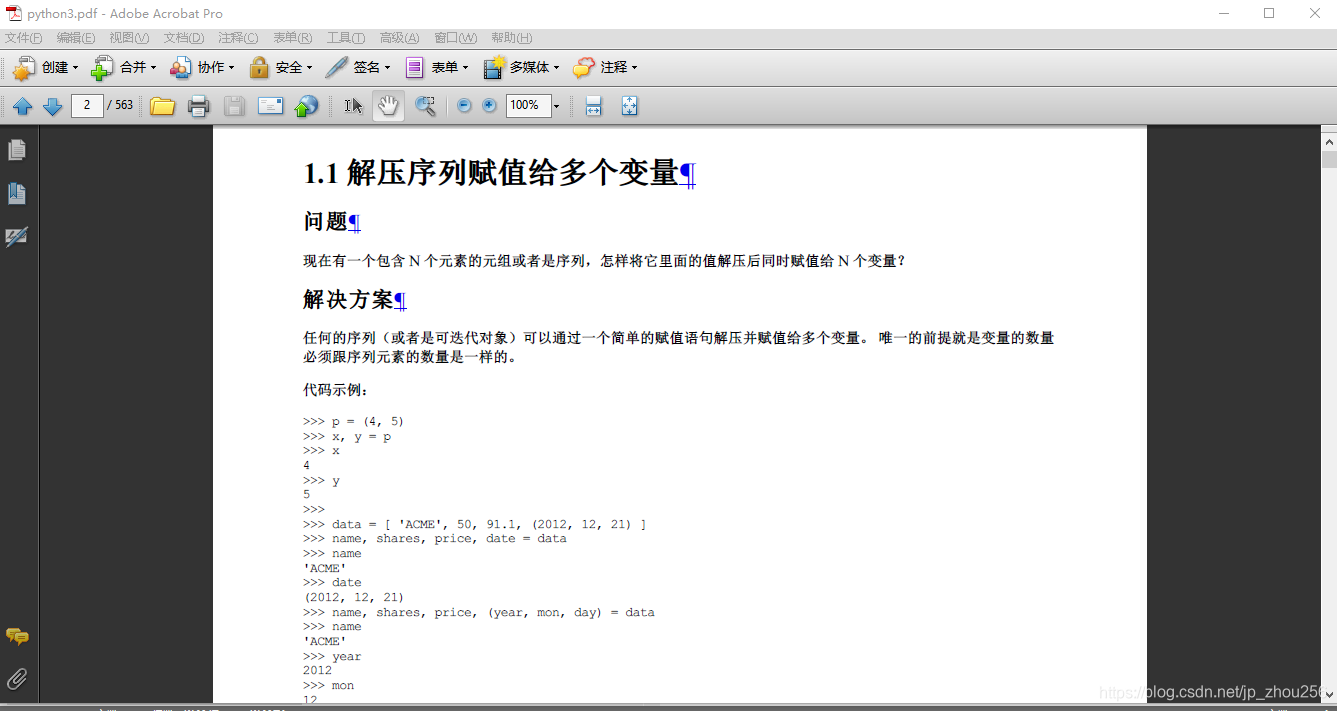
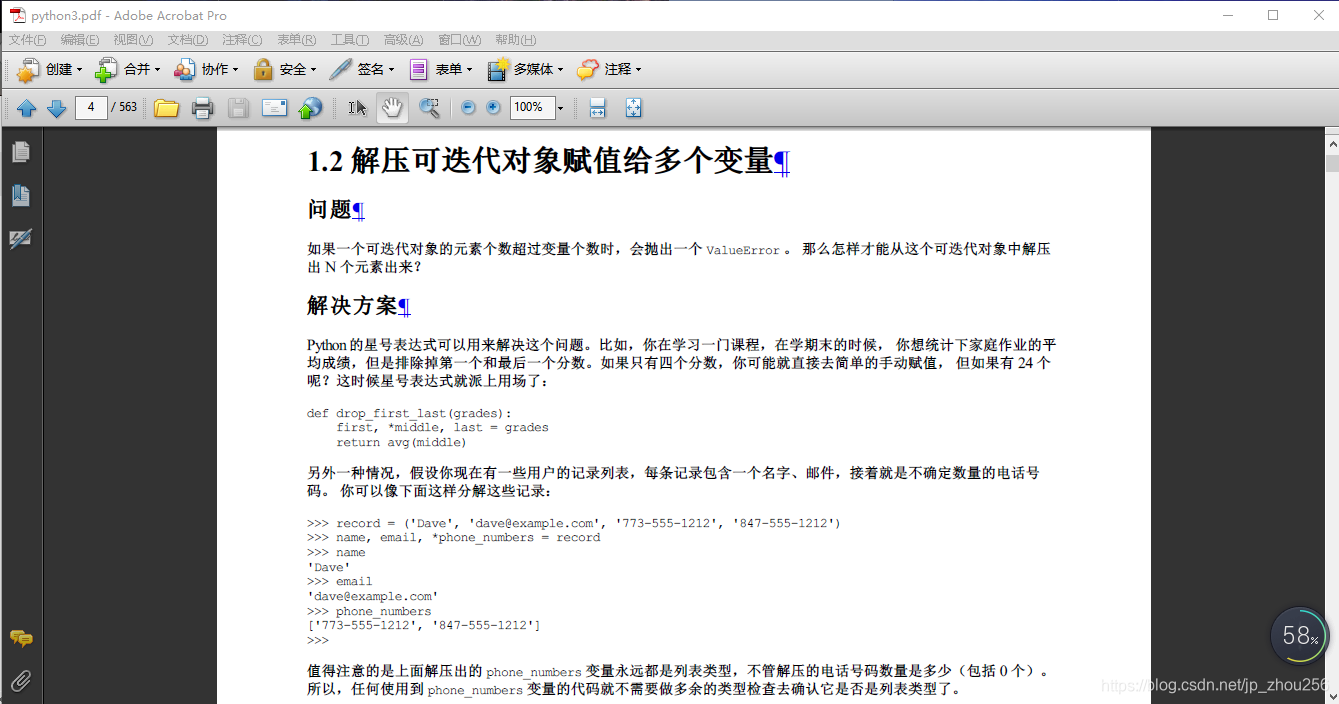
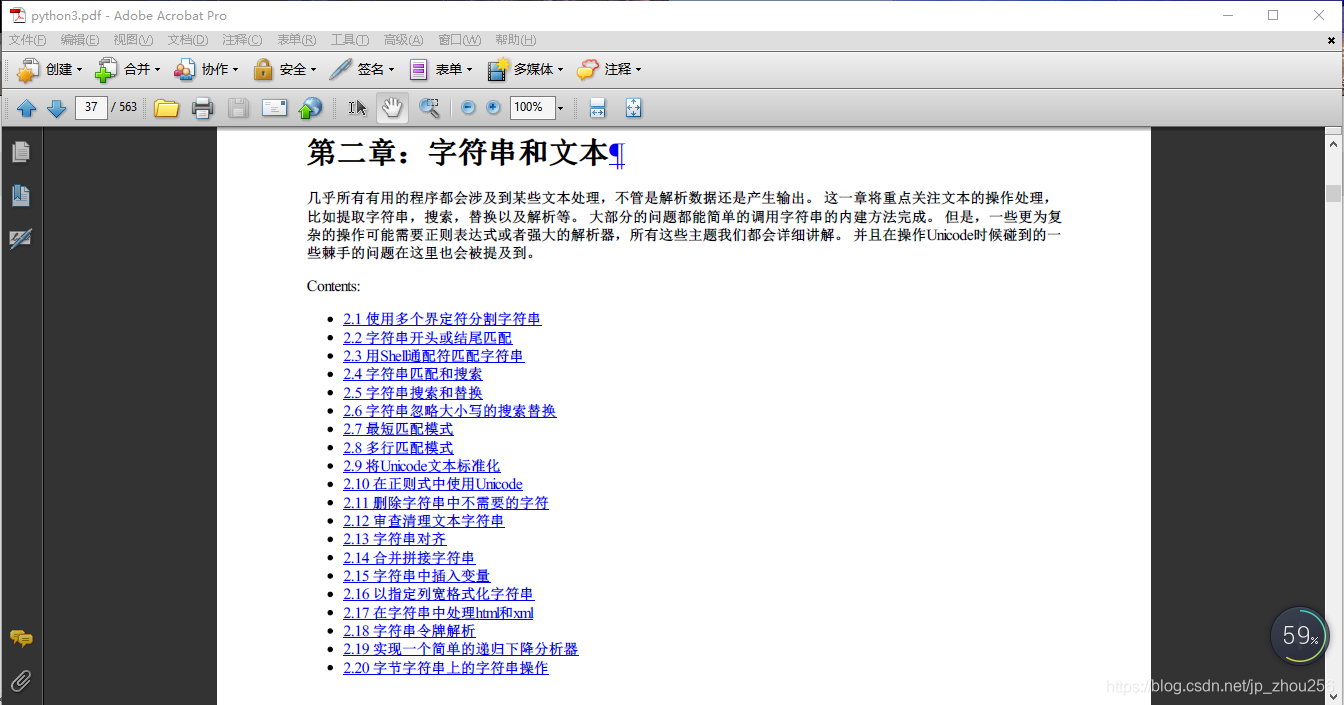
3.2.代码运行结果如下:
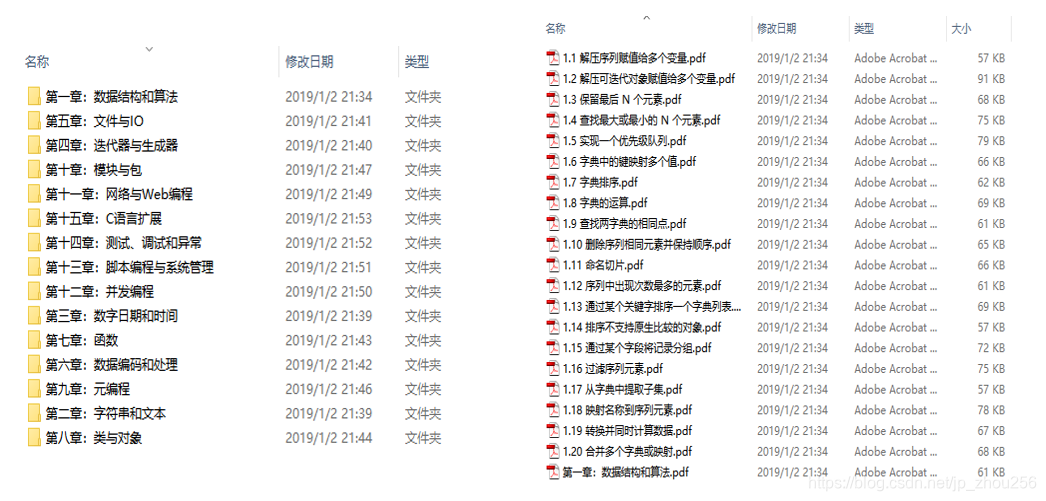
使用Adobe reader9.0直接做合并,同时注意调整顺序即可。先完成各章的章节合并(选中上图中的如:第一章:数据结构和算法>右键>" 在acrobat中合并支持的文件"),并注意将顺序调整好,执行合并操作,合并后的文件命名为"组合i" (i=1,…章节数),最后再对各章节做最终合并即可得到一个完整的python3-cookbook网页版教程的PDF手册。效果大致如下:
注:这里我特别将文件名保存成Python3.PDF
完工后的效果展示如下: