子查询
单行子查询和多行子查询
单行子查询:子查询只返回一条记录
多行子查询:子查询返回多条记录
查询工资比scott的员工信息
1.scott的工资
2.查询比3000工资高的员工

注意:
- 括号
- 合理的书写风格
- 可以在主查询的where select having from 后面使用子查询
- 不可以在group by使用子查询
- 强调from后面的子查询
- 可以不是一张表,只要子查询返回的结果 主查询可以使用即可
- 一般不在子查询中排序,对主查询没有意义,但在top-n分析问题中,必须对子查询排序
- 子查询也叫做(内查询)在主查询之前一次执行完成, 子查询的结果被主查询使用
- 一般先执行子查询,再执行主查询,但相关子查询例外
- 单行子查询只能使用单行操作符,多行子查询只能使用多行操作符
- 子查询中的null值,not in(10,20,null)中,含有null不能使用not in,但是可以使用in
- 原因:单行子查询中的null值.多行子查询中的null值.
3.可以在主查询的where select having from 后面使用子查询
select empno,ename,sal,(select job from emp where empno=7839) 第四列 from emp

5.强调from后面的子查询
查询员工信息:员工号 姓名 月薪
 查询员工信息:员工号 姓名 月薪 年薪
查询员工信息:员工号 姓名 月薪 年薪
 6.可以不是一张表,只要子查询返回的结果 主查询可以使用即可
6.可以不是一张表,只要子查询返回的结果 主查询可以使用即可
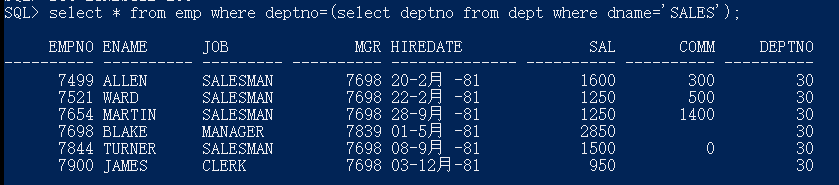
查询部门名称市sales的员工
select * from emp where deptno=(select deptno from dept where dname=‘SALES’);
 select e.*
select e.*
from emp e,dept d
where e.deptno=d.deptno and d.dname=‘SALES’;
 子查询在执行的时候是转换成多表查询来执行的.
子查询在执行的时候是转换成多表查询来执行的.
SQL执行计划
7.单行子查询只能使用单行操作符,多行子查询只能使用多行操作符
 多行子查询(重点):
多行子查询(重点):
 in在集合中
in在集合中
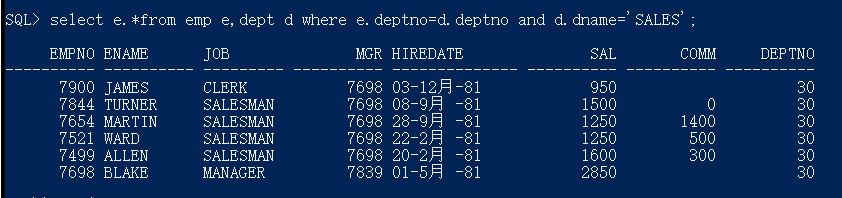
查询部门名称是sales和accounting的员工
select * from emp where deptno in(select deptno from dept where dname=‘SALES’ or dname=‘ACCOUNTING’)

select e.* from emp e,dept d where e.deptno=d.deptno and (d.dname=‘SALES’ or d.dname=‘ACCOUNTING’) any:和合集中的任意一个值比较
any:和合集中的任意一个值比较
查询工资比30号部门任意一个员工高的员工信息
select *
from emp
where sal >any (select sal from emp where deptno=30) 查询工资比30号部门任意一个员工低的员工信息
查询工资比30号部门任意一个员工低的员工信息
select *
from emp
where sal <any (select sal from emp where deptno=30)

all:表示我们要和集合中的所有元素比较
查询工资比30号部门所有员工高的员工信息
select *
from emp
where sal >all(select sal from emp where deptno=30)
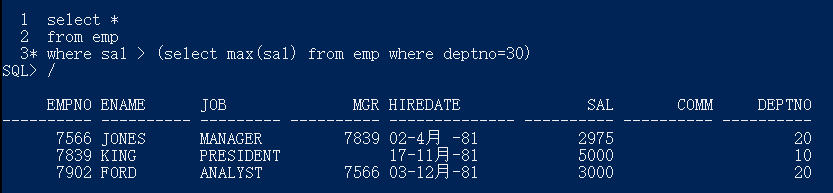
 select *
select *
from emp
where sal > (select max(sal) from emp where deptno=30);
 单行子查询中的null值问题
单行子查询中的null值问题
查询是老板的员工
 所有和空值比较的值返回的值都是空值,有空值不要使用not in
所有和空值比较的值返回的值都是空值,有空值不要使用not in
查询所有不是老板的员工
select *
from emp
where empno not in(select mgr from emp where mgr is not null)
集合运算

注意事项:
- 1.参与运算的各个集合必须列数相同且类型一致
- 2.采用第一个集合作为最后的表头
- 3.order by 永远在最后
- 4.可以使用括号改变顺序
SQL的类型
- DML:数据操作语言 select insert update delete
- DDL:数据定义语言 create/drop viewsequence,index,synonym;
- DCL:数据控制语言 grant(授权) revoke(撤销权限)
insert插入语句
insert into emp (empno,ename,sal,deptno) values(1001.‘TOM’,3000,10);

地址符&:SQL语句中都可以使用
PreparedStatement pst = "insert into emp (empno,ename,sal,deptno)
values(&empno,&ename,&sal,&deptno); "
 select empno,ename,sal,&t from emp;
select empno,ename,sal,&t from emp;

select * from &t;
 一次插入多条记录
一次插入多条记录
 一次性将emp中,所有10号部门的员工插入到emp10中
一次性将emp中,所有10号部门的员工插入到emp10中
在insert语句中使用子查询
注意:
不用书写values子句
子查询中的值列表应与insert子句中的列明对应
insert into emp10 select * from emp where deptno=10;
 海量的插入数据的时候:
海量的插入数据的时候:
1.数据泵(PLSQL程序)
dbms_datapump(程序包)
2.SQL*Loader
3.外部表
update语句中使用子查询:
数据的完整性:
创建在表中的约束
在oracle中约束的级别?
delete删除数据:
delete from 表名 where 删除条件;
如果不加删除条件的话,就会删除所有数据
=
Truncate table 表的数据擦除
Truncate与delete的区别
1.delete逐条删除,Truncate先摧毁表,在重建表
2(重要).delete是DML语句 Truncate是DDL语句
DML(可以回滚) DDL(不可以回滚)
3.delete不会释放空间,Truncate会
4.delete会产生碎片,Truncate不会
- 去掉碎片:
- alter table<表名> move;
- 数据的导出和导入
- mysql:导出文本文件
- oracle:导出dmp文件 exp imp expdp impdp
5.delete会闪回(flashback),Truncate不可以
delete删掉 comit之后 发现删错了 就可以闪回
flashback其实就是一种恢复
 原因:undo数据(还原数据) 这是oracle中非常重要的功能
原因:undo数据(还原数据) 这是oracle中非常重要的功能
Oracle中的事务
1.起始标志:事务中的第一条DML语句(Oracle自动开启事务)
2.结束标志:提交:显式 commit 隐式:正常退出 DDL DCL(创建表,同时提交事务);回滚 显式 rollback 隐式:非正常推出 掉电 宕机
3.事务之前可以通过savepoint a设置保存点.
rollback to savepoint a 回滚到保存点a
事务的隔离级别:
Oracle支持的3中事务隔离级别:READ COMMITED,SERIALIZABLE,READ ONLY
读已提交,串行化,只读 默认为:读已提交
mysql的四种隔离级别:
读未提交数据 | 读已提交数据 | 可重复读 | 串行化
课堂练习
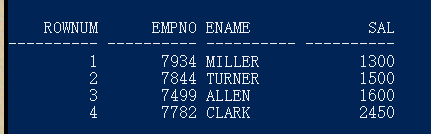
找到员工表中工资最高的前三名
ROWNUM伪列,行号
关于行号:
1.rownum永远按照默认的顺序生成(不能用order by)
2.rownum只能使用< <=,不能使用 > >=
select rownum,empno,ename,sal
from (select * from emp order by sal desc)
where rownum<=3
 2.rownum只能使用< <=,不能使用 > >=
2.rownum只能使用< <=,不能使用 > >=
rownum永远从1开始
分页的时候:
select rownum,empno,ename,sal
from (select rownum r,e1.*
from (select * from emp order by sal) e1
where rownum <=8
)
where r >=5;
找到员工表中薪水大于本部门平均工资的员工
select e.deptno,e.empno,e.ename,e.sal,d.avgsal
from emp e,(select deptno,avg(sal) avgsal from emp group by deptno) d
where e.deptno=d.deptno and e.sal > d.avgsal
order by 1
 相关子查询:
相关子查询:
将主查询中的值,作为参数传递给子查询
一般的子查询,先执行子查询在执行主查询;而相关子查询,先执行主查询再执行子查询
select deptno,empno,ename,sal,(select avg(sal) from emp where deptno=e.deptno) avgsal
from emp e
where sal > (select avg(sal) from emp where deptno=e.deptno)
order by 1

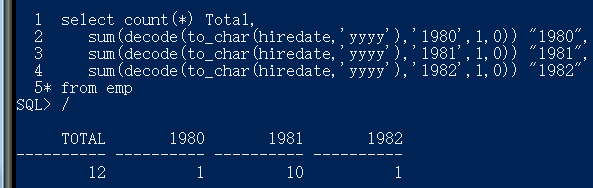
统计每年入职的员工个数(不许使用子查询)
select count(*) Total,
sum(decode(to_char(hiredate,‘yyyy’),‘1980’,1,0)) “1980”,
sum(decode(to_char(hiredate,‘yyyy’),‘1981’,1,0)) “1981”,
sum(decode(to_char(hiredate,‘yyyy’),‘1982’,1,0)) “1982”
from emp
行转列
select deptno,LISTAGG(ename,’,’)within group(order by deptno) nameslist
from emp
group by deptno

使用DDL语句管理表
rowid行地址 伪列
创建表create table emp10 as select * from emp where 1=2;
只创建表结构,不创建数据
创建表:保存20号部门的员工
create table emp20 as select * from emp where deptno=20;
create table empinfo
as
select e.empno,e.ename,e.sal,e.sal12 annsal, d.dname from emp e,dept d
where e.deptno=d.deptno

创建视图:
create view empinfoview
as
select e.empno,e.ename,e.sal,e.sal12 annsal, d.dname from emp e,dept d
where e.deptno=d.deptno
修改表:
增加一个列
修改现有的列
删除列
重命名列
重命名表





drop table删除表(只是将表放到了oracle的回收站了)
查看回收站 show recyclebin;
清空回收站 purge recyclebin;
直接删除:drop table test1 purge;
oracle 并不是所有的人都有回收站(管理员没有回收站)
闪回删除 flashback table test1 to before drop;
闪回数据归档
闪回表
闪回查询
闪回版本查询
闪回事务查询
闪回数据库
 约束的级别:
约束的级别:
列级约束 表级约束(联合主键)
检查性约束:检查列是否符合某种规则(性别和薪水)
gender varchar2(2) check (gender in (‘男’,‘女’)),
sal number check (sal>0)
因为主键唯一,所以通过主键查询速度最快(其实是通过索引)
外键约束
子表的外键必须是父表的主键
删除关联表:
方法一:先删除子表,再删除父表
方法二:在父表中将子表的外键那一列置空再删除
方法三:级联删除(危险),一般用级联置空

例子:
create table student(
sid number constraint student_pk primary key,
sname varchar2(20) constraint student_name_notnull not null,
gender varchar2(2) constraint student_gender check (gender in (‘男’,‘女’)),
email varchar2(40) constraint student_email_unique unique
constraint student_email_notnull not null,
deptno number constraint student_fk references dept(deptno) on delete set null
)
 注意:创建约束的时候最好起个名字
注意:创建约束的时候最好起个名字

数据库对象
表\视图\序列\索引\同义词
视图view
 普通用户没有权限,需要管理员授权
普通用户没有权限,需要管理员授权
创建视图:
create view empinfoview
as
select e.empno,e.ename,e.sal,e.sal*12 annsal, d.dname from emp e,dept d
where e.deptno=d.deptno

视图是一个虚表(操作跟表基本一样)
 视图本身不存数据,他是封装了一条复杂查询的语句
视图本身不存数据,他是封装了一条复杂查询的语句
优点:简化复杂的查询
create or replace view empinfoview…(如果存在就替换他)
with read only; (改成只读)
with check option;(检查插入)
删除视图不会影响表,不建议通过视图操作表
序列
可供多个用户用来产生唯一数值的数据库对象
- 自动提供唯一的数值
- 共享对象
- 主要用于提供主键
- 将序列值装入内存可以提高访问效率
相当于mysql中的auto_increment
创建序列:



索引
索引是用于加速数据存储的数据对象.合理的使用索引可以大大降低i/o次数,从而提高数据访问性能
- 单例索引
- 复合索引
SQL的执行计划:
explain plan for



同义词:别名


