不同于传统关系数据库围绕数据先建模再考虑查询,HBase(Cassandra等NOSQL)强调围绕查询进行建模,干什么活做什么设计,海量数据就没必要多余的设计了。
具体总结包含如下三大原则:
反范式很重要
传统关系数据库中,期间遵循数据设计的三大范式,减小数据冗余,彼此间通过关系引用,hbase中要反范式,冗余没有关系,放弃最小化设计,怎么方便怎么来,最简单直观就行。
如下,原先通过引用关系设计的地址信息,在hbase中直接把对应地址存储在以Name为Rowkey的列信息中。查询所有地址信息,可以直接指定rowkey查询,查询某个地址是否存在直接指定Name和对应的地址列即可,总之直接按照多维数据表操作即可。
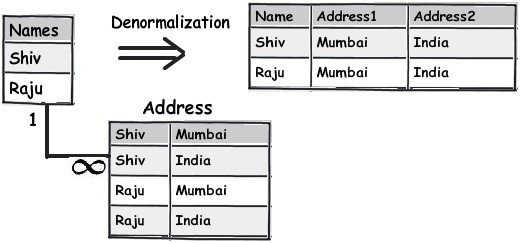
不用区分行和列
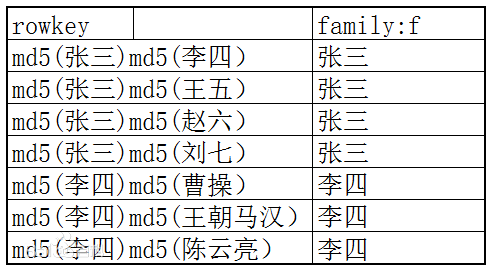
关系数据库中,索引用来快速查找数据,对应值保存在记录中。在hbase中索引(行键)和列都可以存储数据,更加类似关系数据库中的组合索引。如下,分别为被关注-关注者对应的宽表和高表

顾名思义,宽表尽量把数据存储在一行中,看起来宽度比较高,它很简单,要查谁关注了张三,直接指定行键为张三同时取多键值对即可。但是注意,hbase中数据存储最小单元为行,之前我们讲过每个列族的数据存在一个HFile中,这里如果张三的关注者远比别人多,救护造成一个HFile急剧增大,多个Region数据量不一致,导致数据倾斜,可能一台机器存储会爆炸,且查询写入速度页急剧下降。
再看高表,是尽量把数据存储在多行中,有点类似关系数据库,但是由于hbase的查询主要依赖索引的定位,所以高表的数据只要是存储在行键中的,考验的是行键组合索引的设计,图中需要查看谁关注了张三那就需要指定开始行键为md5(张三)结束,指定结束行键为md5(李四),按照前缀查找的方式获得对应的关注者列表。可以看到高表完全依赖行键定位效率更高,分布也均匀,但是需要合理设计组合索引,相对来说使用麻烦点。
牢记有序和行键设计
可以说,hbase中行键设计核心,查的快不快和怎么查完全依赖rowkey的设计,具体来说包括如下两方面:
key均匀化
hbase按照字典序将列族数据均匀化分布到不同的region中,必须保证key均匀才能做到数据不倾斜,存储和查询写入效率最高。
关于key均匀化以监控数据来统计,如果按照天作为rowkey来统计,默认按照字典序从前往后来看,数据是集中的
20180301
20180302
20180303
20180304
考虑如下均匀化方案
- 加盐(Salting)
比如按照奇偶添加不同前缀,这样的好处是数据有序散开,而且范围查找还可以并行读写,缺点就是需要人工去控制对应的范围并发查找逻辑
020180301
020180303
120180302
120180304
- 随机键
比如直接对数据取md5,数据会无序散开,直接定位效率高,但是范围查找性能低
hash1
hash2
hash3
hash4
- 提升字段
考虑叫rowkey变化大的部分提前,比如倒序或求差,这样的好处在于完整的保留有序特性
10308102
20308102
30308102
40308102
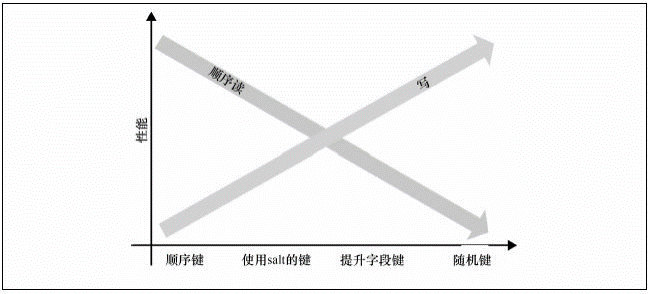
总的来说,集中方案各有利弊,有人总结了如下关系图,顺序读就是范围查找,写就是随机读写特性。
组合key(索引)设计
另外,就是之前高表中说的组合key设计,它强调尽量将查询的维度或信息存储在行键,筛选数据的效率最高。这需要按照查找业务逻辑设计索引,牢记hbase的有序特性。
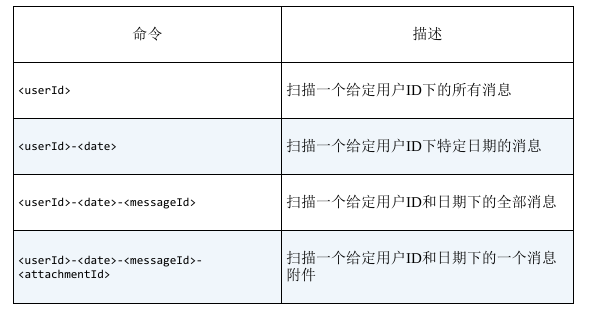
如下,现有用户的电子邮件信息表,配合扫描取数据,可指定起始键设为12345(假设ID),终止键设为123456来取数据,不同的业务需求可逐次设计组合key如下,注意不同的行的rowkey对应部分长度必须相同,这样才能保证rowkey始终按照理想的字典序排列。
原创,转载请注明来自