kafka介绍
- Kafka:是一个消息队列,
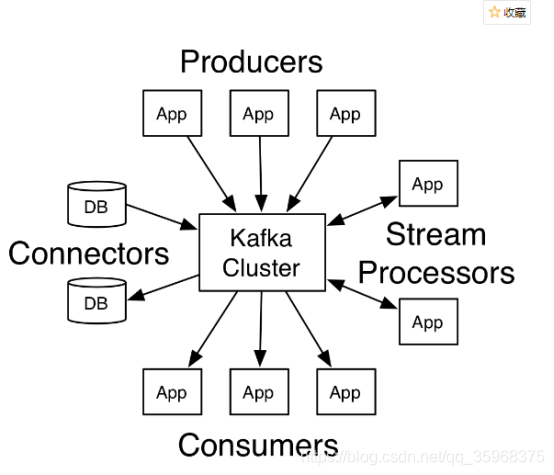
流平台有三个关键功能:
发布和订阅记录流,类似于消息队列或企业消息传递系统。
以容错、持久的方式存储记录流。
当记录发生时,处理记录流。 - Kafka通常用于两大类应用:
构建可靠地在系统或应用程序之间获取数据的实时流数据管道。
构建转换数据流或对数据流作出反应的实时流应用程序。 - 概念:
Kafka作为集群运行在一个或多个服务器上,可以跨越多个数据中心。
Kafka集群存储的流记录在类别中称为topic.
每个记录由一个键、一个值和一个时间戳组成。 - Kafka有四个核心API:
生产者API允许应用程序将记录流发布到一个或多个Kafka主题。
消费者API允许应用程序订阅一个或多个主题并处理向其生成的记录流。
流API允许应用程序充当流处理器,从一个或多个主题消耗输入流,并产生输出流到一个或多个输出主题,从而有效地将输入流转换为输出流。
连接器API允许构建和运行可重用的生产者或使用者,将Kafka主题连接到现有的应用程序或数据系统。例如,连接到关系数据库的连接器可能捕获对表的每一项更改。
- 主题和日志
主题是将记录发布到的类别或提要名称。Kafka中的主题总是多订阅者;也就是说,一个topic可以有零、一个或多个订阅写入它的数据的使用者。(kafka有多个生产者和消费者)
每个分区都有偏移量(offset)
kafka里面的记录默认保留两天,超过两天,就会删除,(可以配置)
日志中的分区有几种用途。
它们允许日志扩展到适合于单个服务器的大小之外。每个单独的分区必须适合承载它的服务器,但是一个主题可能有许多分区,因此它可以处理任意数量的数据。
它们充当并行性的单位-更详细地介绍一下
每个分区有一个服务器充当“领导者”,零个或多个服务器充当“追随者”。领导者处理分区的所有读写请求,而跟随者则被动地复制领导。如果领导失败,其中一个追随者将自动成为新的领导。每个服务器都充当一些分区的领导者和其他分区的跟随者,因此负载在集群中是很好的平衡。
- 生产者
生产者向他们选择的主题发布数据。生产者负责选择要分配给主题中的哪个分区的记录。这可以循环方式完成,只需平衡负载,也可以根据某些语义分区函数(例如,基于记录中的某个键)来完成。更多关于使用分区的一秒! - 消费者
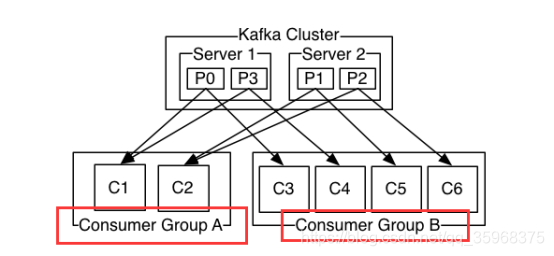
消费者给自己贴上一个标签消费者群体名称,并且发布到主题的每条记录都被传递给每个订阅使用者组中的一个使用者实例。使用者实例可以在单独的进程中,也可以在不同的机器上。
如果所有使用者实例都具有相同的使用者组,那么记录将有效地在使用者实例上被负载平衡。
如果所有的使用者实例都有不同的使用者组,那么每个记录将被广播到所有使用者进程。
- 在高级别上,Kafka提供了以下保证
由生产者发送到特定主题分区的消息将按发送顺序追加。也就是说,如果记录M1是由记录M2的同一个生产者发送的,并且首先发送的是M1,那么M1的偏移量将低于M2,并且出现在日志的前面。
使用者实例按记录在日志中的存储顺序查看记录。
对于具有复制因子N的主题,我们将容忍最多n-1服务器故障,而不会丢失提交给日志的任何记录。
流处理框架:storm,samza
生态系统:hadoop生态圈,spark生态圈,kafka生态圈;
- Java–连接kafka
参照:kafka-2.2.0-src\examples\src\main\java\kafka\examples下的文件
所有客户端的入口函数
*如何看或者码别人的代码;
- 从main函数一步一步往下走
- 如果是调用方法,就往里跟,执行完就出来;
- 看源码不要指望着一遍就能看懂,得多看几遍
- 看源码的步骤要和程序执行的步骤一样
- Spark–链接kafka
启动一个生产者
bin/kafka-console-producer.sh --broker-list node-1:9092,node-2:9092,node-3:9092,node-4:9092 --topic multi-test