一.自我代码分析
1.度量:
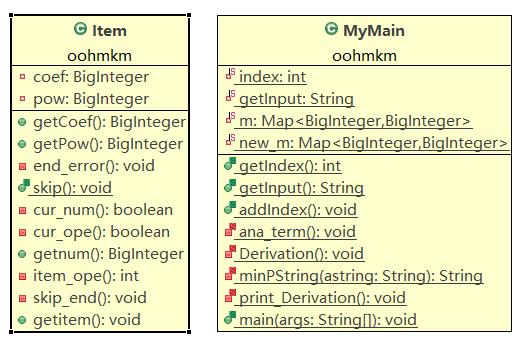
第一次作业:
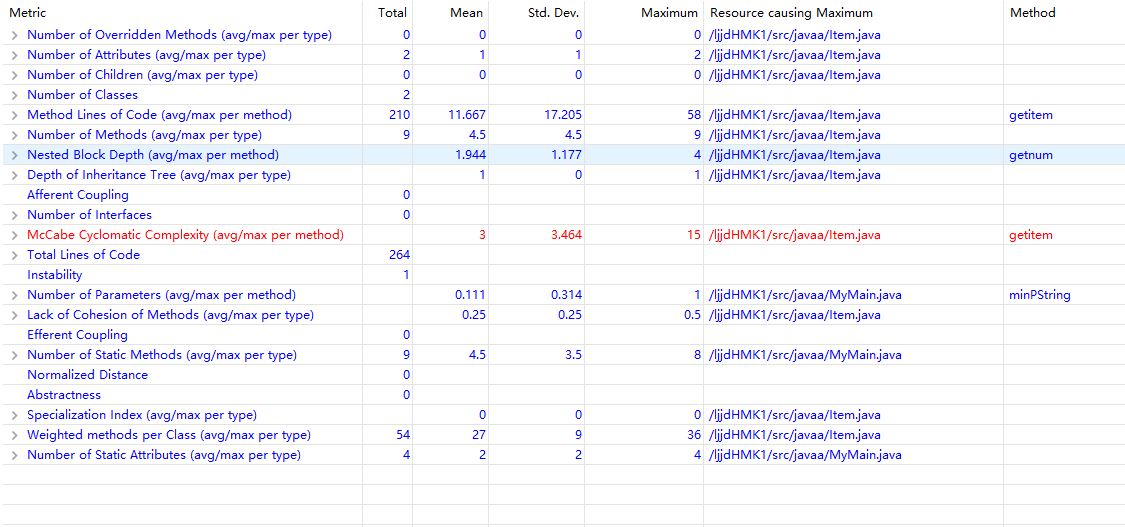
第二三次作业(改动很小,给出第三次作业结果):

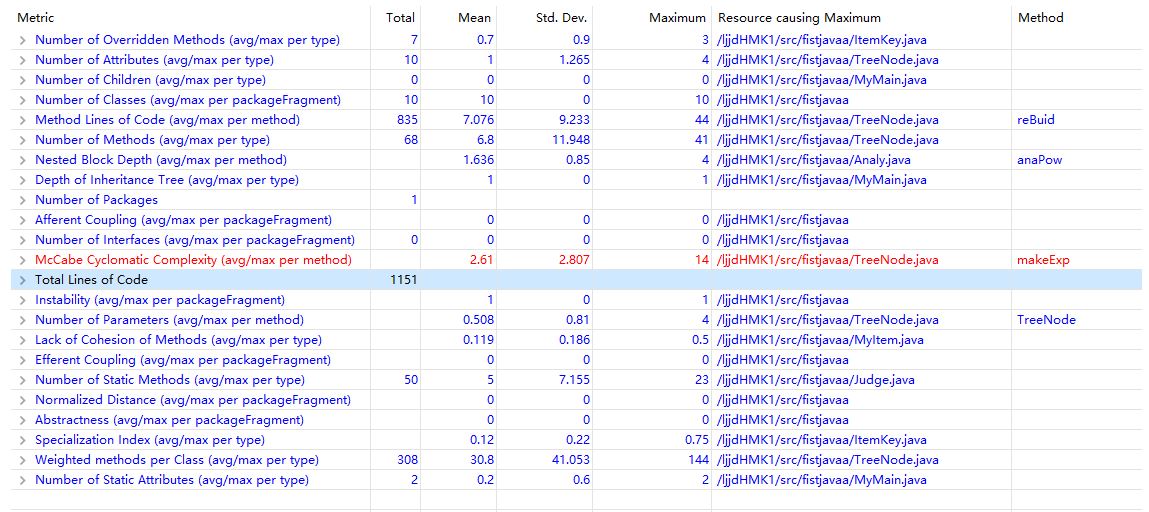
2.总体自我评价:
第一次作业代码实现糟糕,可以从代码统计结果看到这一点,第二三次感觉比较满意,思路顺畅方法简单可扩展性强但面向对象思想还不够(甚至没有继承和接口),倒算是比较精致的面向过程,不过类的高内聚低耦合倒是实现得不错
3.详细分析
总之,我三次小作业的代码是逐渐迭代优化的,不管是思路上还是结构上。
第一次作业较为简单,可是我的思路相对于后两次却是最复杂的,由于当时没有确立面向对象思想,整个java项目就是个面向过程的伪c程序——在一个Item类里定义了许多静态方法,然后在main里调用(没错,只有这两个类),甚至连求导都是在输出时直接拼凑字符串一项一项输出,优化也是直接在字符串上操作。
第一次作业较简单,我实现的也极为糟糕,所以接下来重点谈后两次作业,由于后两次作业我的思路完全一致,几乎没有改动,所以这里就一起说了。
第二次作业布置下来后,虽然还没有要求括号嵌套(或者说还没有要求表达式因子的处理)。可是我已经预感到了将来一定是要处理涉及递归定义的表达式的(下意识地就想到了编译课设的表达式)。所以我先写了一个小小的词法分析程序来切出运算符、变量等,多亏了上学期的编译,所以这下写起来是轻车熟路。词法分析共定义了以下几个类:

所有函数的命名和功能都和编译课设的保持一致(再复习一下),Symenum,枚举类型,定义了标识符;Judge(里面全是静态方法,高内聚),我把所有词法分析用到的boolean返回类型都放到了这里;cut,切出带符号整数、变量的字符串等等(当时未雨绸缪,假设变量不只有x)。需要注意的是我的程序把读入的表达式作为全局变量(main函数里的public静态变量),把当前分析到的字符串下标也设置为了public静态变量,所以可以看到我的这些函数有许多未传入参数。至于checkindex这个参数本来是想进行预读的,不过后来也没用到预读。
熟悉编译的同学都知道,词法分析之后就该语法语义分析了,至于错误处理?在这个过程中if else 顺手就处理了。可能还是面向过程思想有点重吧,我虽然想到了要定义个表达式类、项类、因子类、运算符类等,可还是没能实现,而是忍不住顺着编译的思路再写了个表达式分析:
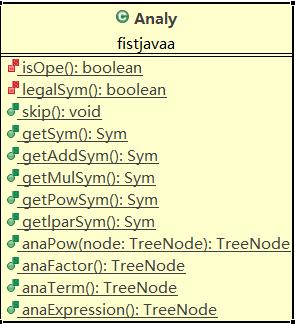
单看返回值就很明了了,我用了树。就是把运算符做中间节点、变量或常量做叶子的树(一元运算符只有左孩子),这样设计一来是较为直观,构造时anafactor等这些函数只需要返回个节点然后让调用者挂在已有的树上(这是个递归的过程),二来树结构递归求导很方便。上源码:

这里只给出了anafactor的代码,第二次作业不允许表达式因子,就在分析出表达式因子不是x时报错,第三次作业调用anaexpression函数就是。
这样,分析完输入字符串,我就得到了一颗表达式树,怎么管理树呢,自然是再来个类;
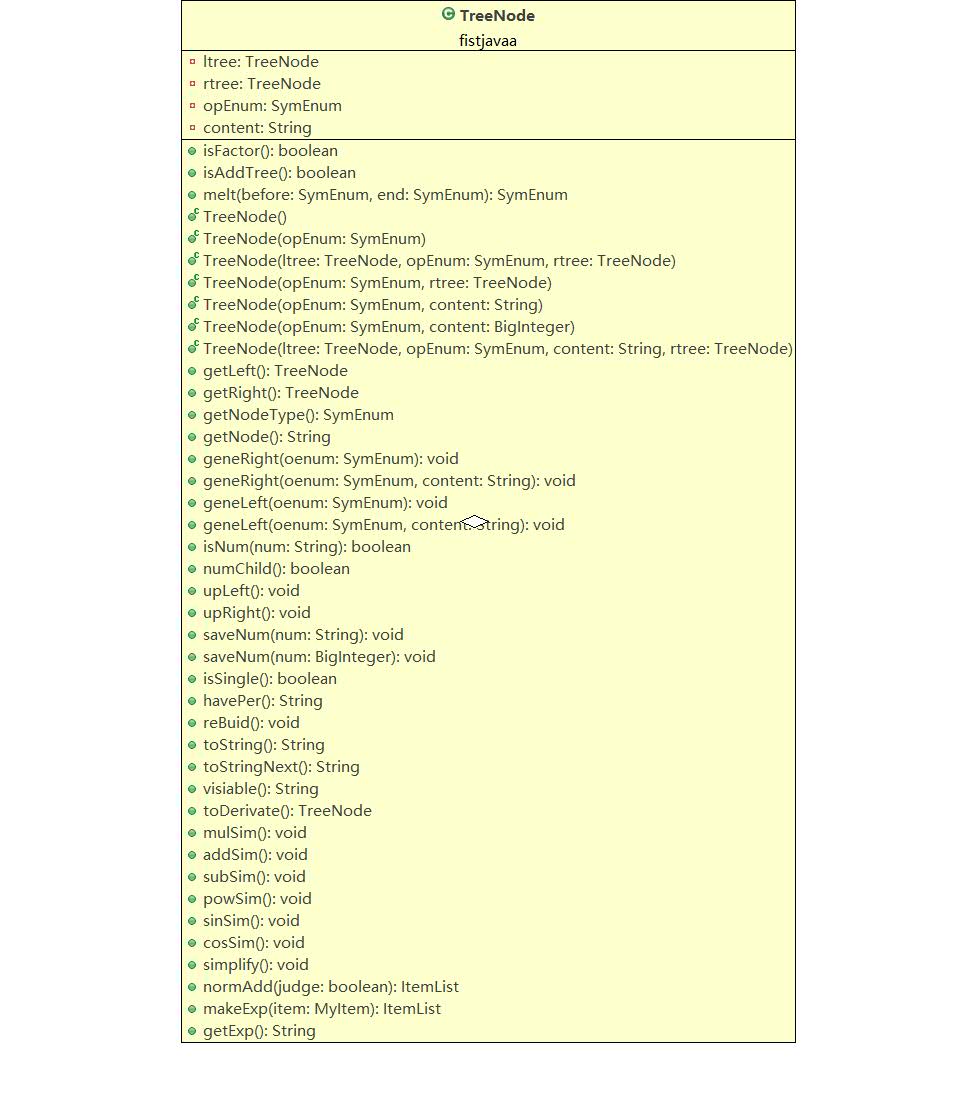
这是个大家伙……直逼上限五百行(489),我程序的核心功能几乎都在这个树上(求导、优化、输出)。先说求导:
在表达式树上求导是个十分简单的过程,是个递归的过程,我设计的是求导得到一棵新树,对应不同运算符生成不同的树就行了:

然后是优化,我的优化分为两部分,一个是剪枝,一个是合并同类项。
剪枝:
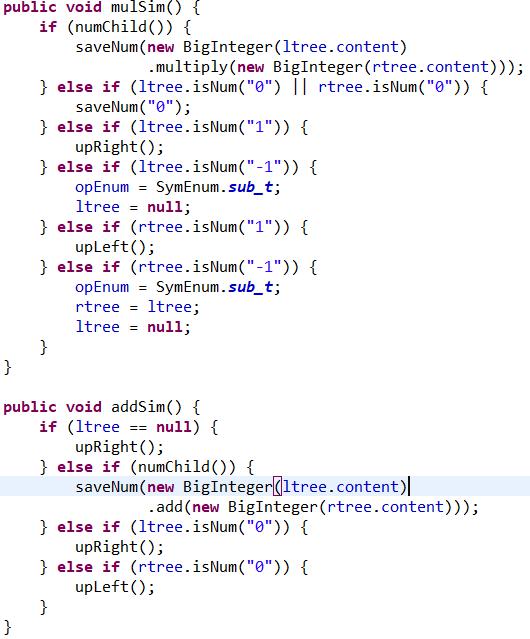

剪枝主要就是剪掉或化简一些0啊1啊参加运算的的树枝,这是很有必要的,因为一旦机械地按照求导规则求导,会产生许多乘0啊乘1啊,将他们优化掉会大大提高性能,我第二次作业在这上面吃了大亏,求完导不剪枝,直接重构(一会说重构,这是第二次作业的特殊情况),运算量很大,强测直接有四个点超时,差点挂了。
刚才提到了重构,这里解释一下,重构也就是展开括号,因为第二次作业括号里只允许有x,而我的表达式树直接输出的话一定要给优先级低的运算符加括号的,所以需要在树上摘摘挂挂变化把低优先级的运算符提到高优先级运算符上层,这样递归输出不必加括号结果也是正确的。附上代码,有兴趣的同学可以看看(就是小学的乘法分配律):


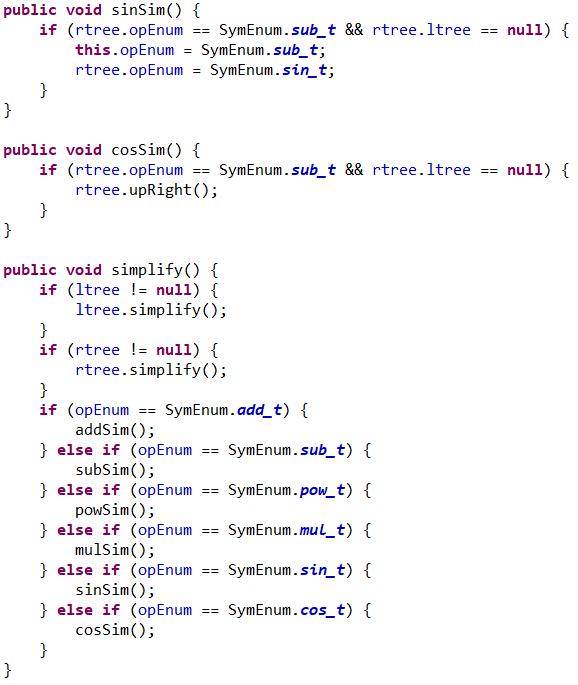
第二阶段的优化就是合并同类项了,我的思路是每个节点有个综合属性,有个继承属性,继承属性从根向下传递,遇到加减号停止传递,遇到乘号继续向两颗子树下传递;综合属性从叶子向上传,遇到加减号继续向上传,遇到乘号乘入乘号的继承属性并停止下传。用形象点的语言说,就是每个运算符先得到它左孩子的表达式,再得到它右孩子的表达式(这里的表达式不是string,是数据结构),然后根据这个运算符的类别进行两个表达式的合并,将合并后的表达式向上传(因为是递归程序,所以可以自下向上传递)。代码:


二.bug分析
我此次测试出的bug分为两种:其一为对规则理解不透彻准确的bug,其二为自己手抖的“笔误型”bug。
第一类bug印象较深的有两处,一次是第二次作业的弱测有一个输入是“什么都不输入”,注意这还不是输入空串,我是用try catch解决的。第二次就是对输出的字符串格式要求和输入一致,我一开始没仔细理解这句话,导致输出的格式不对,所以后来我会把每次的输出字符串再扔进程序跑一遍,二次迭代(二阶导)也正确就说明程序出bug的可能性更小。
第二类bug就是我把一处“cos”写成了“sin”,为此还跟踪了挺长时间,以后要更仔细些。
值得庆幸的是并没有因为程序错误或混乱而出现的bug,我觉得这种bug可能更难解决吧,所以编程前一定要有清晰的构思,确保自己的方案是正确的。
总体来说,bug在输入输出处理及逻辑较复杂、代码较长的方法里出现的频率更高些,我的解决方法一般是写完一个小功能(如词法分析)就测试一下,防止bug积累,日后面对长长的几千行代码,bug就更难找。
另外关于测试的一点体会,其实测试样例也不一定要越复杂越好,尤其是涉及到递归程序时,其实只要一层对了、两层对了,bug出现的概率也不大了,更深层的测试也不能说明更多,反而一味追求输入复杂度可能漏掉其他的一些分支,因此要理智地分析不同类型、不同分支的输入,争取实现全覆盖(至于代码覆盖,eclipse有自带的插件,还是很方便的)。
三.尝试重构
仍然采用树结构,但是树节点及页节点定义一个父类,对不同的运算符、数字、变量定义不同的子类,重载求导、优化等方法,减少自己的判断语句及分支。