- 数据来源
Nginx+tomcat架构图

大数据的数据来源从哪
ive(数据仓库),–>mysql数据库;数据库的记录存储的是最近的记录(1亿,1个月,1周,1天),之前的数据要先备份到数据仓库,然后要清理掉(mysql),
日志:日记历史(先清理日志这个操作很low–不可取);log4j2;

两手准备:
数据库中的表有做记录;(是最近的数据)
日志:格式,我们自己定(文件)

- 大数据所需要的数据来源日志部分是分散的;进行大数据运算和统计需要把分散的日志合并到一个地方(hdfs);
1.Log4j:一天一个日志文件吗?今天把昨天的日志上传到hdfs上多好(hdfs命令,java也好)(每天都传)
2.需要将同一个命令在所有的有日志的电脑都要执行(400多台)
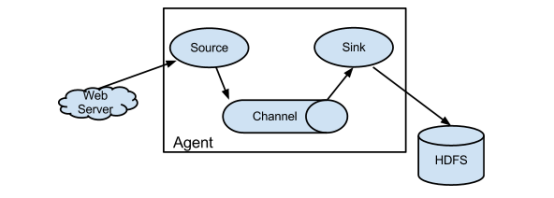
- flume介绍
Flume(水槽):采集工具,将大数据分散的数据源(数据库,日志)统一采集到一个地方(hdfs),
官网:http://flume.apache.org/
Flume是一种分布式、可靠和可用的服务,可以高效地收集、聚合和移动大量的日志数据。它具有基于流数据流的简单灵活的体系结构。它具有鲁棒性和容错性,具有可调的可靠性机制和多种故障转移和恢复机制。它使用了一个简单的、可扩展的数据模型,允许在线分析应用程序
结构:
Source:来源(flume)
Channel:渠道(flume)
Sink:目的地(flume)
webServer:数据源(产生数据的地方,tomcat)
Hdfs:它是把数据放到了hdfs中;
下载:http://flume.apache.org/download.html
http://mirrors.ustc.edu.cn/apache/flume/1.9.0/
我们使用flume:1.8;

Bin:可执行文件
Conf:配置文件
Docs:离线的帮助文档
Lib:jar包
Tools:工具
离线版本的文档:

- 实战
系统要求:
1.Java运行时环境-Java1.8或更高版本
2.内存-为源、通道或接收器使用的配置提供足够的内存
3.磁盘空间.通道或接收器使用的配置的足够磁盘空间
目录权限-代理使用的目录的读/写权限


配置文件:(新建一个配置文件,名字随便起)(conf/flume_hw.properties);官方中一个简单的例子:

# flume配置的例子
# Name the components on this agent
# source:起一个别名
# properties文件它是java的配置文件,=左边就是键,=右边是值;键的开头都是以a1(就是flume的名字--agent的名字就是a1);a1随便起
a1.sources = r1
# sink:起一个别名
a1.sinks = k1
# channels;:起一个别名
a1.channels = c1
# Describe/configure the source
# a1(agent的名字).sources(来源).r1(来源的名字);配置多个来源
# type:不能随便写(文档上说明)
a1.sources.r1.type = netcat
# bind:netcat的一个属性(绑定)
a1.sources.r1.bind = localhost
# port:netcat的一个属性;(端口)
a1.sources.r1.port = 44444
# Describe the sink
# 描述一个sink: logger日志(打印到控制台上)
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
# 描述一下channel:内存
a1.channels.c1.type = memory
# capacity:容量
a1.channels.c1.capacity = 1000
# transactionCapacity:事务的容量
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
# 绑定;source和channel绑定
a1.sources.r1.channels = c1
# sink和channel绑定
a1.sinks.k1.channel = c1
配置文件:(conf/flume-env.sh.template复制为conf/flume-env.sh)

启动命令(服务器端)

# --name后面的a1要和配置文件中agent的名字一样
bin/flume-ng agent --conf conf --conf-file conf/flume_hw.properties --name a1 -Dflume.root.logger=INFO,console
启动以后是以前台进程访问(不是后台进程,千万不要敲ctrl+c)
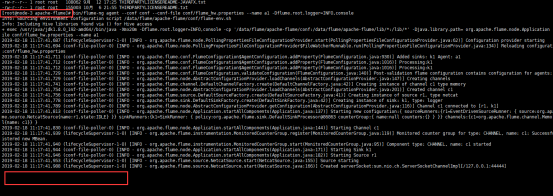
查看是否启动:
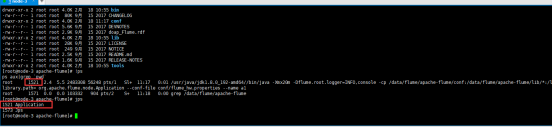
- 启动客户端
Telnet:向指定的服务器和端口发送数据;网络上ip+端口是否畅通;
Ping:ip是否畅通
Telnet:默认centos是木有安装的,yum -y install telnet;
输入以下命令,服务器就能收到
telnet localhost 44444

许任何人都可以连接flume(node-1,node-2,node-3,node-4都可以连接flume)
修改配置文件(conf/flume_hw.properties)
# flume配置的例子
# Name the components on this agent
# source:起一个别名
# properties文件它是java的配置文件,=左边就是键,=右边是值;键的开头都是以a1(就是flume的名字--agent的名字就是a1);a1随便起
a1.sources = r1
# sink:起一个别名
a1.sinks = k1
# channels;:起一个别名
a1.channels = c1
# Describe/configure the source
# a1(agent的名字).sources(来源).r1(来源的名字);配置多个来源
# type:不能随便写(文档上说明)
a1.sources.r1.type = netcat
# bind:netcat的一个属性(绑定),允许任何人访问
a1.sources.r1.bind = 0.0.0.0
# port:netcat的一个属性;(端口)
a1.sources.r1.port = 44444
# Describe the sink
# 描述一个sink: logger日志(打印到控制台上)
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
# 描述一下channel:内存
a1.channels.c1.type = memory
# capacity:容量
a1.channels.c1.capacity = 1000
# transactionCapacity:事务的容量
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
# 绑定;source和channel绑定
a1.sources.r1.channels = c1
# sink和channel绑定
a1.sinks.k1.channel = c1
重启服务器端
# --name后面的a1要和配置文件中agent的名字一样
nohup bin/flume-ng agent --conf conf --conf-file conf/flume_hw.properties --name a1 -Dflume.root.logger=INFO,console &


- 架构图

官方手册如何查看:(source,channel,sink)

- Source

Netcat:
Avro:数据序列化系统;(java.io.serializtion);在java中new的对象想存储到内存以外的地方,需要实现serializiable接口;(flume高可用的时候必须得使用它)
- Spooldir
监控某个目录的变化;只要有新文件就会被flume捕获
指定的目录必须存在
指定的目录下面所有的文件都会被flume获取,已经获取过的,会将源文件增加一个后缀名:(.COMPLETED–完成);(文件的扩展名properties)
配置文件:
# flume配置的例子
# Name the components on this agent
# source:起一个别名
# properties文件它是java的配置文件,=左边就是键,=右边是值;键的开头都是以a1(就是flume的名字--agent的名字就是a1);a1随便起
a1.sources = r1
# sink:起一个别名
a1.sinks = k1
# channels;:起一个别名
a1.channels = c1
# Describe/configure the source
# spooldir:监控硬盘上指定的某个目录,如果文件发生变化,会被flume捕获;
a1.sources.r1.type = spooldir
# 要监控的目录,此目录必须存在
a1.sources.r1.spoolDir =/root/flume/
# 已经完成的文件,会加上一个后缀
a1.sources.r1.fileSuffix =.ok
# 已经完成的文件,会立即删除,默认值是never;(永不删除)
# a1.sources.r1.deletePolicy =immediate
# 是否添加存储绝对路径文件名的标题
a1.sources.r1.fileHeader =true
# 只处理此目录下面的txt文件;
a1.sources.r1.includePattern =^[\\w]+\\.txt$
# Describe the sink
# 描述一个sink: logger日志(打印到控制台上)
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
# 描述一下channel:内存
a1.channels.c1.type = memory
# capacity:容量
a1.channels.c1.capacity = 1000000
# transactionCapacity:事务的容量
a1.channels.c1.transactionCapacity = 1000000
# Bind the source and sink to the channel
# 绑定;source和channel绑定
a1.sources.r1.channels = c1
# sink和channel绑定
a1.sinks.k1.channel = c1


- Sink

Logger
Avro:
Thrift - 连接HDFS
启动hadoop
告诉flume,hadoop装哪了

Linux的环境变量:(vim /etc/profile);新增加内容;(系统的环境变量)vim ~/.bash_profile(用户环境变量)
配置文件(properties)
# flume配置的例子
# Name the components on this agent
# source:起一个别名
# properties文件它是java的配置文件,=左边就是键,=右边是值;键的开头都是以a1(就是flume的名字--agent的名字就是a1);a1随便起
a1.sources = r1
# sink:起一个别名
a1.sinks = k1
# channels;:起一个别名
a1.channels = c1
# Describe/configure the source
# spooldir:监控硬盘上指定的某个目录,如果文件发生变化,会被flume捕获;
a1.sources.r1.type = spooldir
# 要监控的目录,此目录必须存在
a1.sources.r1.spoolDir =/root/flume/
# 已经完成的文件,会加上一个后缀
a1.sources.r1.fileSuffix =.ok
# 已经完成的文件,会立即删除,默认值是never;(永不删除)
# a1.sources.r1.deletePolicy =immediate
# 是否添加存储绝对路径文件名的标题
a1.sources.r1.fileHeader =true
# 只处理此目录下面的txt文件;
a1.sources.r1.includePattern =^[\\w]+\\.txt$
# Describe the sink
# 描述一个sink: logger日志(打印到控制台上)
a1.sinks.k1.type = hdfs
# hdfs的路径;配置hdfs一定要是大哥的路径;(必须是active)
a1.sinks.k1.hdfs.path =hdfs://node-1:8020/flume/%Y-%m-%d/
# 文件的前缀
a1.sinks.k1.hdfs.filePrefix =event
# 文件的后缀
a1.sinks.k1.hdfs.fileSuffix =.txt
# hdfs.inUsePrefix临时文件的前缀,hdfs.inUseSuffix临时文件的后缀
# hdfs.codeC 文件压缩
# 输出原来的文件内容,不要压缩
a1.sinks.k1.hdfs.fileType=DataStream
# 设置文件的格式为textFile
a1.sinks.k1.hdfs.writeFormat=Text
# 如果路径里面有时间,必须要加上hdfs.useLocalTimeStamp=true
a1.sinks.k1.hdfs.useLocalTimeStamp=true
# 时间舍去法
a1.sinks.k1.hdfs.round = true
# 每隔多长时间
a1.sinks.k1.hdfs.roundValue = 20
# 时间单位
a1.sinks.k1.hdfs.roundUnit = second
# roll:滚动
a1.sinks.k1.hdfs.rollInterval=30
# 滚动,新增加的文件大小
a1.sinks.k1.hdfs.rollSize=1024
# 滚动多少行(新增加多少行)
a1.sinks.k1.hdfs.rollCount=10
# Use a channel which buffers events in memory
# 描述一下channel:内存
a1.channels.c1.type = memory
# capacity:容量
a1.channels.c1.capacity = 1000000
# transactionCapacity:事务的容量
a1.channels.c1.transactionCapacity = 1000000
# Bind the source and sink to the channel
# 绑定;source和channel绑定
a1.sources.r1.channels = c1
# sink和channel绑定
a1.sinks.k1.channel = c1


中间产生的临时文件:
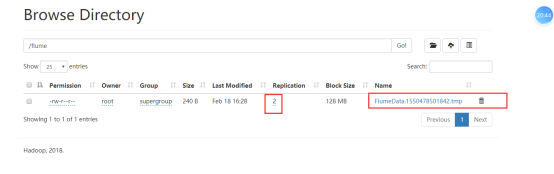
将临时文件改名;

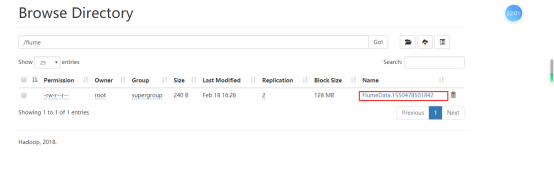
查看文件内容


- 连接hbase
启动hadoop
启动hive
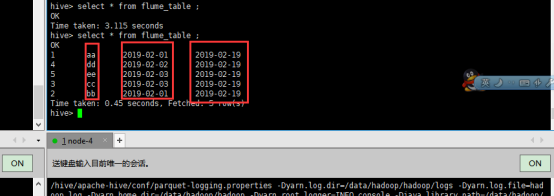
在hive中创建一张表:
create table flume_table
(
id int,
msg string,
-- 年月日,时分秒
createtime string
)
-- 分区;只有年月日
partitioned by (ctime string)
-- 集群,id 放到了5桶里面
clustered by (id) into 5 buckets
-- 存储的格式为orc
stored as orc
tblproperties ("transactional"="true");
准备好一个数据文件(data.txt注意有格式);
1,aa,2019-02-01,
2,bb,2019-02-01,
3,cc,2019-02-03,
4,dd,2019-02-02,
5,ee,2019-02-03,
告诉flume,hive装哪了

配置文件(properties)
# flume配置的例子
# Name the components on this agent
# source:起一个别名
# properties文件它是java的配置文件,=左边就是键,=右边是值;键的开头都是以a1(就是flume的名字--agent的名字就是a1);a1随便起
a1.sources = r1
# sink:起一个别名
a1.sinks = k1
# channels;:起一个别名
a1.channels = c1
# Describe/configure the source
# spooldir:监控硬盘上指定的某个目录,如果文件发生变化,会被flume捕获;
a1.sources.r1.type = spooldir
# 要监控的目录,此目录必须存在
a1.sources.r1.spoolDir =/root/flume/
# 已经完成的文件,会加上一个后缀
a1.sources.r1.fileSuffix =.ok
# 已经完成的文件,会立即删除,默认值是never;(永不删除)
# a1.sources.r1.deletePolicy =immediate
# 是否添加存储绝对路径文件名的标题
a1.sources.r1.fileHeader =true
# 只处理此目录下面的txt文件;
a1.sources.r1.includePattern =^[\\w]+\\.txt$
# Describe the sink
# 采集的是日志(txt);在hive中创建一张表,load data把文件拷贝到指定目录下面,
# 相当于把日志文件中的记录插入到了hive表
# hive
a1.sinks.k1.type =hive
# hive的服务器
a1.sinks.k1.hive.metastore =thrift://node-4:9083
# hive的数据库
a1.sinks.k1.hive.database =mydata
# hive的表名,(这张表一定得存在,需要在hive中创建表)
a1.sinks.k1.hive.table =flume_table
# 配置分区,多个分区使用逗号隔开;time=%Y-%m-%d,a=b,c=d;一个分区的时候名字可以省;分区不是必须配置的
a1.sinks.k1.hive.partition=time-%Y-%m-%d
# useLocalTimeStamp
a1.sinks.k1.useLocalTimeStamp =true
# 采集的数据是文本文件(如果是json文件就填写json)
a1.sinks.k1.serializer =DELIMITED
# 列与列之间的分隔符
a1.sinks.k1.serializer.delimiter=,
# 采集的源文件里面有好几列,到底要使用哪几列的数据
a1.sinks.k1.serializer.fieldnames=id,msg,createtime
# Use a channel which buffers events in memory
# 描述一下channel:内存
a1.channels.c1.type = memory
# capacity:容量
a1.channels.c1.capacity = 1000000
# transactionCapacity:事务的容量
a1.channels.c1.transactionCapacity = 1000000
# Bind the source and sink to the channel
# 绑定;source和channel绑定
a1.sources.r1.channels = c1
# sink和channel绑定
a1.sinks.k1.channel = c1
将hive下面的一个jar包拷贝到flume上
将此包拷贝到flume下面;apache-hive/hcatalog/share/hcatalog/hive-hcatalog-streaming-3.1.1.jar;拷到flume/lib下面


中间产生的临时文件:


- 拦截器

拦截器:去的时候要经过拦截器,出的时候要经过拦截器
搭建一个flume的框架;(souce和sink随便选择);
Flume里面的数据可以修改,是通过拦截器完成的;拦截器可以有多个,执行的顺序和在配置文件中配置的顺序是一样的

配置文件
# flume配置的例子
# Name the components on this agent
# source:起一个别名
# properties文件它是java的配置文件,=左边就是键,=右边是值;键的开头都是以a1(就是flume的名字--agent的名字就是a1);a1随便起
a1.sources = r1
# sink:起一个别名
a1.sinks = k1
# channels;:起一个别名
a1.channels = c1
# Describe/configure the source
# a1(agent的名字).sources(来源).r1(来源的名字);配置多个来源
# type:不能随便写(文档上说明)
a1.sources.r1.type = netcat
# bind:netcat的一个属性(绑定),允许任何人访问
a1.sources.r1.bind = 0.0.0.0
# port:netcat的一个属性;(端口)
a1.sources.r1.port = 44444
# 增加拦截器
a1.sources.r1.interceptors = i1 i2 i3 i4
# 拦截器的类型:(timestamp)
a1.sources.r1.interceptors.i1.type=timestamp
# 拦截器:host
a1.sources.r1.interceptors.i2.type = host
# 拦截器:自定义
a1.sources.r1.interceptors.i3.type = static
a1.sources.r1.interceptors.i3.key = my_key
a1.sources.r1.interceptors.i3.value = my_value
# 查找和替换
a1.sources.r1.interceptors.i4.type = search_replace
# 正则表达式,要查找的字符串;查找的字符串
a1.sources.r1.interceptors.i4.searchPattern = body
# 替换的字符串
a1.sources.r1.interceptors.i4.replaceString = mybody
# Describe the sink
# 描述一个sink: logger日志(打印到控制台上)
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
# 描述一下channel:内存
a1.channels.c1.type = memory
# capacity:容量
a1.channels.c1.capacity = 1000000
# transactionCapacity:事务的容量
a1.channels.c1.transactionCapacity = 1000000
# Bind the source and sink to the channel
# 绑定;source和channel绑定
a1.sources.r1.channels = c1
# sink和channel绑定
a1.sinks.k1.channel = c1
启动命令
bin/flume-ng agent --conf conf --conf-file conf/flume_interceptor.properties --name a1 -Dflume.root.logger=INFO,console
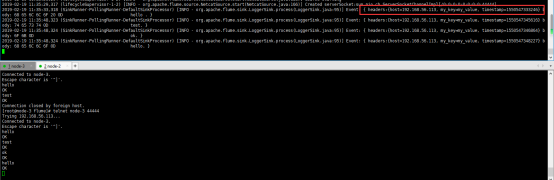
- 高可用
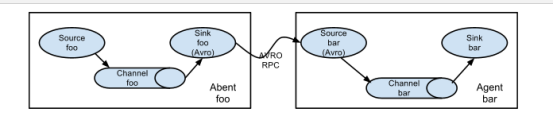

架构

角色
最前线:采集数据
上报给大哥(flume1):
大哥(flume1)把数据存储到hdfs上;(落地)
大哥挂了;(二哥上场去收集数据);所有的最前线采集数据上报给二哥;
虚线的方式:不允许,因为hdfs是一个公司最机密的数据;一旦对外公开,就不安全;(一旦把系统的级别做的特别安全,就相当不方便;要想方便就不安全;)

将flume拷贝到四台服务器上

配置文件
小弟(最前线,webserver-tomcat);(日志:就是一个目录,下面放了好多文件,一天一个,采用的是log4j2;)配置文件:(flume_web_server.properties)(node-1和node-2)
# 分别为source,sinks,channels 起别名
a1.sources = r1
a1.sinks = k1 k2
a1.channels = c1
# 配置source
a1.sources.r1.type = spooldir
# spoolDir:目录
a1.sources.r1.spoolDir = /root/test
# 是否添加存储绝对路径文件名的标题
a1.sources.r1.fileHeader =true
# 只处理此目录下面的txt文件;
a1.sources.r1.includePattern =^[\\w-_]+\\.log$
# set sink1
a1.sinks.k1.type = avro
# 主机名
a1.sinks.k1.hostname = node-3
# 端口
a1.sinks.k1.port = 52020
# set sink2
a1.sinks.k2.type = avro
# 主机名
a1.sinks.k2.hostname = node-4
# 端口
a1.sinks.k2.port = 52020
#配置channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
#set gruop,可以将多个sink合并到一个组里面;
a1.sinkgroups = g1
#set sink group
a1.sinkgroups.g1.sinks = k1 k2
#set failover(zkfc:zookeeper failover control)
#故障转移,若node04故障,node05自动接替node04工作
a1.sinkgroups.g1.processor.type = failover
#优先级(数字越大,越高)
a1.sinkgroups.g1.processor.priority.k1 = 10
#优先级5(数字越大,越高)
a1.sinkgroups.g1.processor.priority.k2 = 5
#最长等待10秒转移故障(单位 是毫秒)
a1.sinkgroups.g1.processor.maxpenalty = 10000
# 绑定
a1.sources.r1.channels = c1
# 绑定
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c1
大哥(flume_1)(node-3)
# agent的名字不能重复
# 分别为source,sinks,channels 起别名
a2.sources = r1
a2.sinks = k1
a2.channels = c1
# avro:数据序列化系统
a2.sources.r1.type = avro
# 主机名
a2.sources.r1.bind = node-3
# 端口号
a2.sources.r1.port = 52020
#增加拦截器 所有events,增加头,类似json格式里的"headers":{" key":" value"}
a2.sources.r1.interceptors = i1
a2.sources.r1.interceptors.i1.type = static
a2.sources.r1.interceptors.i1.key = Collector
a2.sources.r1.interceptors.i1.value = node-3
# 配置sink
a2.sinks.k1.type = hdfs
# hdfs的路径:
a2.sinks.k1.hdfs.path=hdfs://node-1:8020/flume/%Y-%m-%d/
# 写的格式是text
a2.sinks.k1.hdfs.writeFormat=Text
# 此处必须加上
a2.sinks.k1.hdfs.useLocalTimeStamp = true
# 文件的前缀
a2.sinks.k1.hdfs.filePrefix=%H-%M-%S
# hdfs.inUsePrefix临时文件的前缀,hdfs.inUseSuffix临时文件的后缀
# hdfs.codeC 文件压缩
# 输出原来的文件内容,不要压缩
a2.sinks.k1.hdfs.fileType=DataStream
# 文件的后缀
a2.sinks.k1.hdfs.fileSuffix=.txt
# 在等待的30秒以内,如果此文件发生了修改(也会进行拆分)
a2.sinks.k1.hdfs.rollInterval=10
# 滚动,新增加的文件大小(等待时间期间);0:表示不生效
a2.sinks.k1.hdfs.rollSize=0
# 滚动多少行(新增加多少行)(等待时间期间),每隔10行会在hdfs上生成一个新文件;0:表示不生效
a2.sinks.k1.hdfs.rollCount=0
#配置channel
a2.channels.c1.type = memory
a2.channels.c1.capacity = 1000
a2.channels.c1.transactionCapacity = 100
# 将source,和channel绑定起来
a2.sources.r1.channels = c1
# 绑定sink
a2.sinks.k1.channel = c1
二哥(flume_2)–(node-4)
# agent的名字不能重复
# 分别为source,sinks,channels 起别名
a2.sources = r1
a2.sinks = k1
a2.channels = c1
# 配置source
a2.sources.r1.type = avro
# 主机名
a2.sources.r1.bind = node-4
# 端口号
a2.sources.r1.port = 52020
#增加拦截器 所有events,增加头,类似json格式里的"headers":{" key":" value"}
a2.sources.r1.interceptors = i1
a2.sources.r1.interceptors.i1.type = static
a2.sources.r1.interceptors.i1.key = Collector
a2.sources.r1.interceptors.i1.value = node-3
# 配置sink
a2.sinks.k1.type = hdfs
# hdfs的路径:
a2.sinks.k1.hdfs.path=hdfs://node-1:8020/flume/%Y-%m-%d/
# 写的格式是text
a2.sinks.k1.hdfs.writeFormat=Text
# 此处必须加上
a2.sinks.k1.hdfs.useLocalTimeStamp = true
# 文件的前缀
a2.sinks.k1.hdfs.filePrefix=%H-%M-%S
# hdfs.inUsePrefix临时文件的前缀,hdfs.inUseSuffix临时文件的后缀
# hdfs.codeC 文件压缩
# 输出原来的文件内容,不要压缩
a2.sinks.k1.hdfs.fileType=DataStream
# 文件的后缀
a2.sinks.k1.hdfs.fileSuffix=.txt
# 在等待的30秒以内,如果此文件发生了修改(也会进行拆分)
a2.sinks.k1.hdfs.rollInterval=10
# 滚动,新增加的文件大小(等待时间期间);0:表示不生效
a2.sinks.k1.hdfs.rollSize=0
# 滚动多少行(新增加多少行)(等待时间期间),每隔10行会在hdfs上生成一个新文件;0:表示不生效
a2.sinks.k1.hdfs.rollCount=0
#配置channel
a2.channels.c1.type = memory
a2.channels.c1.capacity = 1000
a2.channels.c1.transactionCapacity = 100
#绑定
a2.sources.r1.channels = c1
a2.sinks.k1.channel = c1



在小弟上指定的目录下面传入文件

