大数据组件使用 总文章
================= Hadoop底层原理 ==================
1.客户端执行hdfs fs put 本地文件系统中的文件路径 hdfs文件系统中的目录路径:hdfs fs put ./a.txt / 发送上传请求给namenode。
2.namenode根据元数据中的文件系统目录树 检测是否存在“该指定的接收上传文件的”目录,检测成功则返回成功信息给客户端。
3.客户端根据上传文件被分为多少份文件块,向namenode请求获取对应多少个datanode,每个datanode负责接收一份文件块。
4.namenode根据元数据中的datanode信息池 检测出可用的N台datanode,每个datanode负责接收一份文件块,namenode把可用的N台datanode的IP地址信息返回给客户端,
每台datanode根据所离客户端的距离远近进行排序插入到一个列表中,离客户端距离最近的datanode排在最前面,比如顺序是 datanode1、datanode2、datanode3。
5.客户端根据离自己最近的datanode逐一建立pipeline管道连接,客户端 和 每个datanode 建立成一条 pipeline管道链接是:客户端 --> datanode1 --> datanode2 --> datanode3。
6.客户端每发送完一个文件块,其所存储该文件块的某个datanode就会返回 ack(命令正确应答)给客户端。
1.客户端给某个datanode发送文件块时,按照在建立好的 pipeline管道链接中查找对应保存该文件块的datanode,
逐级把文件块从一个datanode传输到另外一个databode,最终保存到指定保存该文件块的datanode中。
2.当某个datanode保存完一个文件块后,该datanode返回 ack(命令正确应答),并按照建立好的 pipeline管道链接进行 原路返回ack(命令正确应答)给客户端,
客户端才会继续发送下一个文件块。
7.所有datanode保存完所有的文件块并数据校验完整之后,返回成功信息给客户端
1.客户端执行hadoop fs -get hdfs文件系统中的文件路径 本地文件系统中的目录路径:hadoop fs -get /a.txt /root/
客户端发送请求给namenode,请求获取文件
2.namenode根据客户端所请求下载的文件路径,到hdfs文件系统中找到对应的文件是否存在,存在则返回该文件对应的每个文件块所存储在的每个datanode的IP地址信息,
和 同时包括返回该datanode中保存的对应该文件的所有的每个文件块,每个datanode的IP地址信息按照离客户端的距离远近进行排序插入到一个列表中,
距离客户端近的datanode则把他的IP地址信息插在前面。
3.客户端则根据每个datanode的IP地址信息到对应的datanode中取出对应该文件的所有的每个文件块,最终进行合并校验完整。
1.Reduce阶段 默认只有一个ReduceTask,那么Reduce阶段只输出一个文件
2.job.setNumReduceTasks(N):设置ReduceTask的个数,那么Reduce阶段输出的文件个数也为N,和ReduceTask的个数相同
3.Map阶段的多个MapTask各自输出的<key,value>根据“key.hashcode % ReduceTask个数”的规则,决定把<key,value>输出到哪个ReduceTask中,那么也即存储在哪个输出文件中。
根据“key.hashcode % ReduceTask个数”规则所展现的效果显示: 相同key的 <key,value>都会被分配到同一个ReduceTask中,并且在同一个输出文件中。
4.切片大小默认等于块大小,即对文件以128M为一个block块进行切分,切片个数决定了MR程序启动多少个MapTask。
5.Map阶段(MapTask):map(起始偏移量key, 这一行内容value, Context context){ context.write(new Text(单词),new IntWritable(1)); # <单词,1> }
1.第一步:write到内存缓冲区,直到溢出后存储到磁盘中(带有IO)。
并且根据 “job.setNumReduceTasks(N)所设置ReduceTask个数的”规则 在磁盘中 产生相同的分区数,分区规则同为“key.hashcode % ReduceTask个数”,
把相同key的 <key,value>都分配到同一个磁盘中的分区中,然后按照key的字典序对多个<key,value>进行排序。
并且磁盘中每个分区各自对应一个ReduceTask,比如磁盘中第一个分区对应第一个ReduceTask,如此类推。
2.第二步:磁盘中每个分区各自把<key,value>输出到对应的ReduceTask,比如磁盘中第一个分区输出数据到第一个ReduceTask,如此类推。
6.Reduce阶段(ReduceTask):reduce(单词keyIn, Iterable [1,1,...], Context context){ context.write(单词,总数); # <单词,总数> }
1.第一步:ReduceTask把磁盘分区中送过来的数据按照key的字典序对多个<key,value>进行排序,然后把key相同的作为一组汇总成 <单词,[1,1,...]>,
并调用reduce函数进行统计汇总单词的总次数
2.第二步:ReduceTask把<单词,总数>输出到hdfs中的文件中
------------- Hadoop MapReduce--MapReduce的输入和输出 -----------------

------- Hadoop MapReduce--初识mapreduce数据分区&分区规则--------
//这里设置 reduce阶段中 运行 reduceTask 的个数
//getPartition 返回的分区个数 = NumReduceTasks 正常执行
//getPartition 返回的分区个数 > NumReduceTasks 报错:Illegal partition 非法分割
//getPartition 返回的分区个数 < NumReduceTasks 可以执行 ,多出空白文件
job.setNumReduceTasks(10); 
1.设置 reduce阶段中 运行 reduceTask 的个数为 N,那么便会同样生成 N个同等数量的 结果文件。
一个 reduceTask 负责生成 一个结果文件。每个reduceTask 就相当于 单独一个分区,而每个分区 即代表单独一个 结果文件。
那么也即 reduceTaskNum 的数量 等于 结果文件 的数量 等于 分区的数量。
2.不管设置多少个reduceTask 所生成的 N个结果文件 实际和 设置1个reduceTask所生成的 一个结果文件 的效果相同的,
只是把一个结果文件的数据 分到好几个 结果文件中。
3.每个结果文件 就是 单独一个 区分,那么分区规则是 根据Mapper阶段map函数输出的键值对中的key.hashcode % reduceTaskNum:
% 表示模,那么整体表示的是 使用key的哈希值 对 reduceTaskNum 进行 取模 所得出的余数,该余数的值 对应的就是 第几个reduceTask,
也即把处理后的数据 对应存储到 第几个 结果文件中。

--------- Hadoop MapReduce--处理流程--Mapper任务执行流程解析------------
1.对于目录下的多个要处理的数据文件先进行切片,每个切片的大小是块的大小128M,那么如果一个数据文件的大小刚好是128M的话,
那么该文件即存到该切片中,然后等待被mapreduce 程序中的maptask(mapper阶段的map函数)所处理,
那么有多少个切片便会有多少个maptask(mapper阶段的map函数)
2.maptask中通过TextInputFormat从切片中读取文件数据,返回key和value信息 并发送给mapper阶段中的map函数中进行处理。
key:每一行的起始偏移量,即从文件头开始偏移多少字节到当前这一行,偏移量单位为字节,window下的换行符为2个字节
value:一行内容的字符串数据
3.mapper阶段的map函数通过(mapreduce 程序中的 Context上下文)context.write(k,v) 把处理后的数据进行输出,,
负责把 mapper阶段处理后的数据发送出去给 Reducer阶段的类来进行计算。
此时先会把处理后的数据发送到内存缓冲区中,当内存缓冲区中写满了的话,然后把数据写出到磁盘中。
而磁盘中会根据 reduceTaskNum的数量值 先分出对应数量的 分区,即把内存中的数据 写出到对应的 分区中。
最终分区中的数据等待 reduceTask来读取继续进行处理计算。 

-------- Hadoop MapReduce--处理流程--Reducer任务执行流程解析-------


1.mapreduce 程序中的 每个maptask 都会输出数据到对应分区中,而每个相同编号的分区中的数据 都会交由同一个reducetask 来处理,
比如每个p1分区中的数据 都会交由reducetask1来处理。
2.在reducetask1中 按照key的字典序对 多个p1分区中的数据 进行排序,把相同key的多个键值对作为同一组数据(<key, [1,1,...]>) 传入到同一个我们所重写的 reduce函数中处理.
3.根据reduceTaskNum所设置的值,就有多少个reduceTask,那么就有多少个结果文件。
reduceTask通过 (mapreduce 程序中的 Context上下文)context.write(key, v) 把 Reducer阶段处理后的数据 写出到 HDFS集群中的 输出目录下的 结果文件中。
================= Hadoop配置 =================
1.一旦 Hadoop 集群启动并运行,可以通过 web-ui 进行集群查看,如下所述:
NameNode(HDFS管理界面):192.168.25.100:50070 或 node1:50070
ResourceManager(MR管理界面):http://192.168.25.100:8088 或 node1:8088
2.配置 windows 平台 Hadoop 环境
在 windows 上做 HDFS 客户端应用开发,需要设置 Hadoop 环境,而且要求是
windows 平台编译的 Hadoop,不然会报以下的错误:
Failed to locate the winutils binary in the hadoop binary path java.io.IOException: Could not
locate executable null\bin\winutils.exe in the Hadoop binaries.
解决:为此我们需要进行如下的操作:
A、在 windows 平台下编译 Hadoop 源码(可以参考资料编译,但不推荐)
B、使用已经编译好的 Windows 版本 Hadoop: hadoop-2.7.4-with-windows.tar.gz
C、解压一份到 windows 的任意一个目录下
D、在 windows 系统中配置 HADOOP_HOME 指向你解压的安装包目录
E、在 windows 系统的 path 变量中加入 HADOOP_HOME 的 bin 目录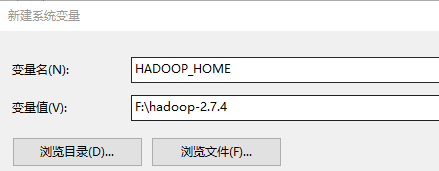


================= Hadoop API =================
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.4</version>
</dependency>



================= HdfsClient:操作Hadoop的API方法 =================




================= hdfs定时上传shell的案列 =================


[root@NODE1 ~]# chmod 777 uploadFile2Hdfs.sh
[root@NODE1 ~]# ./uploadFile2Hdfs.sh


假如有这样的需求:要求在凌晨 24 点开始操作前一天产生的日志文件,准实时上传至 HDFS 集群上
1.HDFS SHELL:hadoop fs –put //满足上传文件,不能满足定时、周期性传入。
2.Linux crontab:
crontab -e
0 0 * * * /shell/ uploadFile2Hdfs.sh //每天凌晨 12:00 执行一次
============= Hadoop API 的基本使用 ============












指定本次MapReduce程序中 数据输入的路径(hdfs文件系统中的路径) 和 数据最终输出 存放在什么位置(hdfs文件系统中的路径)
1.创建数据输入的路径(hdfs文件系统中的路径):hadoop fs -mkdir -p /Hadoop_daima/input
2.把要计算的文件放到数据输入的路径(hdfs文件系统中的路径)中:hadoop fs -put xx.txt yy.txt /Hadoop_daima/input
3.注意:不需要创建 数据最终输出目录(hdfs文件系统中的路径),否则会报错:FileAlreadyExistsException: Output directory,
数据最终输出目录会由MapReduce程序创建


Hadoop MapReduce--程序运行模型--集群运行模式
将 mapreduce 程序提交给 yarn 集群的命令:
格式一:hadoop jar xx.jar mapreduce程序的全限定类名 args参数
例子:hadoop jar wordcount.jar cn.itcast.bigdata.mrsimple.WordCountDriver args
格式二:hadoop jar xx.jar
(无需配置mapreduce程序的全限定类名,因为在pom.xml中的<mainClass>标签体中配置了mapreduce程序的全限定类名)
例子:hadoop jar wordcount.jar







----- Hadoop MapReduce 程序运行模型 本地运行模式-----
conf.set("mapreduce.framework.name","local")代码语句 为设置本地模式运行,但要注意的是 mapred-default.xml中已经默认配置是本地模式,
所以即使不配置conf.set(“mapreduce.framework.name”,“local”),只要右键run运行该程序仍然是本地模式


指定本次MapReduce程序中 数据输入的路径(本地文件系统中的路径) 和 数据最终输出 存放在什么位置(本地文件系统中的路径)
注意:不需要创建 数据最终输出目录(本地文件系统中的路径),否则会报错:FileAlreadyExistsException: Output directory,
数据最终输出目录会由MapReduce程序创建。


======== Hadoop MapReduce编程案例--流量汇总--序列化机制Writable ============
---------mapper编写--------------
把一行信息看作为一个数组中,此处取出某一列的数据(某个字段的数据/数组中某个元素值),使用数组[length-N]的方式获取,
因为从左到右数出现某列(某个字段)缺失数据,而从右到左数则不会出现某列(某个字段)缺失数据


------------Reducer编写---------------

---------运行主类编写------------

-------本地模式 运行 Mapreduce程序中的 FlowSumDriver类:右键直接run-------



======= Hadoop MapReduce编程案例--流量汇总排序--需求分析&comopareTo方法重写============
在上面的基础之上再加一个需求:
将统计结果按照总流量倒序排序(从大到小排序),因为此处MapReduce程序中的Reduce阶段中的 Context上下文对象把一个类对象作为valueout进行输出到文件中,
所以重写 该类中的comopareTo方法,comopareTo方法中进行总流量倒序排序(从大到小排序),那么结果文件中的输出数据便是按照总流量倒序排序(从大到小排序)。

实现步骤:
1.Mapper阶段(map函数)中是默认根据 keyin 进行 字典序进行排序的,所以当keyin 是bean对象时,
只需要bean对象所在的类中implements实现 WritableComparable<类名> 接口,并在类中重写comopareTo方法,
那么便会根据comopareTo方法定义的排序规则进行keyin 的排序,便不会再使用默认的字典序排序规则进行排序。
例子:public class FlowBean implements WritableComparable<FlowBean>
原理:interface WritableComparable<T> extends Writable, Comparable<T>
2.Mapper阶段(map函数)中的 (keyin)bean对象所在的类中重写comopareTo方法:
那么每个keyin(bean对象)之间不再使用默认的字典序排序规则进行排序,每个keyin(bean对象)之间使用 comopareTo方法中定义的排序规则进行排序。
代码如下:
@Override
public int compareTo(FlowBean o)
{
//实现按照总流量的倒序排序
return this.sumFlow >o.getSumFlow()?-1:1; //顺序排序(从小到大)
//return this.sumFlow >o.getSumFlow()?1:-1 //倒序排序(从大到小)
}





=========Hadoop MapReduce编程案例--流量汇总分区--需求分析&HashPartitioner讲解============
需求:将流量汇总统计结果按照手机归属地不同省份输出到不同文件中
Mapper阶段(map函数)中:
读一行,切分字段
抽取手机号,上行流量 下行流量
context.write(手机号,bean)
map输出的数据要分成6个区
重写partitioner,让相同归属地的号码返回相同的分区号int
实现原理:
1.job.setNumReduceTasks(N):
设置了 NumReduceTasks 之后,便会生成 N 个输出结果文件,
那么 Reduce阶段(reduce函数)按照默认的分区规则 (key.hashcode & Integer.MAX_VALUE) % numReduceTasks 来进行分发到哪个输出结果文件中。
(key.hashcode & Integer.MAX_VALUE) % numReduceTasks:
获取Reduce阶段(reduce函数)输出的key的hashcode值,再 & 上 Integer的最大值 所得出的数值 再模(%)上 所设置的numReduceTasks数量值,
所得出的 余数 对应的就是 第几个 输出结果文件。

2.当没有执行 job.setNumReduceTasks(N),即没有显式设置 numReduceTasks 时,那么numReduceTasks 默认为 1,任何数 % 1 的值 都为 0,
因此(key.hashcode & Integer.MAX_VALUE) % numReduceTasks 的结果值 便为 0,所以Reduce阶段(reduce函数)输出的数据 都存到同一个文件中。





======== Hadoop MapReduce--combiner组件介绍&使用注意事项============
ReduceTask(Reduce阶段)负责全局合并,合并所有的MapTask传过来的数据。
而每个combiner进行的是局部合并,一个combiner只针对单独某个对应的MapTask(Mapper阶段)的数据进行合并。
combiner再把局部合并后的数据发送给ReduceTask(Reduce阶段)继续进行全局合并。
比如此处例子中的9个<hello,1>的数据:
1.如果不使用combiner把9个<hello,1>合并为1个<hello,9>再传给ReduceTask(Reduce阶段)的话,那么MapTask就需要传输9次<hello,1>给ReduceTask(Reduce阶段)
2.如果使用combiner把9个<hello,1>合并为1个<hello,9>再传给ReduceTask(Reduce阶段)的话,那么MapTask就只需要传输1次<hello,9>给ReduceTask(Reduce阶段)

实现步骤:
1.自定义一个 Combiner类 继承 Reducer,重写 reduce 方法
2.在 job 中设置:job.setCombinerClass(CustomCombiner.class)
实现捷径:
因为 自定义的Combiner类 的写法 类似于 全局的Reducer阶段(reducer函数),两者都是同样的需要继承 extends Reducer<keyin,valuein,keyout,valueout>,
并且两者都需要重写reduce(keyin key, Iterable<valuein的类型> values, Context context),
因此可以直接把 全局的Reducer阶段(reducer函数)的类 作为 自定义的Combiner类 来使用,因为全局的合并 和 局部的合并 两者的 合并操作的逻辑 都是一样,
所以便可以直接把 全局的Reducer阶段(reducer函数)的类 作为 自定义的Combiner类 来使用,使用 全局的Reducer阶段(reducer函数)的类来对 每个的MapTask都进行数据局部合并。
那么只需要在Driver类 设置job.setCombinerClass(XxxReducer.class) 即可。
实现例子如下:



直接把 全局的Reducer阶段(reducer函数)的类 作为 自定义的Combiner类 来使用,使用 全局的Reducer阶段(reducer函数)的类来对 每个的MapTask都进行数据局部合并
![]()
