本萌最近被一则新闻深受鼓舞,西工大硬核“女学神”白雨桐,获6所世界顶级大学博士录取

货真价值的才貌双全,别人家的孩子
高考失利与心仪的专业失之交臂,选择了软件工程这门自己完全不懂的专业.即便全部归零,也要证明自己,连续3年专业综合排名第一,各种获奖经历写满了5页PPT。成功始于不断的努力和拼搏,在学习和实践中不断提升自己。
#技本功#愿做你成功路上的基石,赶紧来接收今日份的精神投食~

一、解读type
执行计划的type表示访问数据类型,有很多种访问类型。
1、system
表示这一步只返回一行数据,如果这一步的执行对象是一个驱动表或者主表,那么被驱动表或者子查询只是被访问一次。
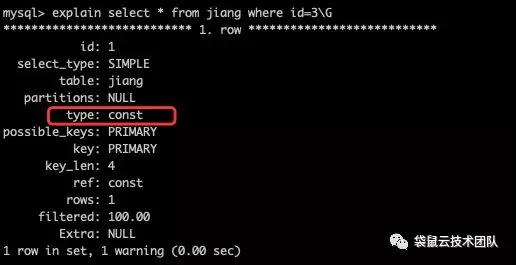
2、const
表示这个执行步骤最多只返回一行数据。const通常出现在对主键或唯一索引的等值查询中,例如对表t主键id的查询:
3、eq_ref
eq_ref类型一般意味着在表关联时,被关联表上的关联列走的是主键或者唯一索引。例如,表jiang关联lock_test表,关联列分别是两张表的主键列 :

上面SQL执行时,jiang表是驱动表,lock_test是被驱动表,被驱动表的关联列是主键id,type类型为eq_ref。
所以,对于eq_ref类型来说有一个重要的特点就是:这一步涉及到的表是被驱动表;这一步中使用到唯一索引或主键。除了system和const之外,这是效果最好的关联类型。
4、ref
与上面相反,如果执行计划的某一步的type是ref的话,表示这一步的关联列是非唯一索引。例如,用表jiang的主键id列关联表lock_test的num列,num列上建立了普通索引:

上面SQL执行时,表jiang是驱动表,lock_test是被驱动表,被驱动表上走的是非唯一索引,type类型为ref。
所以ref的特点是:表示这一步访问数据使用的索引是非唯一索引。
5、Ref_or_null
例如执行下面语句:

表示走了索引(num列上有索引),但是也访问了空值。
6、index_merge
表示索引合并,一般对多个二级索引列做or操作时就会发生索引合并。
例如执行下列语句:
mysql> explain select * from lock_test where id=3 or num=4;

id为主键,num列上建有普通索引,语句执行时,会通过两个单列索引来处理or操作。
7、unique_subquery
表示唯一子查询。例如有如下语句执行时:
value in(select primary_key from single_table where ...)
对于in子句来说,当in子句里的子查询返回的是某一个表的主键时,type显示为unique subquery。
8、index_subquery
当有如下语句执行时:
value in(select key_column from single_table where ...)
与上面的相似,表示对于in子句来说,当in子句里的子查询返回的是某一个表的二级索引列(非主键列)时,type显示为index_subquery。
9、range:
在有索引的列上取一部分数据。常见于在索引列上执行between and操作。
10、index:
索引全扫描,一般发生在覆盖索引的时候,也就是对有索引列发生一次全扫描。
11、all:
没有索引的全表扫描。
一个特例:
Explain select * from stu limit 1,1;
二、解读extra
1、using where:
一般有两层意思:
表示通过索引访问时,需要再回表访问所需的数据;
过滤条件发生在server层而不是存储引擎层;
如果执行计划中显示走了索引,但是rows值很高,extra显示为using where,那么执行效果就不会很好。因为索引访问的成本主要在回表上,这时可以采用覆盖索引来优化。
通过覆盖索引也能将过滤条件下压,在存储引擎层执行过滤操作,这样效果是最好的。
所以,覆盖索引是解决using where的最有效的手段。
2、using index condition
表示将过滤下压到存储层执行,防止server层过滤过多数据
如果extra中出现了using index condition,说明对访问表数据进行了优化。
3、using temporary
表示语句执行过程中使用到了临时表。以下子句的出现可能会使用到临时表:
order by
group by
distinct
union等
数据不能直接返回给用户,就需要缓存,数据就以临时表缓存在用户工作空间。注意,可能会出现磁盘临时表,需要关注需要缓存的数据的rows。
可以使用索引消除上面的四个操作对应的临时表。
4、using sort_union(indexs)
比如当执行下面语句:

Sname和sphone列上都有索引,这时执行计划的extra项就会显示using sort_union(i_sname,i_spone),表示索引合并。常伴随着index_merge。
5、using MRR:
一般通过二级索引访问表数据的过程是:先访问二级索引列,找到对应的二级索引数据后就得到对应的主键值,然后拿着这个主键值再去访问表,取出行数据。这样取出的数据是按照二级索引排序的。
MRR表示:通过二级索引得到对应的主键值后,不直接访问表而是先存储起来,在得到所有的主键值后,对主键值进行排序,然后再访问表。这样可以大幅减低对表的访问次数,至少实现了顺序访问表。
MRR的一个优点就是提升索引访问表的效率,也就是降低了回表的成本。但是有一个比较大的问题:取出来的数据就不按照二级索引排序了。
6、using join buffer(Block Nested Loop)
BNL主要发生在两个表关联时,被关联的表上没有索引。
BNL表示这样的意思:A关联B,A的关联列上有索引而B的没有。这时就会从A表中取10行数据拿出来放到用户的join buffer空间中,然后再取B上的数据和join buffer中A的关联列进行关联,这时只需要对B表访问一次,也就是B表发生一次全表扫描。
如果join buffer中的10行数据关联完后,就再取10行数据继续和B表关联,一直到A表的所有数据都关联完为止。
从上面可以看出来,这种方式大概效率会提高约90%。
7、using join buffer(Batched Key Access)
一般出现BKA的情况是:表关联时,被驱动表上有索引,但是驱动表返回的行数太多。
当出现上述情况时,就会将驱动表的返回结果集放到用户工作空间的join buffer中,然后取结果集的一条记录去关联被驱动表的索引关联列。得到相应的主键列后并不马上通过这个主键列去被被驱动表中取数据,而是先存放到工作空间中。等到结果集中的所有数据都关联完了,对工作空间中的所有通过关联得到主键列进行排序,然后统一访问被驱动表,从中取数据。这样的好处就是大大降低了访问的次数。
从上面可以看出:BKA用到了MRR技术;BKA适合驱动表返回行数较多、被驱动表访问时走的是索引的情况。
这个功能可以打开或者关闭:
Set optimizer_switch=’mrr=on,batched_key_access=on’;
8、using index for group by
表示通过复合索引完成group by,不用回表。
例如复合索引(a,b),执行语句:select a from tb group by b;时就会出现using index for group by。
9、using index
表示实现了覆盖索引扫描;也就是需要访问的数据都在索引中,不需要回表。在一般情况下,减少不必要的数据访问能够提升效率。
例如对表lock_test取num列上的数据,num列上建立普通索引:

10、using filesort
说明有排序行为,但是不一定是磁盘排序。
11、materialize scan
对物化表的全扫描,因为物化表就是一个临时表,表上没有索引。