简介
在flink原理解析中https://blog.csdn.net/aA518189/article/details/82908993,我们把flink的概念以及原理整体介绍了一遍,接下来这篇文章会具体的解析每个原理的具体实现和使用方式。
流对齐(align)
首先谈到流对齐,那一定是多流处理。那对齐的是什么呢?其实对齐的是检查点中的Barrier。我们来看一下一个flink任务生成检查点的整体流程:
- barrier 由source节点发出;
- barrier会将流上event切分到不同的checkpoint中;
- 汇聚到当前节点的多流的barrier要对齐;
- barrier对齐之后会进行Checkpointing,生成snapshot;
- 完成snapshot之后向下游发出barrier,继续直到Sink节点
Barrier随着正常数据继续往下流动,当一个operator从其所有的输入流都接收到snapshot n的Barrier时,它会向其所有输出流插入一个标识(也叫snapshot n)的Barrier。当sink operator(即DAG流的终点)从其输入流接收到所有的Barrier n时,表示这一批数据处理完成,它会向checkpoint coordinator发送消息确认snapshot n已完成。当所有sink都确认了这个snapshot,则标识本次处理已成功,该snapshot被标识为已完成。
在上诉处理流程中,operator上游会接收很多流,每个流的快慢又不一致,但是每一个流中都有Barrier,多流结合在一起时,必须Barrier的序号要一样,如何保证每个snapshot都都能放在一起被输出呢?这就靠operator的“对齐(align)”功能。
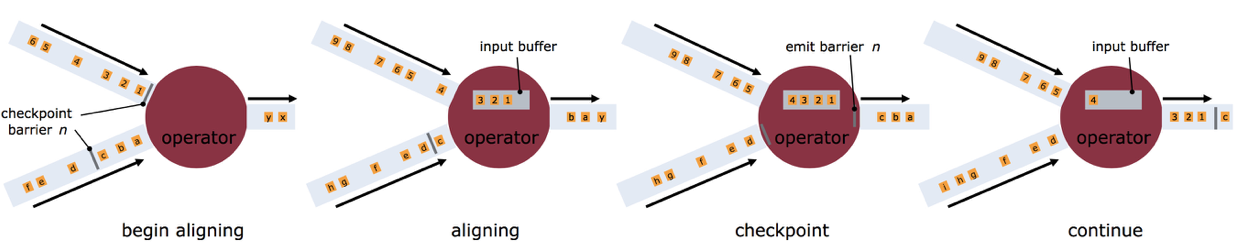
上图解释了“align”的过程,个人理解:核心思想就是“快流等慢流”,"也就是同样序号的Barrier,不同流到节点的时间不一样,但是快的那个Barrier要等慢的那个Barrier,然后“两个人”见面了 哦 我们的序号一样,此时对齐结束"。拿barrier n来说,上面的流到的早,此后operator就暂时不会继续处理后续的数据了(否则会导致snapshot n和snapshot n+1的数据混在一起了),而是会用“input buffer”把它对应的数据先保存起来,等下面流的barrier n也到来时,operator就把内部的所有数据都向下发出去,并对下游也插入一个barrier n来标识本次对齐完成。
检查点两种模式的区别
检查点两种模式如下:
- At-Least-Once - 语义是流上所有数据至少被处理过一次(不要丢数据)
- Exactly-Once - 语义是流上所有数据必须被处理且只能处理一次(不丢数据,且不能重复)
从语义上面Exactly-Once 比 At-Least-Once对数据处理的要求更严格,更精准,那么更高的要求就意味着更高的代价,这里的代价就是 延迟,接下来会介绍为什么Exactly-Once延迟更高。
区别
Apache Flink中At-Least-Once 和 Exactly-Once有什么区别呢?区别体现在多路输入的时候(比如 Join),也就是说单流处理这两种模式是没有区别的。当所有输入的barrier没有完全到来的时候,早到来的event在Exactly-Once模式下会进行缓存(不进行处理),而在At-Least-Once模式下即使所有输入的barrier没有完全到来,早到来的event也会进行处理。也就是说对于At-Least-Once模式下,对于下游节点而言,本来数据属于checkpoint N 的数据在checkpoint N-1 里面也可能处理过了。
我以Exactly-Once为例说明Exactly-Once模式相对于At-Least-Once模式为啥会有更高的延时?如下图:
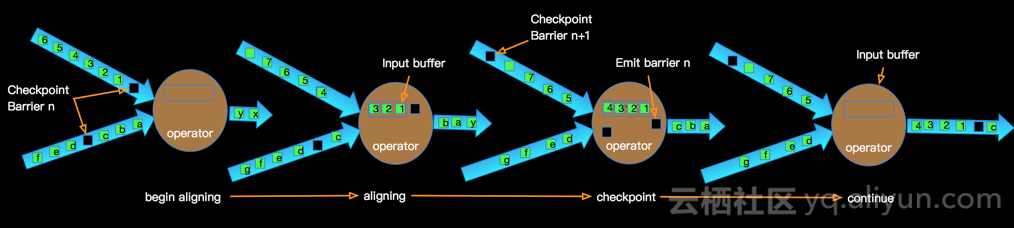
上图示意了某个节点进行Checkpointing的过程:
- 当Operator接收到某个上游发下来的第barrier时候开始进行barrier的对齐阶段;
- 在进行对齐期间早到的input的数据会被缓存到buffer中;
- 当Operator接收到上游所有barrier的时候,当前Operator会进行Checkpointing,生成snapshot并持久化;
- 当完Checkpointing时候将barrier广播给下游Operator;
多路输入的barrier没有对齐的时候,barrier先到的输入数据会缓存在buffer中,不进行处理,这样对于下游而言buffer的数据越多就有更大的延迟。这个延时带来的好处就是相邻Checkpointing所记录的数据(计算结果或event)没有重复。相对At-Least-Once模式数据不会被buffer,减少延时的利好是以容忍数据重复计算为代价的。
多流的水印处理
在实际的流计算中往往一个工作中会处理多个Source的数据,对Source的数据进行GroupBy分组,那么来自不同Source的相同值 会shuffle到同一个处理节点,并携带各自的Watermark,Apache Flink内部要保证Watermark要保持单调递增,多个Source的Watermark汇聚到一起时候可能不是单调自增的,这样的情况Apache Flink内部是如何处理的呢?如下图所示:
 Apache Flink内部实现每一个边上只能有一个递增的Watermark,当出现多流携带Eventtime汇聚到一起(GroupBy或Union)时候,Apache Flink会选择所有流入的Eventtime中最小的一个向下游流出。从而保证水印的单调递增和保证数据的完整性如下图:
Apache Flink内部实现每一个边上只能有一个递增的Watermark,当出现多流携带Eventtime汇聚到一起(GroupBy或Union)时候,Apache Flink会选择所有流入的Eventtime中最小的一个向下游流出。从而保证水印的单调递增和保证数据的完整性如下图:

水印的产生方式
目前Apache Flink有两种生产Watermark的方式,如下:
- Punctuated - 数据流中每一个递增的EventTime都会产生一个Watermark。
在实际的生产中,在TPS很高的场景下会产生大量的Watermark在一定程度上对下游算子造成压力,所以只有在实时性要求非常高的场景才会选择间断的方式进行水印的生成。 - Periodic - 周期性的(一定时间间隔或者达到一定的记录条数)产生一个Watermark。在实际的生产中定期的方式必须结合时间和积累条数两个维度继续周期性产生Watermark,否则在极端情况下会有很大的延时。
所以水印的生成方式需要根据业务场景的不同进行不同的选择。
水印的接口定义
对应Apache Flink Watermark两种不同的生成方式,我们了解一下对应的接口定义,如下:
- 定期水印 - AssignerWithPeriodicWatermarks
- 标点符号 - AssignerWithPunctuatedWatermarks
AssignerWithPunctuatedWatermarks继承了TimestampAssigner接口-TimestampAssigner - 从接口定义可以看出,水印可以在事件(元件)中提取EVENTTIME,进而定义一定的计算逻辑产生水印的时间戳。
ParameterTool
ParameterTool是flink提供的一个用于解析命令参数的工具,传统的起一个flink任务我们都是解析args数组中的数据,获取参数,但是当参数很多的时候有点繁琐,flink为此提供一个一个便捷的参数解析工具。
使用方式
ParameterTool提供了一系列预定义的静态方法来读取配置信息,ParameterTool内部是一个Map<String, String>,所以很容易与你自己的配置形式相集成。参数可以来自配置文件,args数组。主要介绍如何解析args数组中的参数。
public static ParameterTool fromArgs(String [] args)ParameterTool给定参数的返回值。参数是键后跟值。键必须以' - '或' - '开头
示例参数: - key1 value1 --key2 value2 -key3 value3
使用案例
在flink代码中获取ParameterTool对象
//解析args 获取参数
final ParameterTool params = ParameterTool.fromArgs(args);命令指定参数:注意 参数的key必须以"-"开头
flink run -c StuScore StuScore.jar --topic log_test ........获取参数:通过指定key获取参数,比如获取topic 创建kafka实例对象
FlinkKafkaConsumer010<String> kafkaConsumer010 = new FlinkKafkaConsumer010<>(params.get("topic"), new SimpleStringSchema(), properties);flink窗口使用大全
自定义触发器 trigger
为啥需要trigger?基于事件时间处理机制,数据会在有些意想不到的情况下滞后,比如forward故障,网络故障等,这种情况,对于flink来说我们可以设置一些参数来允许处理滞后的元素,比如允许其滞后一小时,那么这个时候实际上窗口输出间隔就是要加上这个滞后时间了,这时候假如我们想要尽可能的实时输出的话,就要用到flink的trigger机制。flink有很多内置的触发器,对于基于事件时间的窗口触发器叫做EventTimeTrigger。其实,我们要实现基于事件时间的窗口随意输出,比如1000个元素触发一次输出,那么我们就可以通过修改这个触发器来实现。
trigger使用方式
Trigger定义了何时开始使用窗口计算函数计算窗口。每个窗口分配器都会有一个默认的Trigger。如果,默认的Trigger不能满足你的需求,你可以指定一个自定义的trigger().
trigger接口有五个方法允许trigger对不同的事件做出反应:
onElement():进入窗口的每个元素都会调用该方法。
onEventTime():事件时间timer触发的时候被调用。
onProcessingTime():处理时间timer触发的时候会被调用。
onMerge():有状态的触发器相关,并在它们相应的窗口合并时合并两个触发器的状态,例如使用会话窗口。
clear():该方法主要是执行窗口的删除操作。关于上述方法需要注意两点:
1).前三方法决定着如何通过返回一个TriggerResult来操作输入事件。
-
CONTINUE:什么都不做。
-
FIRE:触发计算。
-
PURE:清除窗口的元素。
-
FIRE_AND_PURE:触发计算和清除窗口元素。
2).这些方法中的任何一个都可用于为将来的操作注册处理或事件时间计时器
内置和自定义触发器 Flink内部有一些内置的触发器:
EventTimeTrigger:基于事件时间和watermark机制来对窗口进行触发计算。
ProcessingTimeTrigger:基于处理时间触发。
CountTrigger:窗口元素数超过预先给定的限制值的话会触发计算。
PurgingTrigger作为其它trigger的参数,将其转化为一个purging触发器。WindowAssigner的默认触发器适用于很多案例。比如,所有基于事件时间的窗口分配器都用EventTimeTrigger作为默认触发器。该触发器会在watermark达到窗口的截止时间时直接触发计算输出。
自定义触发器案例
修改自基于处理时间的触发器,源码如下:
public class CustomProcessingTimeTrigger extends Trigger<Object, TimeWindow> {
private static final long serialVersionUID = 1L;
private CustomProcessingTimeTrigger() {}
private static int flag = 0;
@Override
public TriggerResult onElement(Object element, long timestamp, TimeWindow window, TriggerContext ctx) {
ctx.registerProcessingTimeTimer(window.maxTimestamp());
// CONTINUE是代表不做输出,也即是,此时我们想要实现比如100条输出一次,
// 而不是窗口结束再输出就可以在这里实现。
if(flag > 9){
flag = 0;
return TriggerResult.FIRE;
}else{
flag++;
}
System.out.println("onElement : "+element);
return TriggerResult.CONTINUE;
}
@Override
public TriggerResult onEventTime(long time, TimeWindow window, TriggerContext ctx) throws Exception {
return TriggerResult.CONTINUE;
}
@Override
public TriggerResult onProcessingTime(long time, TimeWindow window, TriggerContext ctx) {
return TriggerResult.FIRE;
}
@Override
public void clear(TimeWindow window, TriggerContext ctx) throws Exception {
ctx.deleteProcessingTimeTimer(window.maxTimestamp());
}
@Override
public boolean canMerge() {
return true;
}
@Override
public void onMerge(TimeWindow window,
OnMergeContext ctx) {
// only register a timer if the time is not yet past the end of the merged window
// this is in line with the logic in onElement(). If the time is past the end of
// the window onElement() will fire and setting a timer here would fire the window twice.
long windowMaxTimestamp = window.maxTimestamp();
if (windowMaxTimestamp > ctx.getCurrentProcessingTime()) {
ctx.registerProcessingTimeTimer(windowMaxTimestamp);
}
}
@Override
public String toString() {
return "ProcessingTimeTrigger()";
}
/**
* Creates a new trigger that fires once system time passes the end of the window.
*/
public static CustomProcessingTimeTrigger create() {
return new CustomProcessingTimeTrigger();
}
}
主要实现逻辑是在onElement函数,实现的逻辑是增加了每10个元素触发一次计算结果输出的逻辑。
trigger 测试
滚动窗口,20s ,然后是trigger内部技术,10个元素输出一次。
public class kafkaSourceTriggerTest {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "localhost:9093");
properties.setProperty("group.id", "test");
FlinkKafkaConsumer010<String> kafkaConsumer010 = new FlinkKafkaConsumer010<>("test",
new SimpleStringSchema(),
properties);
AllWindowedStream<Integer, TimeWindow> stream = env
.addSource(kafkaConsumer010)
.map(new String2Integer())
.timeWindowAll(org.apache.flink.streaming.api.windowing.time.Time.seconds(20))
.trigger(CustomProcessingTimeTrigger.create());
stream.sum(0)
.print()
;
env.execute("Flink Streaming Java API Skeleton");
}
private static class String2Integer extends RichMapFunction<String, Integer> {
private static final long serialVersionUID = 1180234853172462378L;
@Override
public Integer map(String event) throws Exception {
return Integer.valueOf(event);
}
@Override
public void open(Configuration parameters) throws Exception {
}
}
}
背压(backpressure)监控
Flink的web接口提供了监控运行job的背压行为的功能
一、背压(back pressure)
如果你看到了一个任务的back pressure警告(如过高),则意味着该任务产生数据的速度要高于下游Operator消化的速度。数据沿着job的数据流图向下游流动(如从source到sink),而背压则是沿着相反的方向传播,逆流而上。 以一个简单的Source -> Sink的job为例,如果看到了一个关于Source的警告,则意味着Sink消化数据的速度慢于Source产生数据的速度,而Sink向上游的Source产生背压。
二、取样线程(Sampling Threads)
背压的监控工作原理是从运行的任务重复地对堆栈轨迹(stack trace)取样。JobManager对运行Job的各任务重复触发Thread.getStackTrace()的调用。
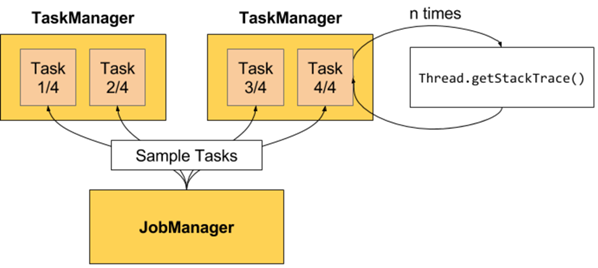
图1 取样线程
如果取样显示一个任务线程卡在某个内部方法调用中(从网络栈中请求缓存空间),则意味着该任务面临着背压的影响。
默认地,对于每一个任务,JobManager会每隔50ms触发100次堆栈轨迹。我们在web接口中看到的比例说明了这些堆栈轨迹中有多少卡在了内部方法调用中,如0.01就表示100个堆栈轨迹中有一个卡在了方法调用中。背压的状态如下区分:
1. OK:0 <= Ratio <= 0.10
2. LOW:0.10 < Ratio <= 0.5
3. HIGH:0.50 < Ratio <= 1.0
为了使堆栈轨迹取样不对Task Manager产生太大负荷,web接口仅每60s才刷新一次样本。
三、配置
我们可以用如下配置关键字来设置Job Manager的样本数量:
1. jobmanager.web.backpressure.refresh-interval:已有样本过期并需要刷新时间间隔(默认:60000,1min)
2. jobmanager.web.backpressure.num-samples:确定背压所需取样的堆栈轨迹数量(默认:100)
3. jobmanager.web.backpressure.delay-between-samples:确定背压取样的时间区间(默认:50,50ms)
四、示例
web接口中,我们可以在"Job overview"旁边看到"Back pressure"选项卡
4.1 Sampling in progress
该状态意味着JobManager出发了一个运行中的任务的堆栈轨迹取样,默认配置下,该操作需要约5秒。
在此界面,我们点击某行,则会触发对该Operator的所有子任务的取样操作。
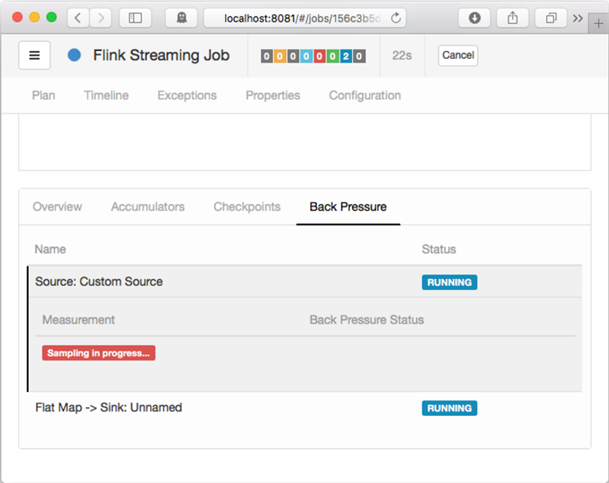
图2 Sampling in progress
4.2 背压状态
如果我们看到某任务的状态是OK,则表示没有背压的迹象。反之,HIGH则表示该任务正受到背压的影响。

图3-1 背压状态OK
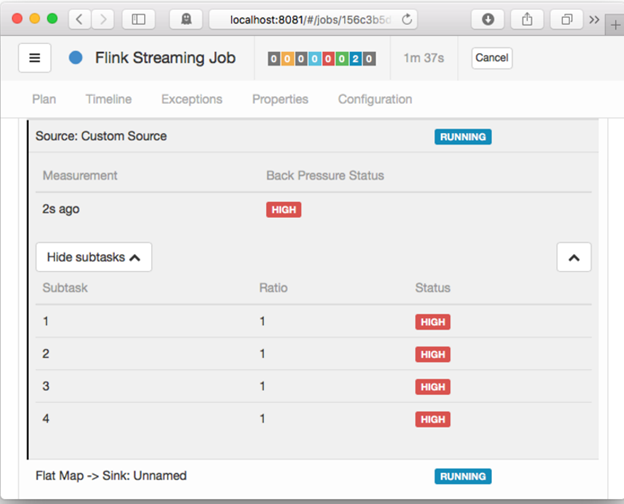
图3-2 背压状态HIGH
flink 常见问题
1.Savepoints相关问题解决方案
1. 如果用户在升级作业时新添加一个有状态的算子有什么影响?
当用户在作业中新添加一个有状态的算子时,由于该算子是新添加的,无保存的旧状态,因此无状态恢复,从0开始运行。
2. 如果用户在升级作业时从作业中删除一个有状态的算子有什么影响?
默认情况下,savepoint会尝试将所有保存的状态恢复。如果用户使用的savepoint中包含已经删除算子的状态,恢复将会失败。用户可以通过--allowNonRestoredState(简写为-n)参数跳过恢复已经删除的算子的状态:
$ bin/flink run -s savepointPath -n [runArgs]
3. 如果用户重新编排有状态的算子的顺序有什么影响?
如果用户已经给这些算子分配IDs,那么这些状态会正常恢复。
如果用户没有给这些算子分配IDs, 这些算子将会按新的顺序自动分配新的ID,这将导致状态恢复失败。
4. 如果用户在作业中删除或添加或更改无状态算子的顺序有什么影响?
如果用户已经给有状态的算子分配ID,那么无状态的算子并不会影响从savepoint进行状态恢复。
如果用户没有分配IDs,有状态算子的IDs由于顺序变化可能会被分配新的IDs,这将导致状态恢复失败。
5. 如果用户在状态恢复时改变了算子的并发度会有什么影响?
如果Flink版本高于1.2.0且不使用已经废弃的状态API,如checkpointed,用户可以从savepoint中进行状态恢复。否则,无法恢复。
2.如何处理checkpoint设置RocksDBStateBackend方式,且当数据量大时,执行checkpoint会很慢的问题
问题
如何处理checkpoint设置RocksDBStateBackend方式,且当数据量大时,执行checkpoint会很慢的问题?
原因分析
由于窗口使用自定义窗口,这时窗口的状态使用ListState,且同一个key值下,value的值非常多,每次新的value值到来都要使用RocksDB的merge()操作;触发计算时需要将该key值下所有的value值读出。
RocksDB的方式为merge()->merge()....->merge()->read(),该方式读取数据时非常耗时,如图1所示。
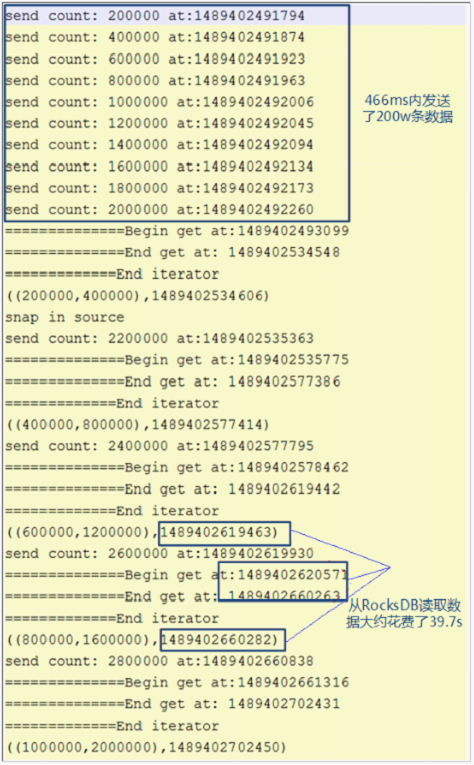
source算子在瞬间发送了大量数据,所有数据的key值均相等,导致window算子处理速度过慢,使barrier在缓存中积压,快照的制作时间过长,导致window算子在规定时间内没有向CheckpointCoordinator报告快照制作完成,CheckpointCoordinator认为快照制作失败,如图2所示。
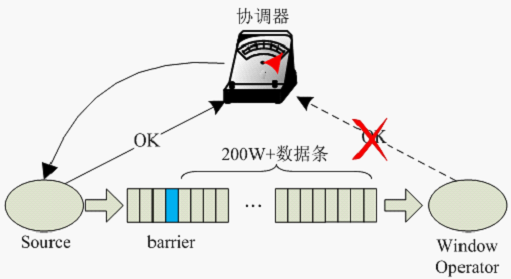
回答
Flink引入了第三方软件包RocksDB的缺陷问题导致该现象的发生。建议用户将checkpoint设置为FsStateBackend方式。
用户需要在应用代码中将checkpoint设置为FsStateBackend。例如:
env.setStateBackend(new FsStateBackend("hdfs://hacluster/flink-checkpoint/checkpoint/"));
4.如何处理blob.storage.directory配置/home目录时,启动yarn-session失败的问题
当用户设置“blob.storage.directory”为“/home”时,用户没有权限在“/home”下创建“blobStore-UUID”的文件,导致yarn-session启动失败。
1. 建议将"blob.storage.directory"配置选项设置成“/tmp”或者“/opt/huawei/Bigdata/tmp”。
2. 当用户将"blob.storage.directory"配置选项设置成自定义目录时,需要手动赋予用户该目录的owner权限。以下以FusionInsight的admin用户为例。
A. 修改Flink客户端配置文件conf/flink-conf.yaml,配置blob.storage.directory: /home/testdir/testdirdir/xxx。
B. 创建目录/home/testdir(创建一层目录即可),设置该目录为admin用户所属。
![]()
说明:
/home/testdir/下的testdirdir/xxx目录在启动Flink集群时会在每个节点下自动创建。
C. 进入客户端路径,执行命令
./bin/yarn-session.sh -n 3 -jm 2048 -tm 3072,可以看到yarn-session正常启动并且成功创建目录。

5.为什么Flink Web页面无法直接连接
问题
无法通过“http://JobManager IP:JobManager的端口”访问Web页面。
回答
由于浏览器所在的计算机IP地址未加到Web访问白名单导致。用户可以通过以下步骤来解决问题。
1. 查看客户端的配置文件“conf/flink-conf.yaml”。
2. 确认配置项“jobmanager.web.ssl.enabled”的值是“false”。
– 如果不是,请修改配置项的值为“false”。
– 如果是,请执行3。
3. 确认配置项“jobmanager.web.access-control-allow-origin”和“jobmanager.web.allow-access-address”
中是否已经添加浏览器所在的计算机IP地址。如果没有添加,可以通过这两项配置项进行添加。例如:
jobmanager.web.access-control-allow-origin: 192.168.252.35,192.168.24.216
jobmanager.web.allow-access-address: 192.168.252.35,192.168.24.216
持续更新。。。。。。。
扫一扫加入大数据技术交流群,了解更多大数据技术,还有免费资料等你哦
扫一扫加入大数据技术交流群,了解更多大数据技术,还有免费资料等你哦
扫一扫加入大数据技术交流群,了解更多大数据技术,还有免费资料等你哦
