1. 多进程编程理解
一个进程,表示只有一个餐厅座位,客户依次等待
多进程
前台: 表示 父进程/主线程
餐厅内服务员: 表示 子进程
正在运行的程序及其占用的资源(CPU、内存、系统资源等)叫做进程
编译器gcc编译生成CPU可识别的二进制可执行程序并保存在存储介质上
而一旦我们通过命令(./a.out)开始运行时,那正在运行的这个程序及其占用的资源就叫做进程了
2. 进程空间内存布局
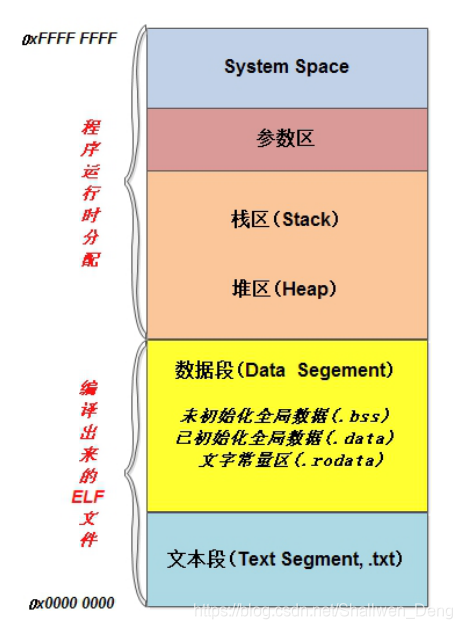
编译出来的ELF文件:
数据段:未初始化全局变量(.bss)已初始化全局变量(.data)文字常量区(.rodata)
文本段:代码
程序运行时分配 :
参数区:命令行传来的参数
栈区:函数内的参数
堆区:malloc()free( )
Linux 内存管理的基本思想就是只有在真正访问一个地址的时候才建立这个地址的物理映射,Linux C/C++语言的分配方式共有3 种方式。
(1)从静态存储区域分配。就是数据段的内存分配,这段内存在程序编译阶段就已经分配好,在程序的整个运行期间都存在,例如全局变量,static变量。
(2)在栈上创建。在执行函数时,函数内局部变量的存储单元都可以在栈上创建,函数执行结束时这些存储单元自动被释放。栈内存分配运算内置于处理器的指令集中,效率很高,但是系统栈中分配的内存容量有限,比如大额数组就会把栈空间撑爆导致段错误。
(3)从堆上分配,亦称动态内存分配。程序在运行的时候用 malloc 或 new 申请任意多少的内存,程序员自己负责在何时用free 或delete 释放内存。此区域内存分配称之为动态内存分配。动态内存的生存期由我们决定,使用非常灵活,但问题也最多,比如指向某个内存块的指针取值发生了变化又没有其他指针指向这块内存,这块内存就无法访问,发生内存泄露。
3. fork()系统
fork英文意思:叉子

Linux下有两个基本的系统调用可以用于创建子进程:fork()和vfork()。
fork在英文中是"分叉"的意思。为什么取这个名字呢?因为一个进程在运行中,如果使用了fork,就产生了另一个进程,于是进程就”分叉”了,所以这个名字取得很形象。
一次返回是给父进程,其返回值是子进程的PID(Process ID),第二次返回是给子进程,其返回值为0。所以我们在调用fork()后,需要通过其返回值来判断当前的代码是在父进程还是子进程运行,如果返回值是0说明现在是子进程在运行,如果返回值>0说明是父进程在运行,而如果返回值<0的话,说明fork()系统调用出错。
4. fork()系统调用
Linux内核在启动的最后阶段会创建init进程来执行程序/sbin/init,该进程是系统运行的第一个进程,进程号为 1,称为Linux 系统的初始化进程,该进程会创建其他子进程来启动不同写系统服务,而每个服务又可能创建不同的子进程来执行不同的程序。
所以init进程是所有其他进程的“祖先”,并且它是由Linux内核创建并以root的权限运行,并不能被杀死。
Linux 中维护着一个数据结构叫做进程表,保存当前加载在内存中的所有进程的有关信息,其中包括进程的 PID(Process ID)、进程的状态、命令字符串等,操作系统通过进程的 PID 对它们进行管理,这些 PID 是进程表的索引。
每个子进程只有一个父进程,并且每个进程都可以通过**getpid()获取自己的进程PID,也可以通过getppid()**获取父进程的PID,这样在fork()时返回0给子进程是可取的。一个进程可以创建多个子进程,这样对于父进程而言,他并没有一个API函数可以获取其子进程的进程ID,所以父进程在通过fork()创建子进程的时候,必须通过返回值的形式告诉父进程其创建的子进程PID。这也是fork()系统调用两次返回值设计的原因。
下面我们以一个简单的程序例子来讲解一下进程的创建过程。
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#include <errno.h>
int main(int argc, char **argv)
{
pid_t pid;
printf("Parent process PID[%d] start running...\n", getpid() );
pid = fork();
if(pid < 0)
{
printf("fork() create child process failure: %s\n", strerror(errno));
return -1;
}
else if( pid == 0 )
{
printf("Child process PID[%d] start running, my parent PID is [%d]\n", getpid(),
getppid());
return 0;
}
else // if( pid > 0 )
{
printf("Parent process PID[%d] continue running, and child process PID is [%d]\n",
getpid(), pid);
return 0;
}
}
gcc fork.c -o fork
./fork
Parent process PID[26765] start running...
Parent process PID[26765] continue running, and child process PID is [2676]
Child process PID[26766] start running, my parent PID is [26765]
fork()系统调用会创建一个新的子进程,这个子进程是父进程的一个副本。这也意味着,系统在创建新的子进程成功后,会将父进程的文本段、数据段、堆栈都复制一份给子进程,但子进程有自己独立的空间,子进程对这些内存的修改并不会影响父进程空间的相应内存。这时系统中出现两个基本完全相同的进程(父、子进程),这两个进程执行没有固定的先后顺序,哪个进程先执行要看系统的进程调度策略。如果需要确保让父进程或子进程先执行,则需要程序员在代码中通过进程间通信的机制来自己实
现。
我们知道main()函数里的return()会调用exit()函数,而在任何函数的任何位置如果调用 exit()将会导致进程退出。而子进程在23行调用了return 0,所以这时候子进程在执行完22行的打印后就退出了。同理父进程在程序第29行也退出了。同理父进程在程序第29行也退出了。
这里我们需要注意的是: 在编程时,任何位置的exit()函数调用都会导致本进程(程序)退出,main()函数中的return()调用也会导致进程退出,而其他任何函数中的return()都只是这个函数返回而不会导致进程退出。