背景故事:
公司的MySQL数据库关联太复杂了,结构难缠,关系混乱,为了后续项目的方便查询,老板交代,需要将MySQL的数据全部迁移至MongoDB中去。
这MySQL数据量大概在40M左右,数据量5w+,说起来不算太大,如果一条一条的读取迁移,任务也能完成,具体实施起来,效率就是慢的一批。果断转换思路。
ε=(´ο`*)))唉,想当年也是操作数据库的一把好手,不曾想,在这爬虫领域逍遥自在了许久,竟忘了这前世的情缘。(咳咳咳!扯远了)
回归正题,单条迁移,效率不太理想,那就来个步子大一点的方法,批量迁移数据。
具体实施的思路是:
1.查询MySQL数据库,获取数据。
2.将数据插入Monodb
难点总结:
查询MySQL数据库的问题在于,每次获取多少条的数据,最终目的是为了获取所有数据,但是也得考虑内存的负荷,如果数据量过大的话,电脑直接宕机了。
MongoDB对于插入的数据类型有要求,需要将查询出的数据统一成MongoDB能够接收的类型。
下面就让我们来一起揭开数据批量迁移的神秘面纱吧
上代码:
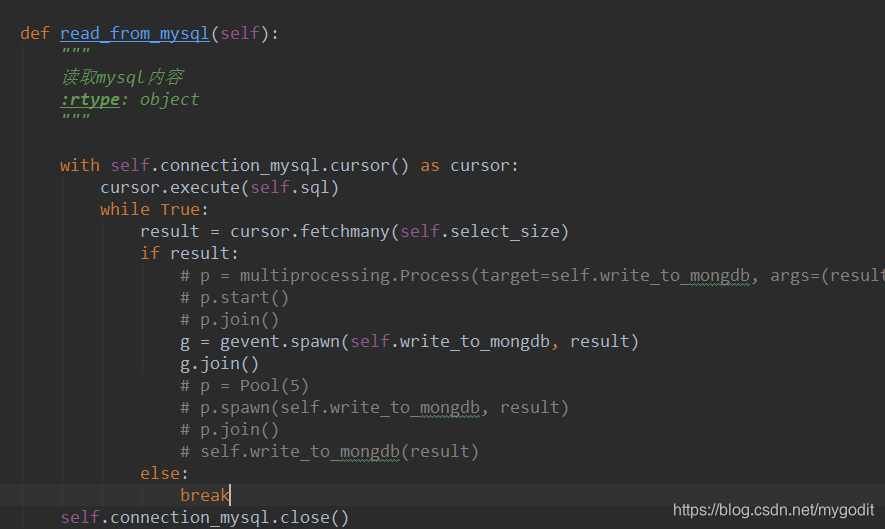
pymysql中获取数据的方法有fetchone,fetchmany,fetchall,三种方法,fetch_one每次获取一条数据;fetchmany可以指定获取的数量,默认是1条;fetchall获取所有数据,这个方法要慎用,数据量小不影响,数据量大的话,估计得等个十年八年的。
所以我们选择fetchmany来批量获取数据,fetchmany相较于fetchall来说,因为可以指定单次获取的数量,每次查询内存中缓存的都是当前查询的数量大小,不会造成挤爆内存的问题。而且不用等所有数据都获取完才能执行下一步的处理操作,效率也是很不错的。
为了读取MySQL中的全部数据,加一个循环执行fetchmany,读取完成以后再推出循环,保证读完数据库。
第二个问题,关于插入MongoDB的数据格式统一:
正常的方法是将查询到的数据设置key,转换成对应的字典类型,这个方法还是有点太low了。有没有更方便,快捷一点的方法呢?
答案当然是有的,
pymysql在链接MySQL数据库的时候可以设置一些参数来影响数据库的格式,比如charset设置数据库的编码格式,
还有一个参数cursorclass则是用来设置数据库查询显示的数据格式的。
将cursorclass设置成pymysql.cursors.DictCursor,每次读取MySQL获取到的数据就是dict格式。很神奇。
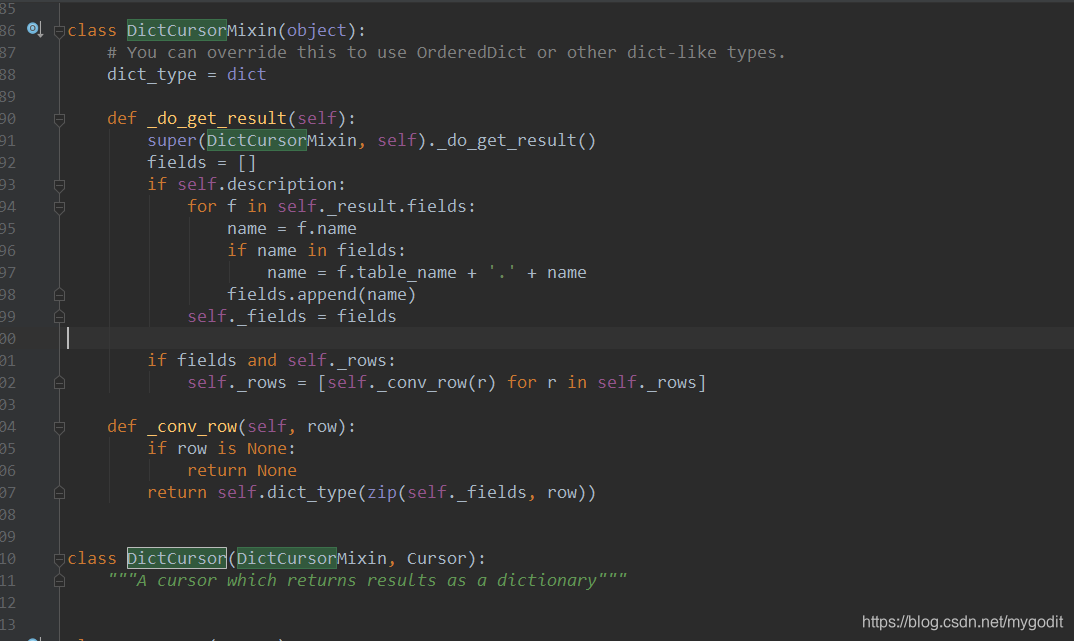
源码中的DictCrusor注释是:以字典形式返回结果的游标。
数据格式统一了,接下来就是将数据插入MongoDB了,MongoDB插入数据的方式insert_one,insert_many
insert_one插入的是字典类型insert_one({});
insert_many插入的则是列表类型,列表中的每个元素都是字典,insert_many([{},{}]).
我们在前面获取MySQL数据时使用的是fetchmany方法,每次执行获取的也是一个列表,数据又是字典格式。那个方法效率更好一点当然显而易见了。
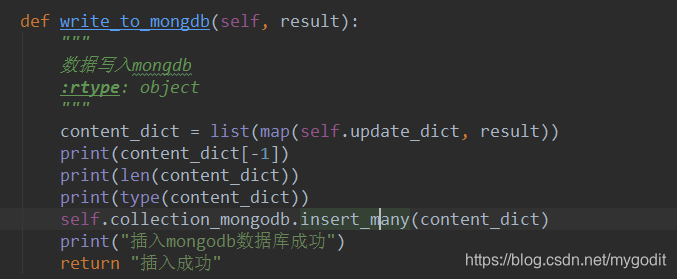
至此,MySQL的数据已经能顺利迁移至MongoDB了。
4k+的时间差不多的在4分钟左右,4w+ 40分钟,40w+ 400分钟。。。。。。
啧啧啧,感觉还是有点慢的,如果大家迁移数据库有更好的方法,第三方库,或者工具可以交流交流。