sql加载


格式

或者下面这种直接json加载

或者下面这种spark的text加载


以及rdd的加载



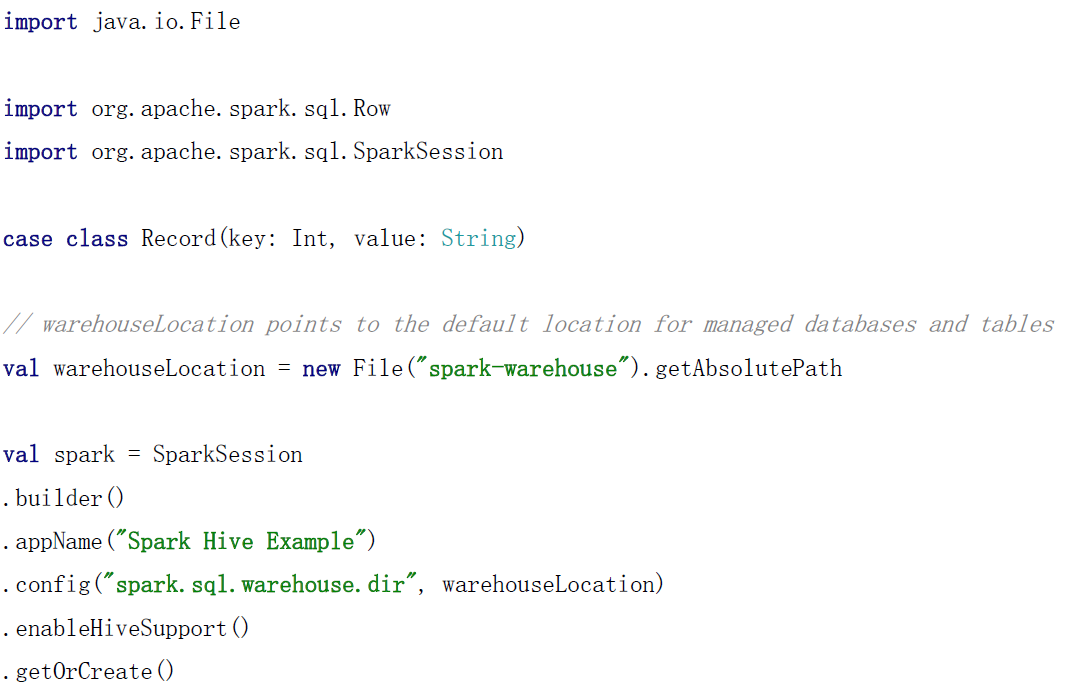
上述记得配置文件加入.mastrt("local")或者spark://master:7077


dataset的生成

下面是dataframe

下面是dataset





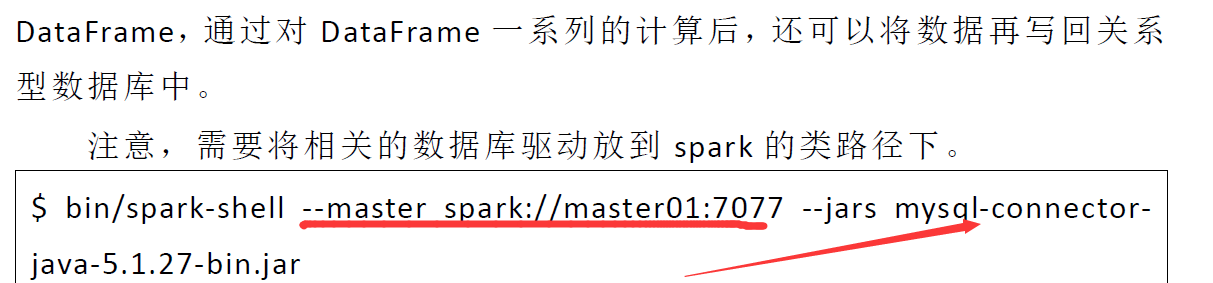
$ bin/spark-shell --master spark://master01:7077 --jars mysql-connector-java-5.1.27-bin.jar
加载连接的两种方式

// Note: JDBC loading and saving can be achieved via either the load/save or jdbc methods
// Loading data from a JDBC source
val jdbcDF = spark.read.format("jdbc").option("url",
"jdbc:mysql://master01:3306/mysql").option("dbtable", "db").option("user",
"root").option("password", "hive").load()
val connectionProperties = new Properties()
connectionProperties.put("user", "root")
connectionProperties.put("password", "hive")
val jdbcDF2 = spark.read .jdbc("jdbc:mysql://master01:3306/mysql", "db", connectionProperties)
保存数据的两种方式
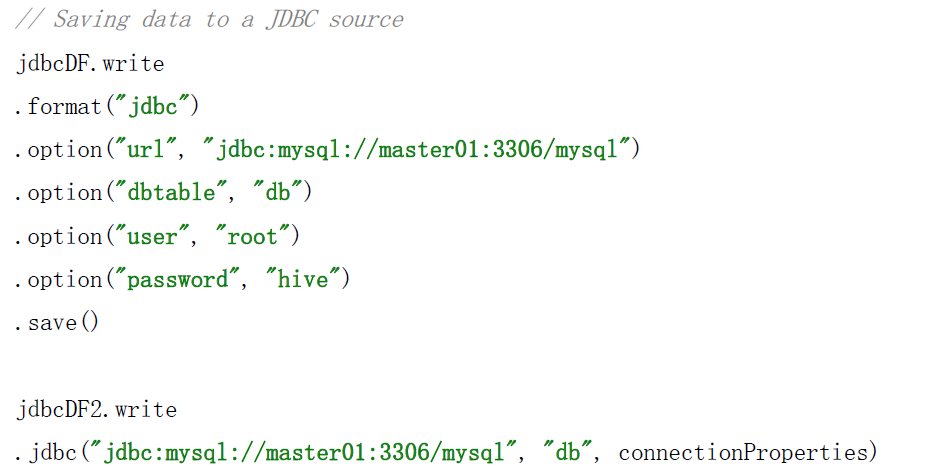
// Saving data to a JDBC source
jdbcDF.write
.format("jdbc")
.option("url", "jdbc:mysql://master01:3306/mysql")
.option("dbtable", "db")
.option("user", "root")
.option("password", "hive")
.save()
jdbcDF2.write .jdbc("jdbc:mysql://master01:3306/mysql", "db", connectionProperties)

// Specifying create table column data types on write
jdbcDF.write
.option("createTableColumnTypes", "name CHAR(64), comments VARCHAR(1024)")
.jdbc("jdbc:mysql://master01:3306/mysql", "db", connectionProperties)