一. Zookeeper是什么
Zookeeper 分布式服务框架是 Apache Hadoop 的一个子项目, 它主要是用来解决分布式应用中常常遇到的一些数据管理问题,如:统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等。这个是官方的说法,其实就可以简单的认为ZooKeeper 是为分布式应用程序提供高性能协调服务的工具集合。
二. Zookeeper的数据结构
Zookeeper维护一个类似文件系统的数据结构:
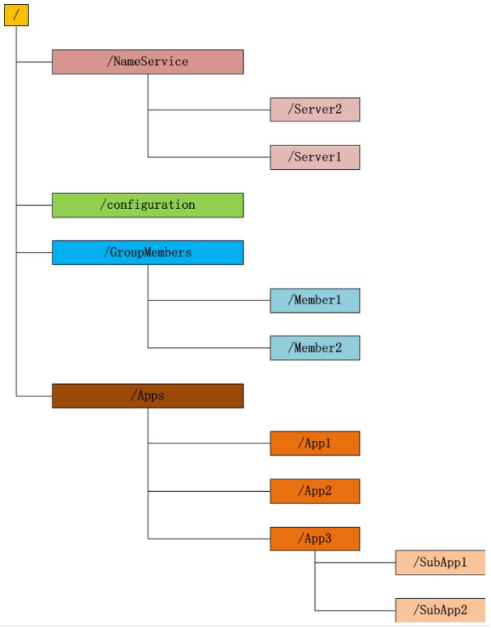
这种和文件系统很像的层级命名空间来让分布式进程互相协同工作,这些命名空间由一系列数据寄存器组成,我们也叫这些数据寄存器为znodes。这些znodes就有点像是文件系统中的文件和文件夹。和文件系统不一样的是,文件系统的文件是存储在存储区上的,而zookeeper的数据是存储在内存上的,我们能够自由的增加、删除znode,在一个znode下增加、删除子znode,同时,这就意味着zookeeper有着高吞吐和低延迟。
二. Zookeeper的工作模式
在ZooKeeper集群当中,集群中的服务器角色有两种Leader和Learner,Learner角色又分为Observer和Follower

Zookeeper的核心是原子广播,这个机制保证了各个Server之间的同步。实现这个机制的协议叫做Zab协议。Zab协议有两种模式,它们分别是恢复模式(选主)和广播模式(同步)。
当服务启动或者在领导者崩溃后,Zab就进入了恢复模式,当领导者被选举出来,且大多数Follower完成了和leader的状态同步以后,恢复模式就结束了。状态同步保证了leader和Follower具有相同的系统状态。
该ZooKeeper集群当中一共有5台服务器,有两种角色Leader和Follwer,5台服务器连通在一起,客户端有分别连在不同的ZK服务器上。

如果当数据通过客户端1,在左边第一台Follower服务器上做了一次数据变更,他会把这个数据的变化同步到其他所有的服务器,同步结束之后,那么其他的客户端都会获得这个数据的变化。
注:Zookeeper是一个由多个server组成的集群,一个leader,多个follower,每个server保存一份数据副本,全局数据一致、分布式读写,更新请求转发,由leader实施。
Leader主要有三个功能
1 .恢复数据;
2 .维持与Learner的心跳,接收Learner请求并判断Learner的请求消息类型;
3 .Learner的消息类型主要有PING消息、REQUEST消息、ACK消息、REVALIDATE消息,根据不同的消息类型,进行不同的处理。
Follower主要有四个功能
1. 向Leader发送请求(PING消息、REQUEST消息、ACK消息、REVALIDATE消息);
2 .接收Leader消息并进行处理;
3 .接收Client的请求,如果为写请求,发送给Leader进行投票;
4 .返回Client结果。
三. ZooKeeper特点
最终一致性、可靠性、实时性、等待无关、原子性、顺序性、全局有序、偏序。
注释:
有序性:Zookeeper使用数字来对每一个更新进行标记。这样能保证Zookeeper交互的有序。后续的操作可以根据这个顺序实现诸如同步操作这样更高更抽象的服务。
实时性:
Zookeeper的实时,高效更表现在以读为主的系统上。Zookeeper可以在千台服务器组成的读写比例大约为10:1的分布系统上表现优异。