版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/wenzhou1219/article/details/88919999
原理
Hadoop的文件存储的单元为一个块(block),block的数据存放在集群中的datanode节点上,由namenode对所有datanode存储的block进行管理。每个文件对应的block块信息称为元数据,这些数据保存在namenode上。如果存在大量小文件,会导致namenode上的元数据急剧膨胀,而这些元数据一般存放在namenode内存中,以方便快速的响应客户端的请求,因此大量的小文件元信息会把namenode的内存耗尽。
为了解决这个问题,Hadoop提供了一个叫Archive归档工具,Archive可以把多个文件归档成为一个文件。归档文件中包含元数据信息和小文件内容,将Namenode管理的元数据信息保存到Datanode上的归档文件中,避免元数据的膨胀,大大降低namenode 守护节点的内存压力。
如下图,归档的文件会被合并放到part-中管理,每个part-管理的文件索引放在_index和_materindex中。

命令使用方式
-
创建归档文件
-
- hadoop archive -archiveName name -p <parent> [-r <replication>] <src…> <dest>
-
- -archiveName 指定归档结果名称,以har结尾
-
- -p 归档源文件父目录,可通过src指定多个待归档文件,不指定文件时归档整个目录
-
- dest 归档结果保存位置
-
- -r 默认为10,官方给的意思为复制因子,实在没搞懂,有清楚的麻烦留言说明下。
-
查看归档文件结构
-
- hadoop fs -ls har:///archivepath/fileinarchive
-
解压归档文件
-
- hdfs fs -cp har:///user/zoo/foo.har/dir1 hdfs:/user/zoo/newdir
-
- hadoop distcp har:///user/zoo/foo.har/dir1 hdfs:/user/zoo/newdir
演示
如下文件

文件内容分别是
file 1
file 2
file 3
执行如下命令归档
hadoop archive -archiveName test.har -p /home/hdp-jiagu/wenzhou/test -r 3 1.data 2.data 3.data /home/hdp-jiagu/wenzhou/archive
生成目录如下

查看各个文件内容
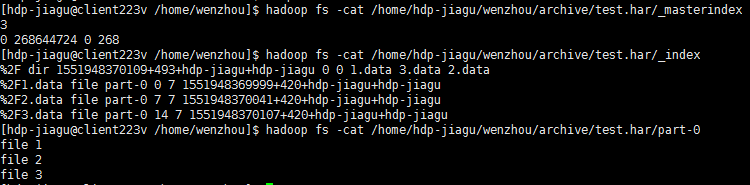
可以发现part-0文件内容是三个小文件内容合并的,索引_index中标记每个小文件的文件名和块中偏移位置和大小。
可使用har://协议查看归档文件结构和内容,如下

不足
不足的地方:
- 1、archive文件本占用与原文件相同的硬盘空间;
- 2、archive文件不支持压缩;
- 3、archive一旦创建就不能进行修改;
- 4、archive虽然解决了namenode的空间问题,但是,在执行mapreduce时,会把多个小文件交给同一个map去split,这可能会降低mapreduce的效率,另外创建HAR和解压HAR依赖MapReduce,查询文件时耗很高。
原创,转载请注明来自