1.vector
通过源码分析,发现在Vector类中有一个Object[]类型数组.
1):表面上把数据存储到Vector对象中,其实底层依然是把数据存储到Object数组中的.
2):我们发现该数组的元素类型是Object类型,意味着集合中只能存储任意类型的对象.
集合中只能存储对象,不能存储基本数据类型的值.
在Java5之前,必须对基本数据类型手动装箱.
如:v.addElement(Integer.valueOf(123));
从Java5开始支持自动装箱操作,代码.
如:v.addElement(123);其实底层依然是手动装箱
//Vector类
底层有两个构造器 , 一个是默认构造器.默认初始容量是10 ;
一个是由我们制定数组容量的构造器
public class VectorDemo {
public static void main(String[] args) {
Vector v1 = new Vector();// 默认初始容量为10
v1.add("A");
v1.add("B");
v1.add("C");
v1.add("D");
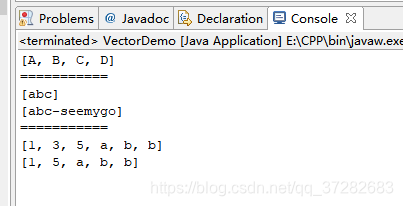
System.out.println(v1);
System.out.println("===========");
Vector v2 = new Vector(5);// 指定初始容量为5 ,会自动扩容
StringBuilder sb = new StringBuilder();// 默认初始容量为16
/*
* 集合类中,存储的对象,都是存储对象的引用地址.而不是对象本身
* */
sb.append("abc");
v2.add(sb); // 存储的是sb的引用地址 ;
System.out.println(v2);
sb.append("-seemygo");
System.out.println(v2);
System.out.println("===========");
Vector v3 = new Vector();// 默认初始容量为10
v3.add(1);
v3.add(3);
v3.add(5);
v3.add("a");
v3.add("b");
v3.add("b");
System.out.println(v3);
v3.remove(Integer.valueOf(3) );
//v3.remove("3");
System.out.println(v3);
}
2.LinkList
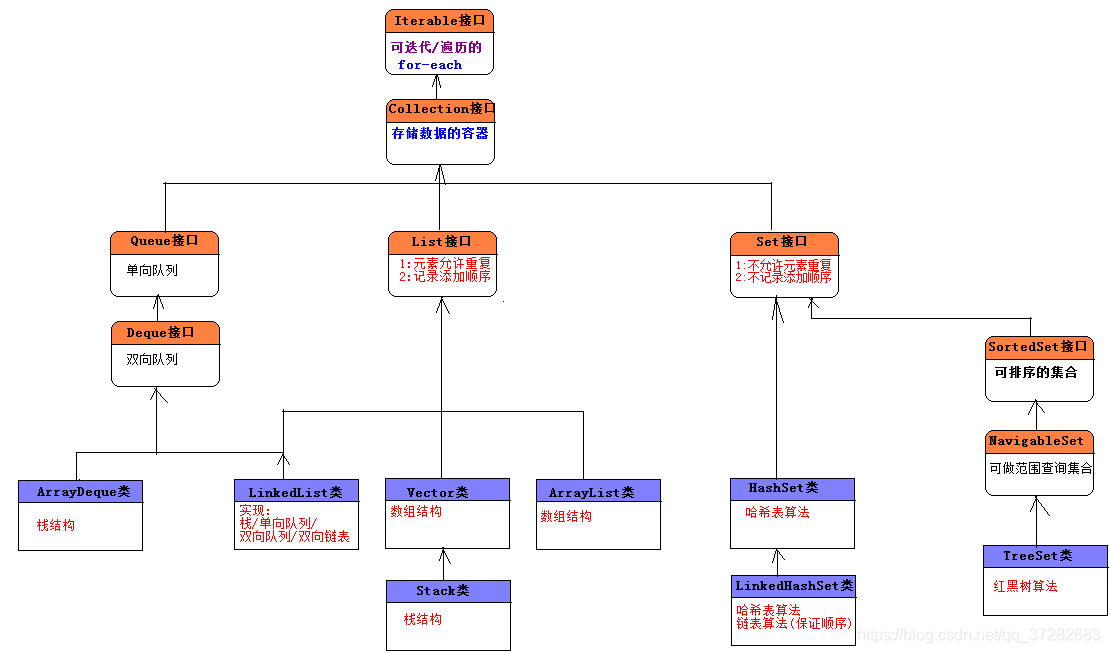
LinkedList类实现单向队列和双向队列的接口,自身提高了栈操作的方法,链表操作的方法.
在LinkedList类中存在很多方法,但是功能都是相同的.LinkedList表示了多种数据结构的实现,每一种数据结构的操作名字不同.
import java.util.Arrays;
import java.util.LinkedList;
import java.util.List;
//LinkedList类 实现单向队列和 双向队列的接口
public class LinkedListDemo {
public static void main(String[] args) {
LinkedList list1 = new LinkedList();
list1.addLast("b");
list1.addLast("c");
list1.addLast("5");
list1.addLast("d");
list1.addLast("6");
list1.addLast("8");
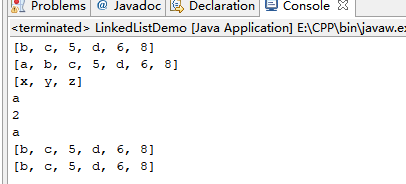
System.out.println(list1);
list1.addFirst("a");
System.out.println(list1);
LinkedList list2 = new LinkedList();
list2.addFirst("x");
list2.addLast("y");
list2.addLast("z");
System.out.println(list2);
//list1.addAll(list2);//将2的元素全部添加到1的结尾
//System.out.println(list1);
//list1.addAll(2,list2);//将2的元素从指定的位置开始添加
//System.out.println(list1);
System.out.println(list1.element());//获取第一个元素
System.out.println(list1.indexOf("c"));//元素首次出现的索引
System.out.println(list1.pop());//从列表的堆栈弹出一个元素
System.out.println(list1);
Object[] arr = list1.toArray();//返回列表中所有元素的数组
System.out.println(Arrays.toString(arr));
}
}
3.Link类总结
List实现类特点和性能分析:
三者共同的特点(共同遵循的规范):
1):允许元素重复.
2):记录元素的先后添加顺序.
Vector类: 底层才有数组结构算法,方法都使用了synchronized修饰,线程安全,但是性能相对于ArrayList较低.
ArrayList类: 底层才有数组结构算法,方法没有使用synchronized修饰,线程不安全,性能相对于Vector较高.
ArrayList现在机会已经取代了Vector的江湖地位.
为了保证ArrayList的线程安全,List list = Collections.synchronizedList(new ArrayList(…));
LinkedList类:底层才有双向链表结构算法,方法没有使用synchronized修饰,线程不安全.
数组结构算法和双向链表结构算法的性能问题:
数组结构算法: 插入和删除操作速度低,查询和更改较快.
链表结构算法: 插入和删除操作速度快,查询和更改较慢.
使用的选择:
Vector类打死不用!即使要用选ArrayList类.
如果删除和插入操作频繁,应该选择LinkedList类.
如果查询操作频繁,应该使用ArrayList类.
在开发中使用ArrayList较多,根据具体的需求环境来做选择.
4.迭代器
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
//Iterator迭代器对象,只能从上往下迭代
public class IteratorDemo {
public static void main(String[] args) {
List list = new ArrayList();
list.add("a");
list.add("b");
list.add("c");
list.add("d");
list.add("e");
list.add("f");
list.add("g");
System.out.println(list);
System.out.println("===========");
// 方式1 ; for循环 输出
for (int i = 0; i < list.size(); i++) {
System.out.print(list.get(i));
}
System.out.println();
System.out.println("===========");
// 方式2 for-each 增强for循环
for (Object ele : list) {
System.out.print(ele);
}
System.out.println();
System.out.println("===========");
// Xxx.iterator() 返回按适当顺序在列表的元素上进行迭代的迭代器。
// Object next():获取指针的下一个元素,并且移动指针.
// 方式3 使用while 循环操作迭代器Iterator
Iterator it = list.iterator();// 返回按适当顺序在列表的元素上进行迭代的迭代器
while (it.hasNext()) {
System.out.print(it.next());
}
System.out.println();
System.out.println("===========");
// 方式4 使用for循环来操作迭代器
/**
* foreach 操作Iterable的实例底层就是采用该方式
*/
for(Iterator it2 = list.iterator();it2.hasNext();){
System.out.print(it2.next());
}
System.out.println();
System.out.println("===========");
}
}
集合的迭代操作:
把集合做的元素一个一个的遍历取出来.
迭代器对象:
Iterator: 迭代器对象,只能从上往下迭代.
boolean hasNext(); 判断当前指针后是否有下一个元素
Object next():获取指针的下一个元素,并且移动指针.
ListIterator: 是Iterator接口的子接口,支持双向迭代,从上往下迭代,从下往上迭代.
Enumeration:古老的迭代器对象,现在已经被Iterator取代了. 适用于古老的Vector类.


5.泛型
泛型类:直接在类/接口上定义的泛型.
使用泛型:
保证前后类型相同.
List list = new ArrayList();//该List集合中只能存储String类型的元素.
因为前后类型相同,所以从Java7开始,退出泛型的菱形语法<>.
List list = new ArrayList<>();
泛型不存在继承的关系(错误如下).
List list = new ArrayList();//错误的
从此以后,使用集合都得使用泛型来约束该集合中元素的类型.
通过反编译,发现:泛型其实也是语法糖,底层依然没有泛型,而且依然使用强转.
//泛型类中的泛型,只适用于非静态方法
public class Point<T> { // T 表示可以为任意类型,具体类型由调用者决定
private T x;
private T Y;
public T getX() {
return x;
}
public void setX(T x) {
this.x = x;
}
public T getY() {
return Y;
}
public void setY(T y) {
Y = y;
}
}
6.泛型的擦除和转换
泛型的擦除:
1):泛型编译之后就消失了(泛型自动擦除);
2):当把带有泛型的集合赋给不带泛型的集合,此时泛型被擦除(手动擦除).
堆污染:
单一个方法既使用泛型的时候也使用可变参数,此时容易导致堆污染问题.
如:在Arrays类中的asList方法: public static List asList(T… a).
import java.util.ArrayList;
import java.util.List;
//泛型的擦除和转换
/**
* 泛型的擦除:
1):泛型编译之后就消失了(泛型自动擦除);
2):当把带有泛型的集合赋给不带泛型的集合,此时泛型被擦除(手动擦除).
*
*
*/
public class genericTypeDemo2 {
public static void main(String[] args) {
//带有Integer类型的泛型
List<Integer> list1 = new ArrayList<>();
list1.add(123);
//不带泛型的集合
List list2 = null;
list2 =list1 ; //此时泛型被擦除
list2.add("abc");
//带 Srting类型的泛型
List<String> list3 = new ArrayList<>();
list3 = list2;
System.out.println(list3); //此时可以运行,但是程序存在错误
String num = list3.get(0); //编译不会报错,但是运行出错 java.lang.Integer cannot be cast to java.lang.String
}
}
7.Set
Set集合存储特点:
1):不允许元素重复.
2):不会记录元素的先后添加顺序.
8.HashSet
HashSet是Set接口最常用的实现类,顾名思义,底层才用了哈希表(散列/hash)算法.
其底层其实也是一个数组,存在的意义是提供查询速度,插入速度也比较快,但是适用于少量数据的插入操作.
在HashSet中如何判断两个对象是否相同问题:
1):两个对象的equals比较相等. 返回true,则说明是相同对象.
2):两个对象的hashCode方法返回值相等.
对象的hashCode值决定了在哈希表中的存储位置.
二者:缺一不可.
当往HashSet集合中添加新的对象的时候,先回判断该对象和集合对象中的hashCode值:
1):不等: 直接把该新的对象存储到hashCode指定的位置.
2):相等: 再继续判断新对象和集合对象中的equals做比较.
1>:hashCode相同,equals为true: 则视为是同一个对象,则不保存在哈希表中.
1>:hashCode相同,equals为false:非常麻烦,存储在之前对象同槽为的链表上(拒绝,操作比较麻烦).
对象的hashCode和equals方法的重要性:
每一个存储到hash表中的对象,都得提供hashCode和equals方法,用来判断是否是同一个对象.
存储在哈希表中的对象,都应该覆盖equals方法和hashCode方法,并且保证equals相等的时候,hashCode也应该相等.
List接口: 允许元素重复,记录先后添加顺序.
Set接口: 不允许元素重复,不记录先后添加顺序.
需求: 不允许元素重复,但是需要保证先后添加的顺序.
LinkedHashSet:底层才有哈希表和链表算法.
哈希表:来保证唯一性,.此时就是HashSet,在哈希表中元素没有先后顺序.
链表: 来记录元素的先后添加顺序.
9.TreeSet
TreeSet集合底层才有红黑树算法,会对存储的元素默认使用自然排序(从小到大).
注意: 必须保证TreeSet集合中的元素对象是相同的数据类型,否则报错.
import java.util.NavigableSet;
import java.util.Set;
import java.util.TreeSet;
//treeset 底层采用红黑树算法,默认对集合对象 按照自然顺序排序,所以要求集合对象的类型要一致2
public class TreeSetDemo {
public static void main(String[] args) {
TreeSet<String> s = new TreeSet<>();
s.add("c");
s.add("f");
s.add("g");
s.add("6");
s.add("9");
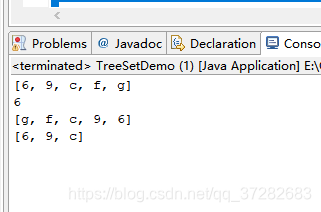
System.out.println(s);
s.descendingSet();
System.out.println(s.first());
System.out.println(s.descendingSet());//返回set包含元素的逆序视图
System.out.println(s.headSet("f"));// 返回元素严格小于 参数的一个数组
}
}
10.TreeSet的定制排序
覆盖 public int compareTo(Object o)方法,在该方法中编写比较规则.
在该方法中,比较当前对象(this)和参数对象o做比较(严格上说比较的是对象中的数据,比如按照对象的年龄排序).
this > o: 返回正整数. 1
this < o: 返回负整数. -1
this == o: 返回0. 此时认为两个对象为同一个对象.
在TreeSet的自然排序中,认为如果两个对象做比较的compareTo方法返回的是0,则认为是同一个对象.
定制排序(从大到小,按照名字的长短来排序):
在TreeSet构造器中传递java.lang.Comparator对象.并覆盖public int compare(Object o1, Object o2)再编写比较规则.
对于TreeSet集合来说,要么使用自然排序,要么使用定制排序.
判断两个对象是否相等的规则:
自然排序: compareTo方法返回0;
定制排序: compare方法返回0;
import java.util.Comparator;
import java.util.TreeSet;
//在treeset里面如何判断两个元素是否相同
//需求:设置四个人的名字.年龄. 按照设置的命名字长短或者年龄排序
class Person implements Comparable<Person> {
String name;
int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "Person [name=" + name + ", age=" + age + "]";
}
// 自定义的编写比较规则 (按照年龄来排序) 自然排序
public int compareTo(Person p) { // 因为是TreeSet ,所以所有的比较元素必须类型相同
if (this.age > p.age) {
return 1;
} else if (this.age < p.age) {
return -1;
} else {
return 0;
}
}
}
public class TreeSetcompareble {
public static void main(String[] args) {
TreeSet<Person> s = new TreeSet<>();
s.add(new Person("猪", 5));
s.add(new Person("张大猪", 25));
s.add(new Person("大猪", 15));
s.add(new Person("二猪", 38));
s.add(new Person("张智大猪", 35));
System.out.println(s);
System.out.println("=================");
TreeSet<Person> s2 = new TreeSet<>(new NameComparator());
s2.add(new Person("猪", 5));
s2.add(new Person("张大猪", 25));
s2.add(new Person("大猪", 15));
s2.add(new Person("二猪", 38));
s2.add(new Person("张智大猪", 35));
System.out.println(s2);
}
}
class NameComparator implements Comparator<Person> { // 注意泛型的使用
// 自定义编写 定制排序的规则.名字长度比较器
@Override
public int compare(Person o1, Person o2) {
if (o1.name.length() > o2.name.length()) {
return 1;
} else if (o1.name.length() < o2.name.length()) {
return -1;
} else {
if (o1.age > o2.age) { //当名字长度相等的时候 比较年龄的大小来排序
return 1;
} else if (o2.age <o2.age) {
return -1;
} else {
return 0;
}
}
}
}

11.Set接口总结
Set接口的实现类:
共同的特点:
1):都不允许元素重复.
2):都不是线程安全的类.
解决方案:Set s = Collections.synchronizedSet(Set对象);
HashSet: 不保证元素的先后添加顺序.
底层才有的是哈希表算法,查询效率极高.
判断两个对象是否相等的规则:
1):equals比较为true.
2):hashCode值相同.
要求:要求存在在哈希中的对象元素都得覆盖equals和hashCode方法.
LinkedHashSet:
HashSet的子类,底层也采用的是哈希表算法,但是也使用了链表算法来维持元素的先后添加顺序.
判断两个对象是否相等的规则和HashSet相同.
因为需要多使用一个链表俩记录元素的顺序,所以性能相对于HashSet较低.
一般少用, 如果要求一个集合既要保证元素不重复,也需要记录添加先后顺序,才选择使用LinkedHashSet.
TreeSet:不保证元素的先后添加顺序,但是会对集合中的元素做排序操作.
底层才有红黑树算法(树结构,比较擅长做范围查询).
TreeSet要么才有自然排序,要么定制排序.
自然排序: 要求在TreeSet集合中的对象必须实现java.lang.Comparable接口,并覆盖compareTo方法.
定制排序: 要求在构建TreeSet对象的时候,传入一个比较器对象(必须实现java.lang.Comparator接口).
在比较器中覆盖compare方法,并编写比较规则.
TreeSet判断元素对象重复的规则:
compareTo/compare方法是否返回0.如果返回0,则视为是同一个对象.
HashSet做等值查询效率高,TreeSet做范围查询效率高.
而我们更多的情况,都是做等值查询, 在数据库的索引中做范围查询较多,所以数结构主要用于做索引,用来提高查询效率.
12.Map
映射的数学解释:
设A、B是两个非空集合,如果存在一个法则f,使得对A中的每个元素a,按法则f,在B中有唯一确定的元素b与之对应,则称f为从A到B的映射,记作f:A→B。
映射关系(两个集合):A集合和B集合.
A集合中的每一个元素都可以在B集合中找到唯一的一个值与之对应.
严格上说,Map并不是集合,而是两个集合之间的映射关系(Map接口并没有继承于Collection接口),然而因为Map可以存储数据(每次存储都应该存储A集合中以一个元素(key),B集合中一个元素(value)),我们还是习惯把Map也称之为集合.
因为:Map接口并没有继承于Collection接口也没有继承于Iterable接口,所以不能直接对Map使用for-each操作.

Map的常用实现类:
HashMap: 采用哈希表算法, 此时Map中的key不会保证添加的先后顺序,key也不允许重复.
key判断重复的标准是: key1和key2是否equals为true,并且hashCode相等.
TreeMap: 采用红黑树算法,此时Map中的key会按照自然顺序或定制排序进行排序,key也不允许重复.
key判断重复的标准是: compareTo/compare的返回值是否为0.
LinkedHashMap: 采用链表和哈希表算法,此时Map中的key会保证先后添加的顺序,key不允许重复.
key判断重复的标准和HashMap中的key的标准相同.
Hashtable: 采用哈希表算法,是HashMap的前身(类似于Vector是ArrayList的前身).打死不用.
在Java的集合框架之前,表示映射关系就使用Hashtable.
所有的方法都使用synchronized修饰符,线程安全的,但是性能相对HashMap较低.
Properties: Hashtable的子类,此时要求key和value都是String类型.
用来加载资源文件(properties文件(IO再讲)).
一般的,我们定义Map,key都使用不可变的类(String),把key作为value的唯一名称.
HashMap和TreeMap以及LinkedHashMap都是线程不安全的,但是性能较高:
解决方案: Map m = Collections.synchronizedMap(Map对象);
Hashtable类实现线程安全的,但是性能较低.
哈希表算法:做等值查询最快.
数结构算法:做范围查询最快–>应用到索引上.
import java.util.HashMap;
import java.util.LinkedHashMap;
import java.util.Map;
//需求 计算一个字符串中每一个字母出现的次数 (用键值对做)
public class MapDemo {
public static void main(String[] args) {
String str = "iuhiubiuviuvivhvjhvjhggvvoitcicvbb";
char[] arr = str.toCharArray(); //将字符串转为数组
//Character-->key ,Integer --> value
// 存字符 出现次数
Map<Character, Integer> map = new LinkedHashMap<>();
for (char ch : arr) {
if(map.containsKey(ch)){ //判断map中是否包含了该字符的key
Integer num = map.get(ch); //如果存在的话,取出该字符对应的value值 ++ ,在放回去
map.put(ch, num+1); //将value值放回去
}else{
map.put(ch, 1); //表示当前map不包含该字符的key, 将ch字符保存为 key ,value值设置为1
}
}
System.out.println(map);
}
}
