漫长旅程中还算不错的开头
在本学期开始之前,我按照助教们所给的寒假作业指导书自学了Java语言的相关知识,了解了Java语言的基本语法,输出一句“Hello World!”,掌握了基本的一些输入输出方法,也学习了一下如何使用正则表达式。比较顺利地完成了寒假作业的三个小程序。但是,做完之后我就一直在回想,我当时写的时候好像一直是在使用类似C语言的方法进行思考。比如,要对输入的字符串进行格式检查了,那就在main函数下面写一个检查格式的函数呗;要对正确的字符串进行处理了,那就在下面写一个处理字符串的函数呗。甚至,我觉得将他们一股脑儿放在main函数中也是不错的选择,直观,便捷。那合着我们这门课只是一门披着Java外衣的C语言课了?当时的我为了解决这些疑问,Google了许多关于面向对象编程的特点,查询了很多其与面向过程编程的不同之处,感觉也只是浅尝辄止,听他们说好像是对的,但是自己叙述就不明就里。
如今,经过了一个月的理论学习+三次课下作业,我对于面向对象编程的思想有了进一步的理解,虽然感觉理解得还不是很到位,但是起码能够感受到与面向过程之间的巨大差别了。下面我将循序渐进陈述我的学习过程,聊一聊我每一阶段的心得体会。
一、三次作业具体代码分析
Homework1
首先贴出UML类图和代码量化分析图。
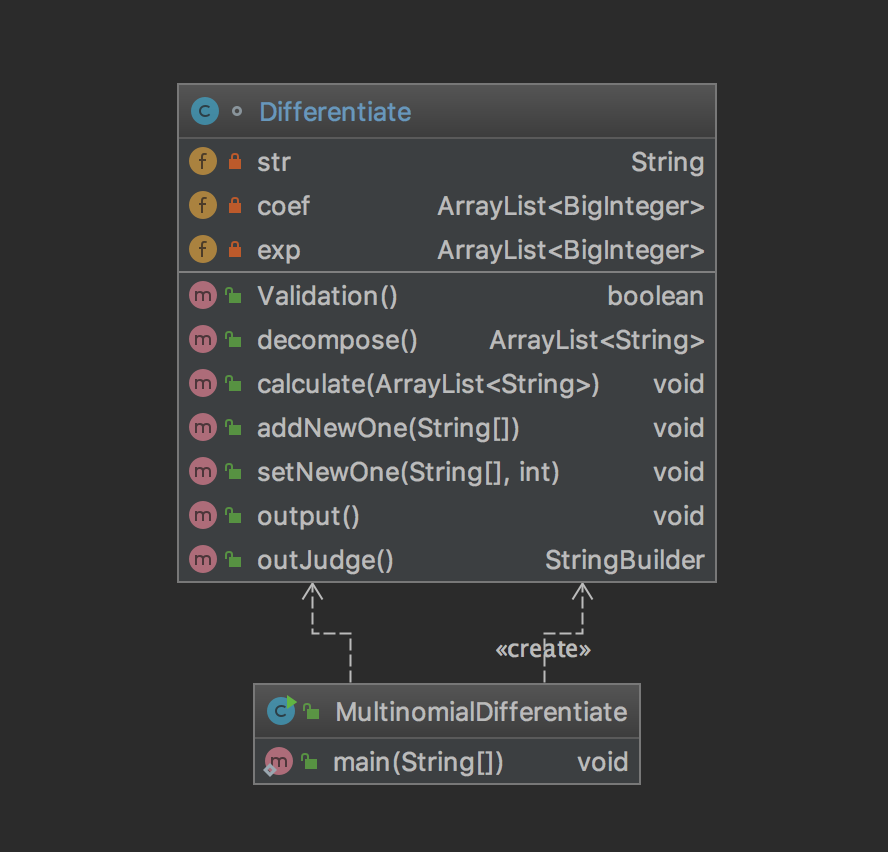
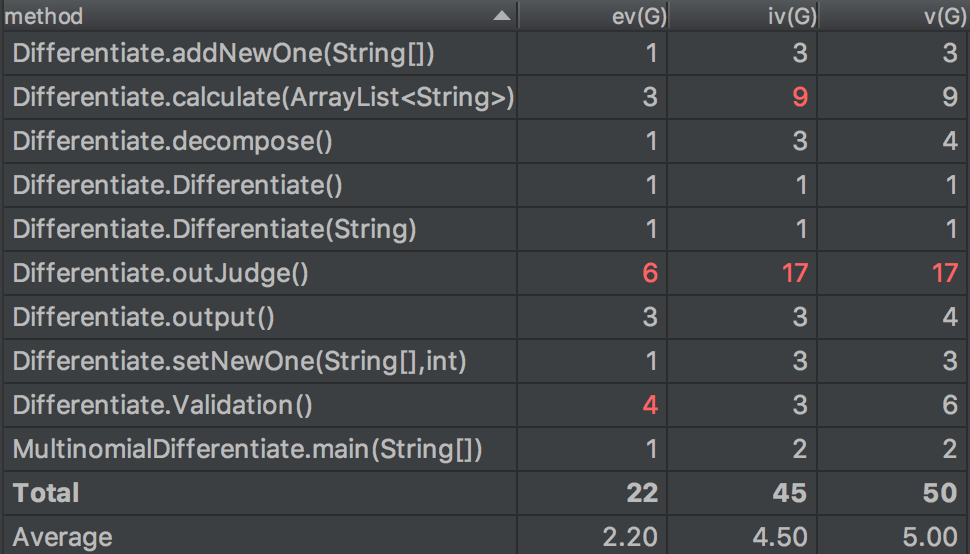
首先让我简单介绍一下代码量化分析图中的三个参数分别代表什么含义。
ev(G)代表的是基本复杂度,主要用来衡量程序的非结构化程度。显然,非结构化程度越高,意味着这一段代码的维护性越差,越松散,给人的阅读体验也越差。
iv(G)代表的是模块设计复杂度,主要用来衡量模块与模块之间的耦合程度。如果一个模块的iv(G)越高 ,那么就意味着它越需要其他的模块,与其他模块的相关程度也越强,维护难度越高,隔离难度也越大。
v(G)代表的是模块结构的复杂度,主要用来衡量模块内部的逻辑究竟有多复杂。一般来说,结构越复杂的模块,带给维护人员和测试人员的工作量也越大,产生错误或者遗漏的可能性也越大。
可以见到,在第一次作业中,我仅仅设置了两个类,MultinomialDifferentiate类(下文称M类)是main函数所在的类,主要行使的功能就是获得输出,然后传递给Differentiate类(下文称D类)进行格式检查以及求导计算。对于一个输入进来的字符串,处理过程大致是这样的:M类获得一行字符串输入,调用D类中的Validation函数,判断格式是否正确;若格式正确,那么调用D类中的decompose函数对字符串进行肢解,从而得到幂函数的系数以及指数,将他们分别存到D类中的coef和exp两个Arraylist中;最后M类调用D类中的calculate函数进行计算,再通过output函数进行输出。outJudge函数是用于化简输出字符串使其为最短形式。在我看来,肢解过程,求导过程和简化输出过程都比较地简单,也没有太多的技巧可言,故在此不再赘述。我想好好介绍一下的是我所使用的格式判断方法。
我身边的不少同学都使用了大正则的方法,虽然这次的合法表达式的的确确可以使用一个正则表达式完全地描述,但是由于正则表达式的特性,会导致如果输入过长则爆栈的现象。所以我使用的方法是先将空格完全清除,然后一小段一小段匹配的方法,简单来说就是如果匹配到正确的一小段,那么就将其替换成空字符串,这样循环下去,如果最终的字符串是一个空串,那么该字符串便合法。当然,我需要在匹配之前进行一些特判,比如全部是空格的情况。同时还需要注意匹配的顺序,应该先匹配开头的幂函数,然后匹配其他的幂函数,最后匹配纯整数,因为不同的顺序会导致误匹配的情况发生,所以应该按照格式复杂度由高到低进行匹配。关键部分代码如下:
1 Pattern error1 = Pattern.compile("\\d[ \\t]+\\d"); 2 Pattern error2 = Pattern.compile("[-+^][ \\t]*[-+][ \\t]+[\\d]"); 3 Pattern error3 = Pattern.compile("([-+][ \\t]*){3,}"); 4 5 if (error1.matcher(str).find() || error2.matcher(str).find() || 6 error3.matcher(str).find()) { 7 return false; 8 } 9 10 if (Pattern.matches("^[ \\t]+$", str)) { 11 return false; 12 } 13 14 String strVal = str; 15 16 strVal = strVal.replaceAll("[ \\t]", ""); 17 18 String start = "^([-+]{0,2}((\\d+\\*)?x(\\^[-+]?\\d+)?|\\d+))"; 19 String end = "[-+]{1,2}(\\d+\\*)?x(\\^[-+]?\\d+)?"; 20 String pureNumber = "[-+]{1,2}\\d+"; 21 22 strVal = strVal.replaceAll(start, ""); 23 strVal = strVal.replaceAll(end, ""); 24 strVal = strVal.replaceAll(pureNumber, ""); 25 26 return strVal.equals("");
由我的代码量化图中可以看到,D类中的outJudge函数三项复杂度都比较高,这主要是D类的output函数直接调用了其的缘故,就像C语言一样。这样的设计显然不够好,调试起来显然也并不容易。
Homework2
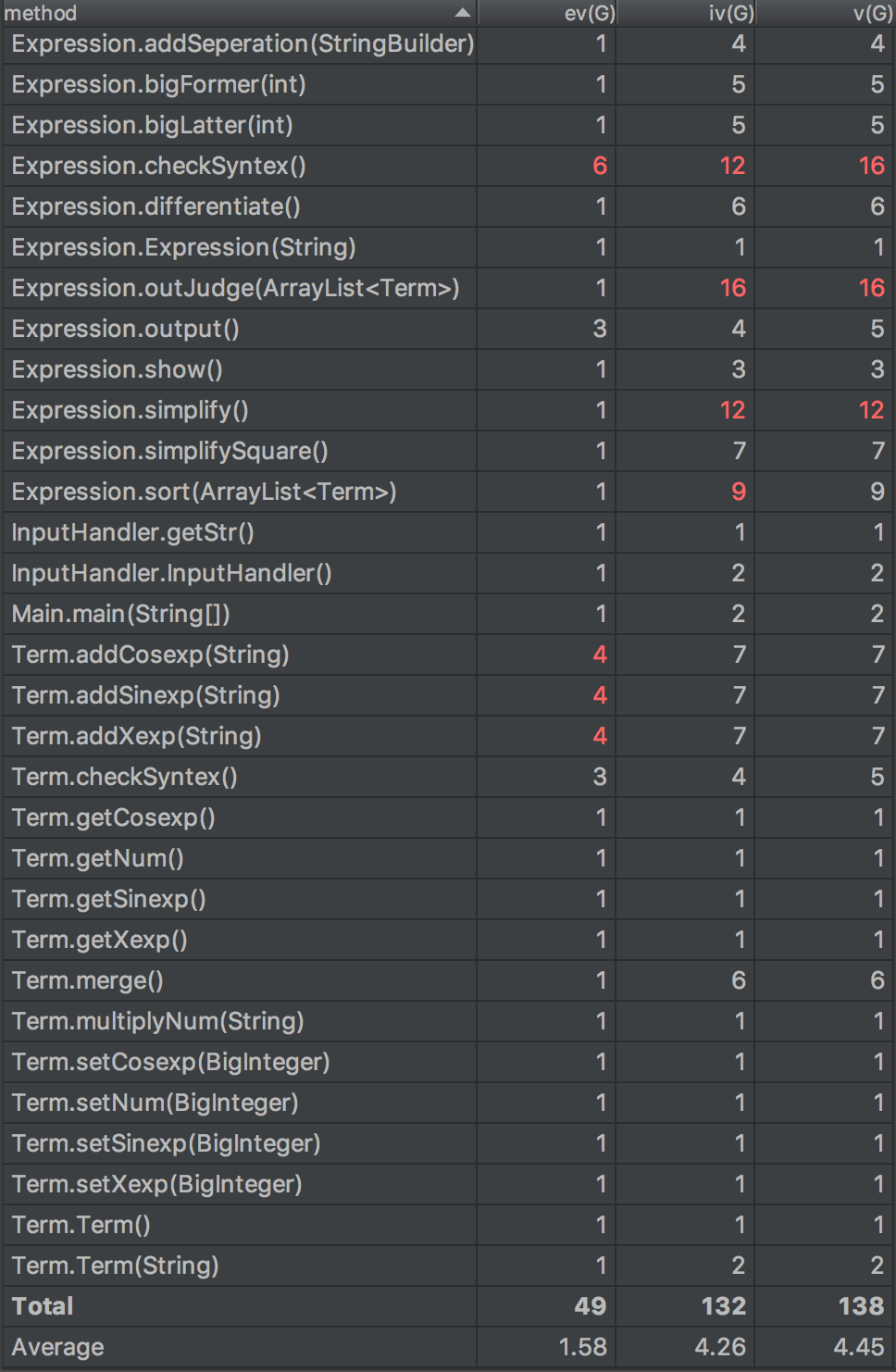
同理,先贴出UML类图和代码量化分析图。
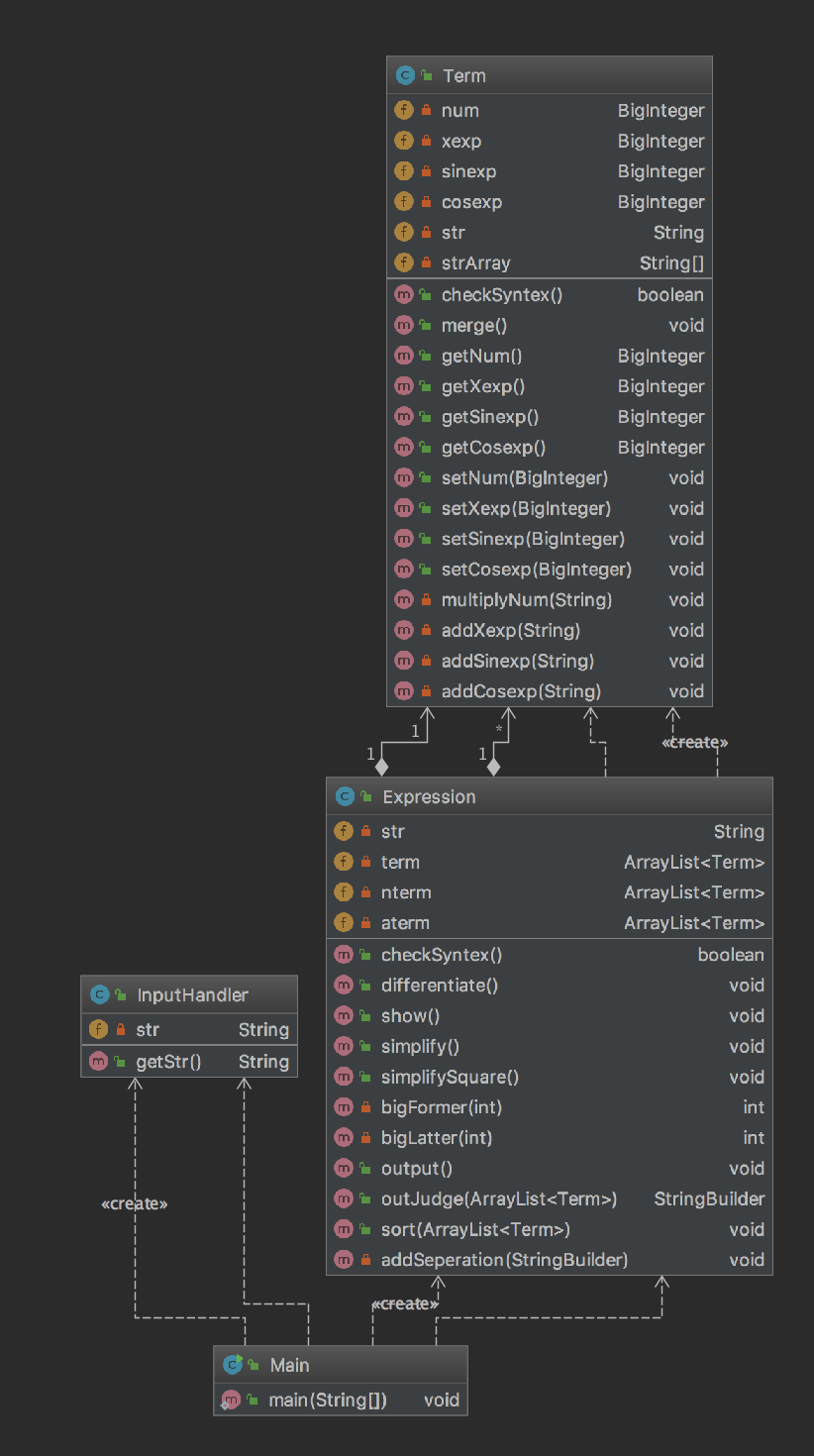
在第二次作业中,输入字符串在第一次作业的基础上加上了三角函数sin和cos的输入,其实从总体架构上来说,复用第一次作业的结构是完全没有问题的。但是可以看到,我在第二次作业中,根据老师的建议加入了InputHandler类(下称I类)的输入处理模块,同时设置了一个Expression类(下称E类)和一个Term类(下称T类)。这个程序的执行程序大致是这样的:先由I类接收输入的字符串并作简单的格式判断,然后由main函数调用E类中的checkSyntex方法,检验在表达式层面可能出现的格式错误,比如空格的错误出现,比如非法字符的出现等等,这一阶段还不涉及项内的格式错误;接着E类会删除空格,根据加减运算符分割出一个一个的项(每一个项中的可能出现的正负号已经被其他字符所替代),然后调用T类中的checkSyntex方法,检验项层面可能出现的格式错误,若无错误,则将其放入一个以Term为元素的Arraylist当中。最后,调用E类中的differentiate方法即可完成求导工作。在互测阶段观摩了其他同学的代码之后,我发现许多人都是在最一开始就使用一个大正则判断整个表达式是否符合格式。这样的判断固然没有错,但是一个需要占据三四行的大正则的可读性极差,并且我觉得也不太符合面向对象的思想。拿我的代码架构举例子,如果我在E类中就将格式审查工作做完,那么相当于T类是一个附属于E类的类,因为T类会默认得到的数据都是格式正确的,但是这显然很不利于模块的隔离与复用,所以在E类和T类中分别判断自己所负责的格式是否有错,那么这两个模块都可以单独拎出来与其他的模块共同工作,显然复用性就更高了。至于第二次作业的优化问题,我只完成了sin(x)^2+cos(x)^2=1的初级化简,所以在此就不献丑了。
由于我的代码结构是层层递进式的,但是每一个模块之间我让他们尽量保持独立性,所以可以看到这一次平均的ev(G),iv(G),v(G)值都下降了,证明代码的质量有了一些进步。但是checkSyntex函数和outJudge函数仍旧做的不够好,因为感觉这两个模块对其他模块的依赖非常地大。
Homework3
同理,贴出UML类图和代码量化分析图。
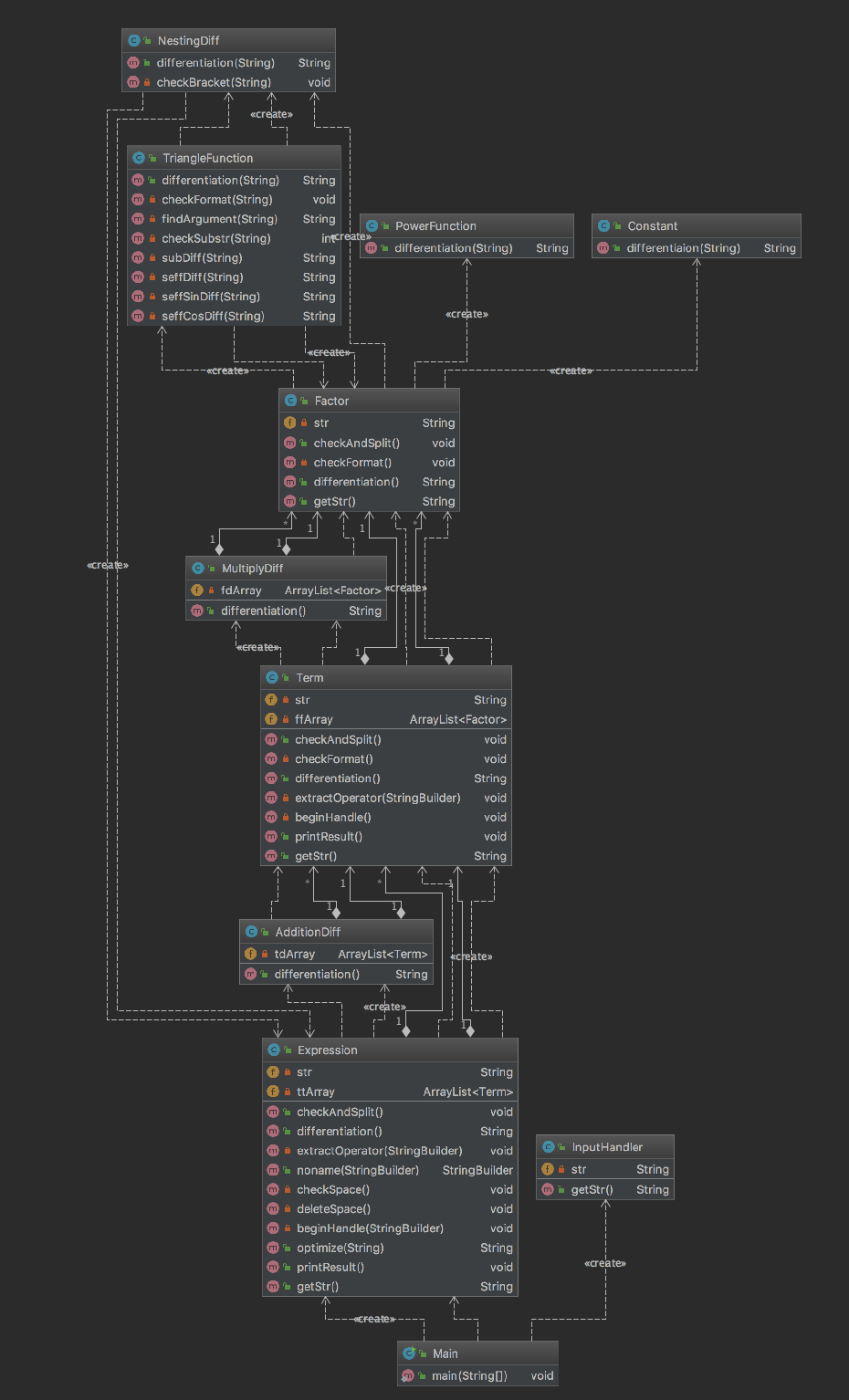

平心而论,第三次作业的难度和第一、第二次作业的难度不可同日而语,起码从架构设计上来不那么简单了。首先观察我的UML类图,可以明显地看到整个架构是一个层层递进的架构,而我使用的也是较为常见的递归下降法。接下来我具体介绍一下整个程序的架构:Main类是main函数所在的类,InputHandler类用于处理控制台的输入,然后与表达式处理相关的有Expression类(下称E类),Term类(下称T类),Factor类(下称F类),TriangleFunction类(下称Tri类),PowerFunction类(下称Pow类),Constant类(下称Con类),AdditionDIff类(下称Ad类),MultiplyDiff类(下称Mu类)和NestingDiff类(下称Ne类)。从逻辑层次上来分,这次输入的字符串可以分为表达式,项和因子三个层次,所以我设计了三个类来分别对应这三个层次。同时,我们仔细探究求导过程,可以发现,最基本的单元都是因子的求导,所以在F类下面,我又设计了三个处理不同类型因子的类,真正的求导是在这三个类里面进行计算的。你可能发现了,在这三个类里面并没有表达式因子的处理方法,那是因为我认为表达式因子并不能够算作真正的最基本的元素,所以我会将表达式因子直接放入嵌套方法中进行计算,但现在想起来,也许多设计一个表达式因子类会使得整个结构更加地完整,易于理解。回到正题,那么每个因子的求导结果是如何联合在一起的呢?我设计了三个运算规则类,即Ad类,Mu类和Ne类。经过我的理解,我认为Ad类其实是专门为E类所服务的,也就是E类将表达式拆分出一个一个地项,然后将这些项传递给Ad类,Ad类再分别调用每个项自身的求导方法(在T类中),将返回的字符串通过加减号拼在一起即可。Mu类的功能类似,调用每一个因子的求导方法,然后将他们返回的结果按照乘法的求导规则拼在一起即可。Ne类比较不一样,我理解为专门处理表达式因子的,即Ne类中会再次创立一个新的E类对象,再经过前述的一连串过程获得最终的结果。可以发现,这样的设计模式使得一种运算规则与一个层次绑定,让结构变得更加地清晰,调试起来也更容易发现问题,定位问题,解决问题。
由于我使用了较多的类(共11个类),所以整个架构清晰了许多,从代码量化数据也可以看出,三项复杂度比上两次作业有了明显的减少,达到了较为理想的水平,我很欣慰我在这过程中一直在进步,收获颇丰。
二、心得体会
首先,最大的体会当然是这门课主要讲授的内容,面向对象编程思想。什么是对象?对象是一个客体,具有特定属性,能够完成特定工作。对象与C语言中的函数有什么区别?二者都能够完成特定的功能,但是对象更加立体,更加符合一般人的思维方式。举个例子,对象是一个具有独立思考能力和独立行动能力的健全人,而C语言中的函数则是一个根据指令完成任务的机械手臂,二者都可以完成他们能力范围内的特定的工作,但是他们能一样吗?对于机械手臂而言,我们需要给予它数据,告诉它它需要完成什么工作,以及一步一步究竟怎么完成都需要预先设定好,这显然是一种流水线的工作方式,能够提高工作效率,但是没有变革工作方式。而对于一个健全人而言,我们需要给予他数据,再告诉他他需要完成的任务,以及最终返回的结果是什么样子的就可以了,至于他是怎么完成的,我们完全不需要关心。更深入地来说,以C语言为代表的面向过程式的语言是按照任务完成的先后顺序来进行结构设计的,而以Java为代表的面向对象式的语言则是以数据的传递路径来进行结构设计的。数据即信息,两个模块之间只需要按照规定传递正确的数据,整个任务就可以正确地完成。这让开发大型工程更加地轻松,要修改某些部分或者添加一些功能不需要改动其他部分,只需要增加一个模块进行数据处理即可。由此看来,大型工程的开发难度下降了,向下兼容性变好了,修改完善变简单了,测试也变得更加舒服了,这就是我对于OOP的一些小小个人体会。
其次,我又一次感受到了“拆分”思想的强大力量,这主要是在第三次作业中获得的。乍一看第三次作业指导书,内容繁复,条条框框很多,各种格式的可能性也非常地多,看起来根本无从下手。但是指导书也是给出了明确的逻辑分层,当我顺着指导书的逻辑往下走,我发现其实质上就是表达式,项和因子三个层次组成的,每一个层次中都有其自身特有的正确格式,每一种能够想到的格式错误也都可以明确地归为三个层次中的一个,由此,我只需要将三个层次的界限划清楚,在每一个层次中按照指导书要求实现对应的格式判断就完全解决了。求导规则的拆分也是一个很优秀的思想,从繁复的求导可能性中提取出了最为本质的规律,然后任何字符串求导都可以轻易地归于这些求导规则,那么我们在实现的时候只需要完成每一个小模块的小功能即可。在设计好之后,不到一天时间,我就完完全全地将整个程序构建完毕并通过了课下测试,不得不感叹“大事化小小事化了”思想的强大力量。
最后,是以测试为导向的设计思想的理解与应用。这一设计思想是第一次研讨课中彭毛小民同学提出的(在此感谢彭毛小民同学的启发),我听完后大受启发。在设计的初期,也就是阅读指导书的阶段,我们就要开始设计自己的测试用例了,这样做有许多的好处。第一,我们在设计测试用例的时候其实是一个加深对于指导书内涵的理解过程,碰到一个模棱两可的例子,我们就会去重新阅读指导书,然后强化对于规则的理解,慢慢地,我们对于指导书的规则便了然于胸,一定程度上避免了设计架构的时候经常忽略指导书的一些要求而造成后期的反复修改;第二,研究测试用例时我们就会不断斟酌我们脑子里那个设计架构,不断地优化它,比如一些方法究竟该放在哪个类中更好,数据的流向如何设置更为合理等等;第三,这样设计出来的测试用例更加地完整,涉及到了方方面面,从简单的错误到复杂的错误全部涵盖,后期进行互测时就可以进行较好的全面覆盖。我在第二第三次作业中都应用了这种设计理念,效果非常地喜人,在写代码阶段更加地流畅,写出来的代码结构更加地清晰,在互测阶段被他人轻易找到bug的几率也大大下降了。
三、不足之处
我最大的遗憾就是第三次作业没有能够找到很好的优化策略,做出满意的优化效果。由于分数导向问题,我把更多的时间放在了如何使架构更加合理,减少bug出现的可能性上,而对于优化输出所做的工作确实不够多。也许是我的架构不够合理,所以优化的难度会很大,这也不得而知。只希望在第二单元的作业中我能够让我的程序真正变成对用户友好的产品,让用的人不至于这么的难受。
其次就是代码复用性过低的问题。虽说三次作业下来,我的代码模块性更好了,但是三次作业我重构了三次,究其原因还是前两次作业的设计不够成熟,可拓展性太差了,同时每个模块之间的耦合度太高,所以难以复用。希望在第二单元的作业中我能够从第一次作业开始就将可扩展性放在一个比较重要的位置上。