目录
0. 简介
0.1 缓存收益和场景
缓存能够有效地加速应用的读写速度,同时也可以降低后端负载,对日常应用的开发至关重要。
下图左侧为客户端直接调用存储层的架构,右侧为比较典型的缓存层+存储层架构
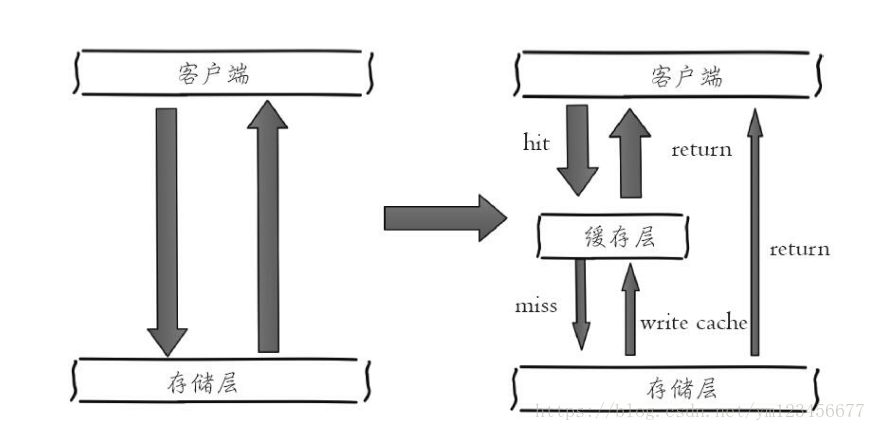
缓存比较常用的选型,缓存层选用Redis,存储层选用MySQL。
缓存加入后带来的收益和成本。
收益
- 加速读写:因为缓存通常都是全内存的,而存储层通常读写性能不够强悍(例如MySQL),通过缓存的使用可以有效地加速读写,优化用户体验。
- 降低后端负载:帮助后端减少访问量和复杂计算(例如很复杂的SQL语句),在很大程度降低了后端的负载
成本
- 数据不一致性:缓存层和存储层的数据存在着一定时间窗口的不一致性,时间窗口跟更新策略有关。
- 代码维护成本:加入缓存后,需要同时处理缓存层和存储层的逻辑,增大了开发者维护代码的成本。
- 运维成本:以Redis Cluster为例,加入后无形中增加了运维成本。
缓存的使用场景基本包含如下两种:
- 开销大的复杂计算:以MySQL为例子,一些复杂的操作或者计算(例如大量联表操作、一些分组计算),如果不加缓存,不但无法满足高并发量,同时也会给MySQL带来巨大的负担。
- 加速请求响应:即使查询单条后端数据足够快(例如select*from tablewhere id=),那么依然可以使用缓存,以Redis为例子,每秒可以完成数万次读写,并且提供的批量操作可以优化整个IO链的响应时间。
0.2 缓存更新策略
缓存中的数据会和数据源中的真实数据有一段时间窗口的不一致,需要利用某些策略进行更新,下面会介绍几种主要的缓存更新策略。
- LRU/LFU/FIFO算法剔除
剔除算法通常用于缓存使用量超过了预设的最大值时候,如何对现有的数据进行剔除。例如Redis使用maxmemory-policy这个配置作为内存最大值后对于数据的剔除策略。
- 超时剔除
通过给缓存数据设置过期时间,在过期时间后自动删除,例如Redis提供的expire命令。如果业务可以容忍一段时间内,缓存层数据和存储层数据不一致,那么可以为其设置过期时间。在数据过期后,再从真实数据源获取数据,重新放到缓存并设置过期时间。例如一个视频的描述信息,可以容忍几分钟内数据不一致,但是涉及交易方面的业务,后果可想而知。
- 主动更新
应用方对于数据的一致性要求高,需要在真实数据更新后,立即更新缓存数据。例如可以利用消息系统或者其他方式通知缓存更新。

建议:
- 低一致性业务建议配置最大内存和淘汰策略的方式使用。
- 高一致性业务可以结合使用超时剔除和主动更新,这样即使主动更新出了问题,也能保证数据过期时间后删除脏数据;
1. 概述
缓存(Caching)可以存储经常会用到的信息,这样每次需要的时候,这些信息都是立即可用的。
常用的缓存数据库:
- Redis 使用内存存储(in-memory)的非关系数据库,字符串、列表、集合、散列表、有序集合,每种数据类型都有自己的专属命令。另外还有批量操作(bulk operation)和不完全(partial)的事务支持 、发布与订阅、主从复制(master/slave replication)、持久化、脚本(存储过程,stored procedure)。 效率比ehcache低,比数据库要快很多,处理集群和分布式缓存方便,有成熟的方案。如果是大型系统,存在缓存共享、分布式部署、缓存内容很大的,建议用redis。
- memcached 使用内存存储的键值缓存,键值之间的映射、创建命令、读取命令、更新命令、删除命令以及其他几个命令。为提升性能而设的多线程服务器。memcache在客户端中实现分布式缓存,通过分布式算法指定目标数据的节点。
- ehcache 纯java实现,缓存在内存中,可持久化到硬盘,效率高于memcache;但是缓存共享麻烦,集群分布式应用不方便。如果是单个应用或者对缓存访问要求很高的应用,用ehcache。ehcache也有缓存共享方案,不过是通过RMI或者Jgroup多播方式进行广播缓存通知更新,缓存共享复杂,维护不方便;简单的共享可以,但是涉及到缓存恢复,大数据缓存,则不合适。
2. Spring Cache
Spring 缓存的实现是通过创建一个切面(aspect)并触发Spring缓存注解的切点(pointcut)。根据所使用的注解以及缓存的状态,这个切面会从缓存中获取数据,将数据添加到缓存之中或者从缓存中移除某个值。
2.1 Spring与缓存实现进行集成
Spring 能都与多个流行的缓存实现进行集成,实现步骤如下:
2.1.1 启用对缓存的支持
- Java 配置 注解驱动缓存
使用注解:@EnableCaching
- XML 声明的缓存
----<cache:annotation-driven>
2.1.2 缓存管理器
缓存管理器是Spring缓存抽象的核心,它能够与多个流行的缓存实现进行集成。Spring3.1配置了五个缓存管理器实现:
- SimpleCacheManager
- NoOpCacheManager
- ConcurrentMapCacheManager(它的缓存存储是基于内存的,所以它的生命周期是与应用关联的,对于生产级别的大型企业级应用程序,这可能并不是理想的选择)
- CompositeCacheManager(系统同时使用多个缓存管理器集成)
- EhCacheCacheManager
除了核心的Spring框架,Spring Data又提供了两个缓存管理器:
- RedisCacheManager--Spring Data Redis提供
- GemfireCacheManager
2.1.3 为方法添加注解以支持缓存
Spring 提供的四个注解来声明缓存规则:

- @Cacheable会条件性地触发对方法的调用,这取决于缓存中是不是已经有了所需要的值。
- @CachePut采用了一种更为直接的流程。带有@CachePut注解的方法始终都会被调用,而且它的返回值也会放到缓存中。
@Cacheable 和 @CachePut 一些共有的属性:

- value:value属性是必须指定的,其表示当前方法的返回值是会被缓存在哪个Cache上的,对应Cache的名称。主要作用是给 cache 取个名称!个人觉得,主要是为了在Spring 容器中可以更好的管理缓存对象。
- condition
- 调用方法前:如果SPEL表达式的值为false的话,将不会去走缓存。
- 调用方法后:如果SPEL表达式的值为false的话,将不会将返回值放在缓存中。。
- unless
- 调用方法前:不进行判断。
- 调用方法后:如果SPEL表达式的值是true的话,将不会将返回值放在缓存中。
- key:指定的key的值就是我们要保存到缓存数据库中的key的值,但是这个key的指定有自己的一套方式,如下:



另外,需要说明的是 #result 不能用在@Cacheable 上是因为 #result 表示的是 方法调用的返回值。但是@Cacheable 可能不走方法,可能不会有返回值。所以就不太适用了。但是!但是!#result 可以用在@Cacheable的 unless 属性上,因为 unless 是在方法返回的时候再判断的,所以一定会有返回值!
3. @CacheEvict 的一些属性,指定了哪些缓存数目应该被移除:

@CacheEvict 主要用在要移除一个数据条目的时候,同时移除这个数据条目在缓存中的 key 和 value。
4. @Cacheing
@Caching注解可以让我们在一个方法或者类上同时指定多个Spring Cache相关注解,其中拥有属性:cacheable、put、evict。
@Caching(cacheable=@Cacheable("users"),evict={@CacheEvict("cache2"),@CacheEvict(value="cache3",allEntries=true)})3. 使用Redis缓存
Spring Data Redis包含了多个模板实现,用来完成Redis数据库的数据存取功能。
<!-- 配置连接池 -->
<bean id="poolConfig" class="redis.clients.jedis.JedisPoolConfig">
<property name="maxIdle" value="50"/>
<property name="maxTotal" value="100"/>
<property name="maxWaitMillis" value="20000"/>
</bean>
<!-- 配置连接工厂 -->
<bean id="connectionFactory" class="org.springframework.data.redis.connection.jedis.JedisConnectionFactory">
<property name="hostName" value="localhost"/>
<property name="port" value="6379"/>
<property name="poolConfig" ref="poolConfig"/>
</bean>
<!-- 键值序列化器 -->
<bean id="stringRedisSerializer" class="org.springframework.data.redis.serializer.StringRedisSerializer"/>
<bean id="jdkSerializationRedisSerializer" class="org.springframework.data.redis.serializer.JdkSerializationRedisSerializer"></bean>
<!-- 配置redisTemplate -->
<bean id="redisTemplate" class="org.springframework.data.redis.core.RedisTemplate">
<property name="connectionFactory" ref="connectionFactory"/>
<!-- 设置默认的序列化器为字符串序列化 -->
<property name="defaultSerializer" ref="stringRedisSerializer"/>
<property name="keySerializer" ref="stringRedisSerializer"/>
<property name="valueSerializer" ref="jdkSerializationRedisSerializer"/>
<property name="hashKeySerializer" ref="stringRedisSerializer"/>
<property name="hashValueSerializer" ref="jdkSerializationRedisSerializer"/>
</bean>
<!-- 使用注解驱动,其中属性cache-manager默认值为cacheManager -->
<cache:annotation-driven cache-manager="redisCacheManager"/>
<!-- 定义缓存管理器 -->
<bean id="redisCacheManager" class="org.springframework.data.redis.cache.RedisCacheManager">
<!-- 通过构造方法注入redisTemplate -->
<constructor-arg index="0" ref="redisTemplate"/>
<!-- 定义默认超时时间 -->
<property name="defaultExpiration" value="600"/>
<!-- 缓存管理器名称 -->
<property name="cacheNames">
<list>
<value>redisCacheManager</value>
</list>
</property>
</bean>3.1 添加依赖
在Spring中使用Redis需要jedis.jar和spring-data-redis.jar
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-redis</artifactId>
<version>1.8.7.RELEASE</version>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
</dependency>3.2 配置连接池
配置了Redis数据库连接池的最大闲置连接数、最大连接数和最长等待时间;
3.3 Redis连接工厂
redis连接工厂会生成到Redis数据库服务器的连接。配置了Redis数据库的主机和端口号,同时引入了之前配置的连接池;
有四种Redis连接工厂:
- JedisConnetionFactory
- JredisConnectionFactory
- LettuceConnectionFactory
- SrpConnectionFactory
3.4 配置RedisTemplate
redisTemplate封装了对redis的操作,要操作redis,则肯定要引入上面配置好的连接工厂和序列化器;
- Spring Data Redis提供了两个模版
- RedisTemplate
- StringRedisTemplate
RedisTemplate 支持 Object类型 的key 和 Object类型 的value。而StringRedisTemplate则采用更简单粗暴的方式,只支持 String类型 的key 和String类型 的value。
- 需要注入Redis连接工厂bean;
- 需要注入序列化器bean
3.5 key 和 value 的序列化器
什么是序列化器呢?当某个条目保存到Redis key-value存储的时候,key和value都会使用Redis的序列化器进行序列化。由于Redis只能提供基于字符串型的操作,而在java中是以类和对象为主,序列化器的作用是将java对象和Redis字符串相互转换,使得可以将java对象序列化为字符串存入Redis,同时也可以取出Redis序列化过的字符串转换成java对象
Spring Data Redis提供了多个这样的序列化器,包括:
- GenericToStringSerializer:使用Spring转换服务进行序列化;
- JacksonJsonRedisSerializer:使用Jackson 1,将对象序列化为JSON;
- Jackson2JsonRedisSerializer:使用Jackson 2,将对象序列化为JSON;
- JdkSerializationRedisSerializer:使用Java序列化;
- OxmSerializer:使用Spring O/X映射的编排器和解排器(marshaler和unmarshaler)实现序列化用于XML序列化;
- StringRedisSerializer:序列化String类型的key和value。
RedisTemplate会使用JdkSerializationRedisSerializer,这意味着key和value都会通过Java进行序列化。StringRedisTemplate默认会使用StringRedisSerializer。
RedisTemplate 的 key 和 value 经过序列化存储可能会让你觉得奇怪,类似如下:

这是正常的,因为使用的是 java 的序列化,如果想要看起来比较舒服的,可以用 StringRedisSerializer 序列成字符串的样子。
3.6 启用对缓存的支持
注解驱动的缓存:<cache:annotation-driven>会启动注解驱动的缓存,会创建一个切面(aspect),并触发Spring缓存注解的切点(pointcut)。根据所使用的注解以及缓存的状态,切面会从缓存中获取数据,将数据添加到缓存中,或者从缓存中移除某个值。
3.7 配置缓存管理器
有了对redis的操作,接下来就是要将spring缓存机制和redis进行结合(即配置缓存管理器),缓存管理器中我们注入了redisTemplate,同时设置了超时时间和管理器的名称。
3.8 RedisTemplate API
Spring Data Redis 提供了一套API 友好的操作Redis,如下:

