PS.各位大虾,小弟初来咋到,如有不足,敬请谅解,还需各位大虾一一指教出来。
首先,数据库连接池负责分配、管理和释放数据库连接,它允许应用程序重复使用一个现有的数据库连接,而不是再重新建立一个;释放空闲时间超过最大空闲时间的数据库连接来避免因为没有释放数据库连接而引起的数据库连接遗漏。这项技术能明显提高对数据库操作的性能。(ps.百度百科)
先说说数据库连接池的流程,首先是配置文件包含(数据库连接地址,数据库用户名,数据库密码,数据库驱动,连接池数量,开始初始化数量,自动增长数量)这些内容。
然后读取配置文件,初始化线程池,获取连接池中连接使用时更改其状态,如连接池中连接不够用则自动创建对应配置文件中数量的连接,并判断是否超过连接池最大数量,当连接使用完后,重新将连接放入池中供其他线程使用,从而达到可复用的效果,下面有使用连接池和没有使用连接池的对比测试。好了,废话不多说,直接上代码:
1. 首先配置文件
对应的数据库的各种信息,以及数据库连接池初始化时数量,最大连接数量以及自动增长数量:
jdbcDriver = com.mysql.jdbc.Driver jdbcUrl = jdbc:mysql://localhost:3306/boot?useUnicode=true&characterEncoding=UTF-8 username = root password = 123456 initConnectCount = 20 maxConnects = 100 incrementCount = 3
2.封装一个连接类
该类中包含一个数据库连接,一个是否使用的标记以及一个close方法,用来将该连接置为可用状态,从而达到数据库连接的可复用,减少持续创建新连接的资源消耗
package com.example.demo.pool; import java.io.IOException; import java.io.InputStream; import java.sql.*; import java.util.Properties; import java.util.Vector; /** * 连接类 * * @author Administrator */ public class PoolConnection { /** * 数据库连接 */ private Connection conn = null; /** * 标记该连接是否使用 */ private boolean isUse = false; /* * 构造方法 * */ public PoolConnection(Connection conn, boolean isBusy) { this.conn = conn; this.isUse = isBusy; } /** * 查询实现 */ public ResultSet queryBySql(String sql) { Statement sm = null; ResultSet rs = null; try { sm = conn.createStatement(); rs = sm.executeQuery(sql); } catch (SQLException e) { e.printStackTrace(); } return rs; } public Connection getConn() { return conn; } public void setConn(Connection conn) { this.conn = conn; } public boolean isUse() { return isUse; } public void setUse(boolean use) { isUse = use; } /** * 将该连接置为可用状态 */ public void close() { this.isUse = false; } }
3.连接池接口
对外提供的连接池的接口
package com.example.demo.pool; import java.sql.Connection; public interface IPool { /** * 获取连接池中可用连接 * */ PoolConnection getConnection();
/**
* 获取一个数据库连接(不使用连接池)
* */
Connection getConnectionNoPool();
}
4.连接池实现类以及对应方法
首先加载对应配置文件中信息,初始化数据库连接池,然后用synchronized来实现多线程情况下线程安全的获取可用连接

package com.example.demo.pool; import java.io.IOException; import java.io.InputStream; import java.sql.Connection; import java.sql.Driver; import java.sql.DriverManager; import java.sql.SQLException; import java.util.Properties; import java.util.Vector; /** * @author Administrator */ public class JdbcPool implements IPool { private static String jdbcDriver; private static String jdbcUrl; private static String username; private static String password; private static Integer initConnectCount; private static Integer maxConnects; private static Integer incrementCount; private static Vector<PoolConnection> connections = new Vector<>(); /** * 通过实例初始化块来初始化 * */
{
//读取对应的配置文件,加载入properties中,并设置到对应的参数中 InputStream is = JdbcPool.class.getClassLoader().getResourceAsStream("jdbc.properties"); Properties properties = new Properties(); try { properties.load(is); } catch (IOException e) { e.printStackTrace(); } jdbcDriver = properties.getProperty("jdbcDriver"); jdbcUrl = properties.getProperty("jdbcUrl"); username = properties.getProperty("username"); password = properties.getProperty("password"); initConnectCount = Integer.valueOf(properties.getProperty("initConnectCount")); maxConnects = Integer.valueOf(properties.getProperty("maxConnects")); incrementCount = Integer.valueOf(properties.getProperty("incrementCount")); try { /* * 注册jdbc驱动 * */ Driver driver = (Driver) Class.forName(jdbcDriver).newInstance(); DriverManager.registerDriver(driver); /* * 根据initConnectCount来初始化连接池 * */ createConnections(initConnectCount); } catch (ClassNotFoundException e) { e.printStackTrace(); } catch (InstantiationException e) { e.printStackTrace(); } catch (IllegalAccessException e) { e.printStackTrace(); } catch (SQLException e) { e.printStackTrace(); } } /** * 获取可用连接 * */ @Override public PoolConnection getConnection() { if (connections.isEmpty()) { System.out.println("连接池中没有连接"); throw new RuntimeException("连接池中没有连接"); } return getActiveConnection(); } /** * 同步方法来获取连接池中可用连接,在多线程情况下,只有一个线程访问该方法来获取连接,防止由于多线程情况下多个线程获取同一个连接从而引起出错 */ private synchronized PoolConnection getActiveConnection() { /* * 通过循环来获取可用连接,若获取不到可用连接,则依靠无限循环来继续获取 * */ while (true) { for (PoolConnection con : connections) { if (!con.isUse()) { Connection trueConn = con.getConn(); try { //验证连接是否失效 0表示不校验超时 if (!trueConn.isValid(0)) { con.setConn(DriverManager.getConnection(jdbcUrl, username, password)); } } catch (SQLException e) { e.printStackTrace(); } con.setUse(true); return con; } } /* * 根据连接池中连接数量从而判断是否增加对应的数量的连接 * */ if (connections.size() <= maxConnects - incrementCount) { createConnections(incrementCount); } else if (connections.size() < maxConnects && connections.size() > maxConnects - incrementCount) { createConnections(maxConnects - connections.size()); } } } /* * 创建对应数量的连接并放入连接池中 * */ private void createConnections(int count) { for (int i = 0; i < count; i++) { if (maxConnects > 0 && connections.size() >= maxConnects) { System.out.println("连接池中连接数量已经达到最大值"); throw new RuntimeException("连接池中连接数量已经达到最大值"); } try { Connection connection = DriverManager.getConnection(jdbcUrl, username, password); /* * 将连接放入连接池中,并将状态设为可用 * */ connections.add(new PoolConnection(connection, false)); } catch (SQLException e) { e.printStackTrace(); } } } /* * 获取连接池中连接数量 * */ public int getSize() { return connections.size(); }
@Override
public Connection getConnectionNoPool() {
Connection connection = null;
try {
connection = DriverManager.getConnection(jdbcUrl, username, password);
} catch (SQLException e) {
e.printStackTrace();
}
return connection;
}
}
4.连接池维护类(单例模式)
通过静态内部类来实现连接池的单例模式
package com.example.demo.pool; /** * @author Administrator */ public class PoolManager { /** * 静态内部类实现连接池的单例 * */ private static class CreatePool{ private static JdbcPool pool = new JdbcPool(); } public static JdbcPool getInstance(){ return CreatePool.pool; } }
最后,上测试方法:我起了2000个线程,通过new两个CountDownLatch(不懂的,问度娘,就不一一解释了)其中一个来实现线程的同时并发执行,不要问为什么是2000不是20000,因为20000个线程本人的渣电脑直接OOM了,所以就2000个测试,然后通过调用另外一个CountDownLatch的await方法来实现等待所有线程全完成从而统计总共花费时间。
熟话说,没有对比就没有伤害,我们先来用普通没有连接池的测试一下2000个连接并行执行的时间,代码如下:
package com.example.demo.pool; import java.sql.Connection; import java.sql.ResultSet; import java.sql.SQLException; import java.sql.Statement; import java.util.concurrent.CountDownLatch; /** * @author Administrator */ public class JdbcNoPoolMain { static final int threadSize = 2000; static JdbcPool jdbcPool = PoolManager.getInstance(); static CountDownLatch countDownLatch1 = new CountDownLatch(1); static CountDownLatch countDownLatch2 = new CountDownLatch(threadSize); public static void main(String[] args) throws InterruptedException { threadTest(); } public static void threadTest() throws InterruptedException { long time1 = System.currentTimeMillis(); for (int i = 0; i < threadSize; i++) { new Thread(new Runnable() { @Override public void run() { try { //使得线程阻塞到coutDownLatch1为0时才执行 countDownLatch1.await(); selectNoPool(); //每个独立子线程执行完后,countDownLatch2减1 countDownLatch2.countDown(); } catch (InterruptedException e) { e.printStackTrace(); } catch (SQLException e) { e.printStackTrace(); } } }).start(); } //将countDownLatch1置为0,从而使线程并发执行 countDownLatch1.countDown(); //等待countDownLatch2变为0时才继续执行 countDownLatch2.await(); long time2 = System.currentTimeMillis(); System.out.println("thread size: "+threadSize+" no use pool :" + (time2 - time1)); } public static void selectNoPool() throws SQLException { Connection conn = jdbcPool.getConnectionNoPool(); Statement sm = null; ResultSet rs = null; try { sm = conn.createStatement(); rs = sm.executeQuery("select * from user"); } catch (SQLException e) { e.printStackTrace(); } try { while (rs.next()) { System.out.println(Thread.currentThread().getName() + " ==== " + "name: " + rs.getString("name") + " age: " + rs.getInt("age")); } Thread.sleep(100); } catch (SQLException e) { e.printStackTrace(); } catch (InterruptedException e) { e.printStackTrace(); } rs.close(); sm.close(); conn.close(); } }
下图显示运行显示2000个线程同时并发运行花费24080ms
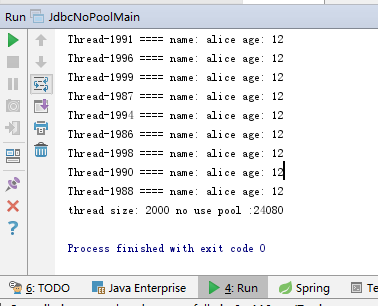
下面是使用数据库连接池的测试类:
package com.example.demo.pool; import java.sql.ResultSet; import java.sql.SQLException; import java.util.concurrent.CountDownLatch; /** * @author Administrator */ public class JdbcPoolMain { static final int threadSize = 2000; static JdbcPool jdbcPool = PoolManager.getInstance(); static CountDownLatch countDownLatch1 = new CountDownLatch(1); static CountDownLatch countDownLatch2 = new CountDownLatch(threadSize); public static void main(String[] args) throws InterruptedException { threadTest(); } public static void select() throws SQLException { PoolConnection conn = jdbcPool.getConnection(); ResultSet rs = conn.queryBySql("select * from user"); try { while(rs.next()){ System.out.println(Thread.currentThread().getName()+" ==== "+"name: "+rs.getString("name")+" age: "+rs.getInt("age")); } Thread.sleep(100); } catch (SQLException e) { e.printStackTrace(); } catch (InterruptedException e) { e.printStackTrace(); } rs.close(); conn.close(); } public static void threadTest() throws InterruptedException { long time1 = System.currentTimeMillis(); for(int i=0;i<threadSize;i++){ new Thread(new Runnable() { @Override public void run() { try {
//阻塞到当countDownLatch1为0才执行 countDownLatch1.await(); select();
//将countDownLatch2减1 countDownLatch2.countDown(); } catch (InterruptedException e) { e.printStackTrace(); } catch (SQLException e) { e.printStackTrace(); } } }).start(); } //将countDownLatch1减1,从而使所有子线程同时并发执行 countDownLatch1.countDown(); //等待countDownLatch2为0时继续执行 countDownLatch2.await(); long time2 = System.currentTimeMillis(); System.out.println("pool size:"+jdbcPool.getSize()); System.out.println("thread size: "+threadSize+" use pool :" + (time2 - time1)); } }
运行结果如下,2000个线程同时并发运行,花费了6065ms,是没有使用线程池的1/4,并且显示线程执行完后池中连接数量为74,还没有达到100,从而知道2000个线程获取连接基本都是连接的复用已存在的连接,从而提高代码效率。
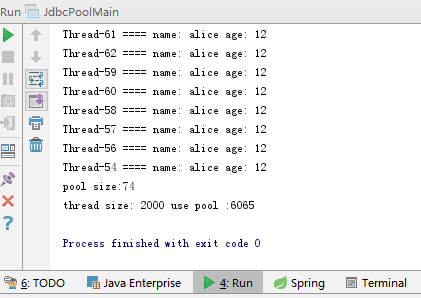
以上就是一个简单的java数据库连接池的实现,当然还有很多不足之处,例如没有对连接池动态回收之类的,当并发少时,连接池中连接数量还是维持在峰值,进行获取连接时候获取的前面的连接,从而使的连接池中后面的连接获取不到,造成资源的浪费等等。。。