
用UIBot的元素获取功能,很轻松就能从网页上扒到你想要的内容。这里就以小说网站笔趣阁为例,教大家怎么扒小说
1、首先用Chrome打开笔趣阁的小说,(这里随便打开的一本小说,没有任何广告嫌疑,手动狗头)

2、我们先用获取元素文本功能,获取小说的章节标题

点击查找目标之后,把鼠标移动到浏览器小说标题的位置,获取标题元素,把获取到的文本存入变量sTitle中备用~

3、接下来我们再来获取下小说的内容,和获取标题一样使用获取元素文本功能,把小说的内容存入变量sBody中


4、我们再新建一个变量,把刚才获取到的标题还有内容组合一下

一般我们会把标题和内容之间用换行来隔开。
5、处理好标题和内容的连接后,我们把内容写入到一个文本里,并且是用追加写入,这样可以保证每次的写入不会覆盖掉上一次的内容。
这里使用到的命令是追加写入文件

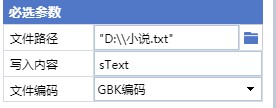
6、最后,最重要的一步来了,前面我们只是获取到当前这一章的内容,我们想要获取整本小说,拿就得用循环命令,再配合上点击下一章的操作,这样就能实现循环的把每一章内容都提取出来,最终就能把整本小说都扒下来了。
先使用鼠标点击命令,获取到【下一章】按钮的元素

然后我们把刚才整个过程使用循环来包起来,这样就能实现整个提取小说的过程了
