前言
继《 03-Kafka生产者–向Kafka写入数据(Java)》,该篇博客从写入的主题中读取消息。
环境:
Kafka-2.1.1 + Kafka 集群 + Eclipse
1. 读取消息
注意:Java 工程中需要导入依赖,如果不会或没有JAR 包可以参考: 链接。
ReadMessageSimple.java
package consumer_read;
import java.util.Collections;
import java.util.Properties;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
public class ReadMessageSimple {
public static void main(String[] args) {
// Properties 对象
Properties props = new Properties();
props.put("bootstrap.servers", "slave1:9092,slave2:9092,slave3:9092");
props.put("group.id", "CountryCounter"); // 消费者群组
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// consumer 对象
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
// 订阅主题
consumer.subscribe(Collections.singleton("CustomerCountry")); // 支持订阅多个主题,也支持正则
try {
while (true) {
// 0.1s 的轮询等待
@SuppressWarnings("deprecation")
ConsumerRecords<String, String> records = consumer.poll(1000);
System.out.println(records.count());
for (ConsumerRecord<String, String> record : records) {
// 输出到控制台
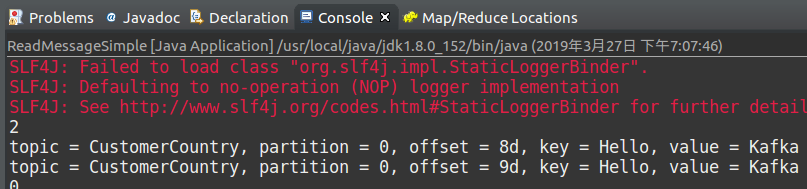
System.out.printf("topic = %s, partition = %s, offset = %sd, key = %s, value = %s\n",
record.topic(), record.partition(), record.offset(), record.key(), record.value());
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
consumer.close();
}
}
}
运行次序:
先运行发送消息(SendMessageSimple-代码见前言的链接),再运行读取消息(ReadMessageSimple)。
目前来说只能发送一次消息,读取一次。并且上次发送的还读取不到。推测原因就是:offset记录到了__consumer__offsets 主题中,新上线的消费者会从该主题中读取上个消费者读取后提交的offset。所以,感觉就是前面的数据已经丢失,生产者必须发送新的消息,消费者才会读取到,而以前的却不能读取。除非,设置读取的位置,后面会讲到。

控制台输出(这里运行了两次发送消息):
2. 消费者进阶之偏移量
提交的偏移量可能会导致如下两种情形:(博主这里有一个疑问,书上说)
- 该次提交大于上次的提交 – 造成数据的重复读取
- 该次提交小于上次的提交 – 造成数据的丢失

上面第1 节的代码使用的是自动提交偏移量,程序在轮询时提交。
每次调用轮询方法都会把上一次调用返回的偏移量提交上去,它并不知道具体哪些消息已经被处理了,所以在再次调用之前最好确保所有当前调用返回的消息已经处理完毕(调用close() 方法之前也会自动提交)-- 书上原话
下面介绍自定义提交偏移量
这部分有很多种提交的方式和组合,都是为了尽可能的避免数据的遗读或重复。
- 同步提交
同步提交的命令为:consumer.commitSync();
同步提交只要不发生不可恢复的错误,会一直尝试至提交成功,因此,会将降低程序的读取、处理速度。
在少量数据下,无法直观的看到偏移量的作用,因此,先生产大量的消息:
其余代码见 SendMessageSimple,在此基础上做如下修改:数据量不应该太小

先查看消息:
类:ReadMessageSync.java
package consumer_read;
import java.util.Collections;
import java.util.Properties;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
public class ReadMessageSync {
@SuppressWarnings("deprecation")
public static void main(String[] args) {
// Properties 对象
Properties props = new Properties();
props.put("bootstrap.servers", "slave1:9092,slave2:9092,slave3:9092");
props.put("group.id", "CountryCounter"); // 消费者群组
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// consumer 对象
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
// 订阅主题
consumer.subscribe(Collections.singleton("CustomerCountry")); // 支持订阅多个主题,也支持正则
try {
// 设置分区开头读取, 0表示立立即返回,无需等待
consumer.seekToBeginning(consumer.poll(0).partitions());
while (true) {
// 0.1s 的轮询等待
ConsumerRecords<String, String> records = consumer.poll(100);
System.out.println(records.count());
for (ConsumerRecord<String, String> record : records) {
// 输出到控制台
System.out.printf("topic = %s, partition = %s, offset = %sd, key = %s, value = %s\n",
record.topic(), record.partition(), record.offset(), record.key(), record.value());
}
// 同步提交偏移量
consumer.commitSync();
Thread.sleep(500);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
consumer.close();
}
}
}
第一次运行:
从开头读取消息,这行代码没有注释掉,即第一次运行会从头开始读取:
在读取到15186时,终止程序(点击控制台右上角的红色矩形):

第二次运行:
先注释掉从头开始读取消息这行代码:

运行:

从上图的运行结果看,11989完全衔接上了第一次运行的结果。
其实有点疑惑,按理说安全的数据不丢失或不重复是不可能的(书上原话),博主试了几次都是完全衔接上的。
或许是因为:1. 同步提交会一直等待响应的原因吧 2.实验环境太过简单 3.0.1s的等待足以完全打印消息到控制台,如果是插入到数据库等更复杂的操作可能有不一样的结果(个人推测)。
总之,上述就是使用同步提交偏移量的方法。
- 异步提交
异步提交的命令为:consumer.commitAsync();
异步提交不会等待broker 的响应,而是只管发送,不管是否成功。提高了应用程序吞吐量,但下次读取消息的遗失或重复可能性大大提升。
ReadMesAsync.java
代码与同步相同,只需要修改一行:

经博主实验运行,异步提交也是完全的衔接读取的消息。
或许,在实验环境只是单一的终止相关。而实际的应用中,会发生不可预测的错误,这就造成即使有提交偏移量,也会造成数据的丢失或重复。(个人推测)
-
同步异步组合提交
同步和异步的组合比使用单种提交的方式的提交成功性更大。
只需做如下修改:

-
提交特定偏移量
在上述的提交中,我们处理数据的方式只是打印到控制台。如果我们将数据插入到数据库,可能0.1s 的等待时间不足以将拉取的所有消息写入数据库。
然而,偏移量同步的语句是在完全打印完数据后再执行的。那么,就可能造成数据没有完全打印、提交语句未执行。但下一批的消息已经拉取过来,又将重新开始处理新的数据。即造成,遗漏提交偏移量。如果,发生错误,等下次消费者再次读取会使用上次成功提交的偏移量,那将会造成部分数据的重复读取。
所以,为了尽可能的降低这种错误,我们可能会牺牲应用的吞吐量,提高偏移量提交的次数。
相应代码如下:

经博主实验,这种方式会造成重复读取大概一个轮询的数据。
3. 再均衡监听器
本节部分也是关于偏移量的知识,但却比上一节有更多的方法,如API。
消费者在退出和进行分再均衡之前,会做一些清理工作。
你会在消费者失去对一个分区的所有权之前提交最后一个已处理记录的偏移量。如果消费者准备了一个缓存区用于处理偶发的事件,那么在失去分区所有权之前,需要处理在缓冲区积累下来的记录。如关闭文件句柄、数据库连接等。
在为消费者分配新分区或移除旧分区时,可以通过消费者API执行一些应用程序代码,在调用subscribe() 时传进去一个ConsumerRebalanceListener 实例即可。
该类有两个需要实现的方法:
- public void onPartitionsRevoked(Collection< TopicPartition> partitions) 方法,会在再均衡之前和消费者停止读取消息之后被调用。
- public void onPartitionsAssigned(Collection< TopicPartition> partitions) 方法,会在重新分配分区之后和消费者读取消息之前被调用。
–《Kafka 权威指南》
明天继续。。。