多线程读取数据的机制
tf中多线程读取数据跟常规的python多线程思路一致,是基于Queue的多线程编程。
主线程读取数据,然后计算,在读数据这部分有两个线程,一个线程读取文件名,生成文件名队列,另一个线程从文件名队列中获取文件名,并读取相应文件,生成数据队列。
图示如下
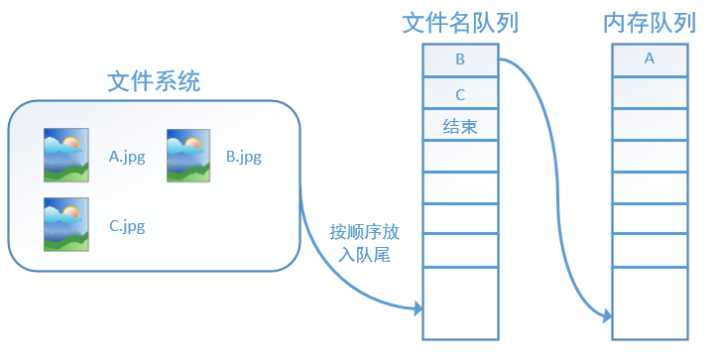
tensorflow 在队列中加入“结束”标记符,当读取线程检测到该标记符时,会抛出异常OutOfRange,后续代码会捕捉该异常,从而结束线程。
读取文件的相应函数
tf.train.string_input_producer(filelist, shuffle, num_epochs)
用于生成文件名队列,3个参数,filelist代表文件名list,num_epochs表示epochs数,shuffle是指在一个epoch内,文件的顺序是否被打乱。
reader对象
reader对象由文件类型对应的读取方法生成,该对象会自动读取文件,并创建数据队列,输出key/文件名,value/文件内容
tf.train.start_queue_runners
注意,在调用tf.train.string_input_producer后,文件名并没有被真正加入文件名队列,而只是创建了一个空队列,此时如果直接计算,系统会陷入阻塞状态。
此时需要启动队列,就是调用tf.train.start_queue_runners。
读取图片示例
# encoding:utf-8 __author__ = 'HP' import tensorflow as tf # 新建一个Session with tf.Session() as sess: # 文件名list filename = ['2.png', '3.png'] # string_input_producer会产生一个文件名队列 filename_queue = tf.train.string_input_producer(filename, shuffle=False, num_epochs=2) # reader从文件名队列中读数据。对应的方法是reader.read reader = tf.WholeFileReader() key, value = reader.read(filename_queue) # tf.train.string_input_producer定义了一个epoch变量,要对它进行初始化 tf.local_variables_initializer().run() # 使用start_queue_runners之后,才会开始填充队列 threads = tf.train.start_queue_runners(sess=sess) i = 0 while True: i += 1 # 获取图片数据并保存 image_data = sess.run(value) with open('test_%d.jpg' % i, 'wb') as f: f.write(image_data)
输出四张图片

两张图片,两个epoch,生成了4张图片。(图片每次读取全部数据)
队列
上面提到各种队列,tf与python一样,有多种队列
tf.FIFOQueue 先入先出
tf.RandomShuffleQueue 随机出队
tf.PaddingFIFOQueue 以固定长度批量出列的队列
tf.PriorityQueue 带优先级出列的队列
使用逻辑都类似
tf.FIFOQueue(capacity, dtypes, shapes=None, names=None ...)
简单例子 (需要理解python的队列使用)
import tensorflow as tf tf.InteractiveSession() q = tf.FIFOQueue(2, "float") # 最多2个元素 init = q.enqueue_many(([0,0],)) # 初始化队列 x = q.dequeue() # get y = x+1 q_inc = q.enqueue([y]) # put init.run() ## 初始化队列[0, 0] # print(x.eval()) # 0.0 # print(x.eval()) # 0.0 q_inc.run() ## get 0 +1 put 1, 队列变成 [0, 1] q_inc.run() ## get 0 +1 put 1,队列变成 [1, 1] q_inc.run() ## get 1 +1 put 2,队列变成 [1, 2] print(x.eval()) ## get 1 print(x.eval()) # get 2.0 x.eval() # 阻塞
enqueue_many 生成队列,enqueue put元素,dequeue get元素
tf多线程
tf提供了两个类来实现多线程协同的功能。分别是 tf.Coordinator() and tf.QueueRunner()。
tf.Coordinator()
tf.Coordinator()主要用于协同多个线程一起停止,包括 should_stop、 request_stop、 join 三个接口。
实现机制:
在启动线程前,先创建Coordinator类的实例对象coord,并将coord传给每一个线程,每个线程要不断检测这个实例的 should_stop 方法,如果返回True,就停止,
并且可以启动这个实例的 request_stop 方法(任意线程都可随时启动这个方法),这个方法会通知其他线程,一起结束,而且一旦这个方法被调用,should_stop方法就会返回True,其他线程都会结束。
示例代码
__author__ = 'HP' # coding utf-8 import tensorflow as tf import numpy as np import threading import time # 线程中运行的程序,这个程序每隔1秒判断是否需要停止并打印自己的ID。 def MyLoop(coord, worker_id): # 使用tf.Coordinator类提供的协同工具判断当前线程是否需要停止并打印自己的ID while not coord.should_stop(): # 人为制造一个停止的条件 if np.random.rand() < 0.1: print('Stoping from id: %d\n' % worker_id) # 调用coord.request_stop()函数来通知其他线程停止 coord.request_stop() else: # 打印当前线程的ID print('Working on id: %d\n' % worker_id) # 暂停1秒 time.sleep(1) # 声明一个tf.train.Coordinator类来协同多个线程 coord = tf.train.Coordinator() # 声明创建5个线程 threads = [threading.Thread(target=MyLoop, args=(coord, i, )) for i in range(5)] # 启动所有的线程 for t in threads: t.start() # 等待所有线程退出 coord.join(threads)
输出
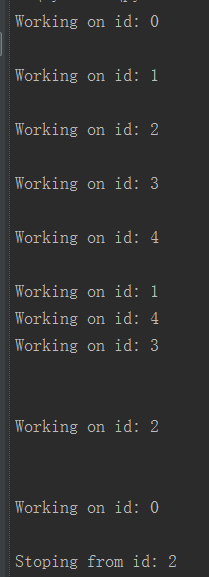
可以看到,一旦一个线程结束了,其他线程也跟着结束。
tf.QueueRunner()
tf.QueueRunner()用来同时启动多个线程操作同一个队列。并借助 tf.Coordinator()对线程进行管理。
示例代码
import tensorflow as tf # 声明一个先进先出的队列,队列中最多n个元素,类型 queue = tf .FIFOQueue(10, 'float') # 定义队列的入队操作 enqueue_op = queue.enqueue([tf.random_normal([1])]) # 使用 tf.train.QueueRunner来创建多个线程运行队列的入队操作 # tf.train.QueueRunner给出了被操作的队列,[enqueue_op] * 5 # 表示了需要启动5个线程,每个线程中运行的是enqueue_op操作 qr = tf.train.QueueRunner(queue, [enqueue_op] * 5) # 将定义过的QueueRunner加入TensorFlow计算图上指定的集合 # tf.train.add_queue_runner函数没有指定集合, # 则加入默认集合tf.GraphKeys.QUEUE_RUNNERS。 # 下面的函数就是将刚刚定义的qr加入默认的tf.GraphKeys.QUEUE_RUNNERS结合 tf.train.add_queue_runner(qr) # 定义出队操作 out_tensor = queue.dequeue() with tf.Session() as sess: # 使用tf.train.Coordinator来协同启动的线程 coord = tf.train.Coordinator() # 使用tf.train.QueueRunner时,需要明确调用tf.train.start_queue_runners # 来启动所有线程。否则因为没有线程运行入队操作,当调用出队操作时,程序一直等待 # 入队操作被运行。tf.train.start_queue_runners函数会默认启动 # tf.GraphKeys.QUEUE_RUNNERS中所有QueueRunner.因为这个函数只支持启动指定集合中的QueueRunner, # 所以一般来说tf.train.add_queue_runner函数和tf.train.start_queue_runners函数会指定同一个结合 threads = tf.train.start_queue_runners(sess=sess, coord=coord) # 获取队列中的取值 for _ in range(11): print(sess.run(out_tensor)[0]) # 使用tf.train.Coordinator来停止所有线程 coord.request_stop() coord.join(threads)
同时启动多个线程,每个线程每次运行都将一个随机数写入队列,所以每次都能取到一个随机数。
用法小结
1. 创建多线程,方法是 tf.QueueRunner(aim_queue, [operation] * thread_num),目标队列,创建n个线程,执行某操作
2. 然后将多线程加入 tensorflow 节点,
3. 然后显示的调用 start_queue_runners 启动所有线程
tf 多线程读取文件
csv
import tensorflow as tf # 文件名队列 filename_queue = tf.train.string_input_producer(["xx1.csv", "xx2.csv"], shuffle=False) # reader对象 (文件阅读器) reader = tf.TextLineReader() key, value = reader.read(filename_queue) # 为数据设定默认格式,如果出现空值,就替换为这种格式的默认值。 # 注意格式必须一样,因为输出的格式是统一的,如下 # [array([ 4. , 0. , 34.322323, 1. ], dtype=float32)] record_defaults = [[1.], [1.], [1.], [1.]] col1, col2, col3, col4 = tf.decode_csv(value, record_defaults=record_defaults) # decode_csv features = tf.concat([[col1], [col2], [col3], [col4]], 0) with tf.Session() as sess: # Start populating the filename queue. coord = tf.train.Coordinator() threads = tf.train.start_queue_runners(coord=coord) # 启动队列,相当于是启动了多个线程,并将coord传入每个线程 for i in range(12): example = sess.run([features]) print(example) coord.request_stop() # coord.join(threads) # 等待结束
文件阅读器每次从文件内读取一行,如果有空值,就根据默认格式自动填补,decode_csv 将读取内容解析成张量。
将上述代码与QueueRunner代码对比,不难发现,其实 string_input_producer 生成的就是一个 QueueRunner。
参考资料:
http://www.cnblogs.com/demian/p/8005407.html
https://www.cnblogs.com/yinghuali/p/7506073.html#top
https://blog.csdn.net/qq_37423198/article/details/80524600
http://wiki.jikexueyuan.com/project/tensorflow-zh/how_tos/reading_data.html
https://blog.csdn.net/s_sunnyy/article/details/72924317