之前排查智能合约执行返回0x的问题,涉及到数据库部分的内容,就把leveldb的3个主要操作介绍一下。
在此之间先介绍下leveldb中的文件类型。
文件类型
文件类型总共有5种:log, ldb, CURRENT, MANIFEST,LOG。 另外还有一部分内存缓存。
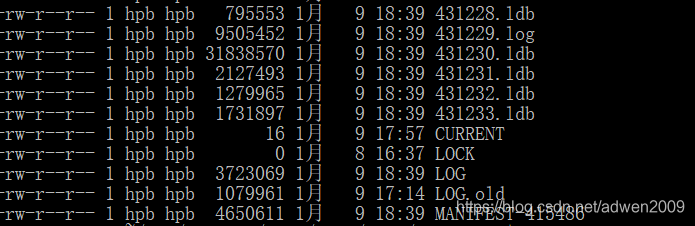
内存缓存:memtable。默认是32M大小。memtable写满之后会转为frozenmemtable,用于写入数据库
log文件:所有的put操作,数据都是先写入log文件,然后才写入内存memtable。作用是用于恢复数据,避免数据丢失。
ldb文件:kv数据库文件。每一个数据库中kv都是有序存储的。
L0层的ldb文件可能存在key范围重叠的情况。
L1~~Lk层的ldb文件不存在key范围重叠的情况
CURRENT文件:记录当前使用的MANIFEST文件名。
MANIFEST文件:记录ldb文件对应的最小和最大key。
LOG文件:日志,记录表合并的日志。
LOCK文件:锁文件。每次以写模式打开LOG文件时,先以只读模式打开LOCK文件直到LOG文件关闭
put操作
put操作实际上不涉及到磁盘操作,只是将数据追加到log文件中,然后写入memtable。如果memtable中数据没能及时写入到磁盘中,则通过log文件进行恢复。
get操作
get操作的简单流程如下:
1、查询memtable,找到就返回
2、查询frozenmemtable,找到就返回
3、遍历L0层的所有table的索引 ,找到就转第5步,找不到转第4步 。(L0层表的minkey,maxkey 可能存在重叠,此处的遍历实际上是先查新表,再查旧表。)
4、遍历L1+N层的所有table的索引,找到就转第5步,找不到结束。(根据每个table的最小和最大key进行比较,因为是有序的,所以每个文件都只需要比较minkey和maxkey即可确定目标key在那个文件中)
5、查询找到的表的缓存数据,查到就返回,查不到就转第6步
6、打开表,遍历表数据进行比较,找到就返回正确结果,找不到就返回错误。
compaction过程
compaction操作分为两种,一种是memcompaction,一种是tablecompaction
a、memcompaction
目标是将frozenmemtable写入到L0中,
触发条件:memtable写满了,就需要将memtable转为frozenmemtable,然后创建新的memtable。
流程如下
1、获取frozenmemtable。
2、如果len(frozenmemtable) ==0 ,直接结束。否则,继续第3步
3、停止tableComPaction。(memcompaction 和 tablecompaction不同时进行)
4、创建新的table,将frozenMemDb中的数据写入新的table中,如果失败了就删除新建的表并结束。
5、将新的table信息写入MANIFEST文件。
6、删除frozenMemDb,恢复tablecompaction。
b、tablecompaction
目标是合并Lk层的表到Lk+1层,k>=0。
触发合并条件有2个:1,某一层的数据大小满了,2、某一层数据没有命中,需要到下一层查询,就需要将没有命中的表合并到下一层去。
1、根据以上两个条件,获取需要合并的表tables,包括了Lk---->Lk+1层的表。k+1层的表可能是多个,因为可能存在k层的表中的key与k+1层的多个表范围重叠。
2、将数据从tables表中读出来,写入到新的newtable中
3、新的newtable写满后,会在创建新的表,然后继续写入。
4、将旧的表及旧表相关的内存信息删除
5、合并完毕。
表comaction的好处
1、减少存储空间。删除无效的key,以及合并相同的key或者相同前缀的key。
2、提高查询效率。合并后数据都是有序的,因此查询效率高。
思考
从之前排查的智能合约的例子看,tablecompaction的操作是比较耗时的,而且随着数据量越来越大,耗时就越来越多。从区块链的角度看,这无疑会成为一个性能瓶颈。
从应用层角度看,智能合约的编写更应该注重效率,减少数据库的读写次数。
从数据库角度看,只要进行tablecompaction操作,表就有被合并的可能。如果考虑单独增加常用缓存的话,也要考虑缓存的更新和删除问题,这是个值得思考的问题。再想想。。。。。。