面试题1. 按值传递和按引用传递的区别?
- 如果传递的参数是八大基本类型的话,是值传递。如果参数传递的是对象实例、数组或者是接口的话,还是按值传递的,千万不要被外表所迷惑
- 也就是说,如果当你传递的是对象作为参数的话,首先参数会先进行拷贝一份引用执行原本的实例对象,但是一旦这个调用这个方法的结束之后,那么这个拷贝过来的实例对象的引用就会被肖销毁。
- https://blog.csdn.net/u013309870/article/details/75499175
- https://blog.csdn.net/javazejian/article/details/51192130
看下面一个例子仔细思考一下吧
public class CallByValue {
private static User user=null;
private static User stu=null;
/**
* 交换两个对象
* @param x
* @param y
*/
public static void swap(User x,User y){
User temp =x;
x=y;
y=temp;
}
public static void main(String[] args) {
user = new User("user",26);
stu = new User("stu",18);
System.out.println("调用前user的值:"+user.toString());
System.out.println("调用前stu的值:"+stu.toString());
swap(user,stu);
System.out.println("调用后user的值:"+user.toString());
System.out.println("调用后stu的值:"+stu.toString());
}
输出结果:
调用前user的值:User [name=user, age=26]
调用前stu的值:User [name=stu, age=18]
调用后user的值:User [name=user, age=26]
调用后stu的值:User [name=stu, age=18]
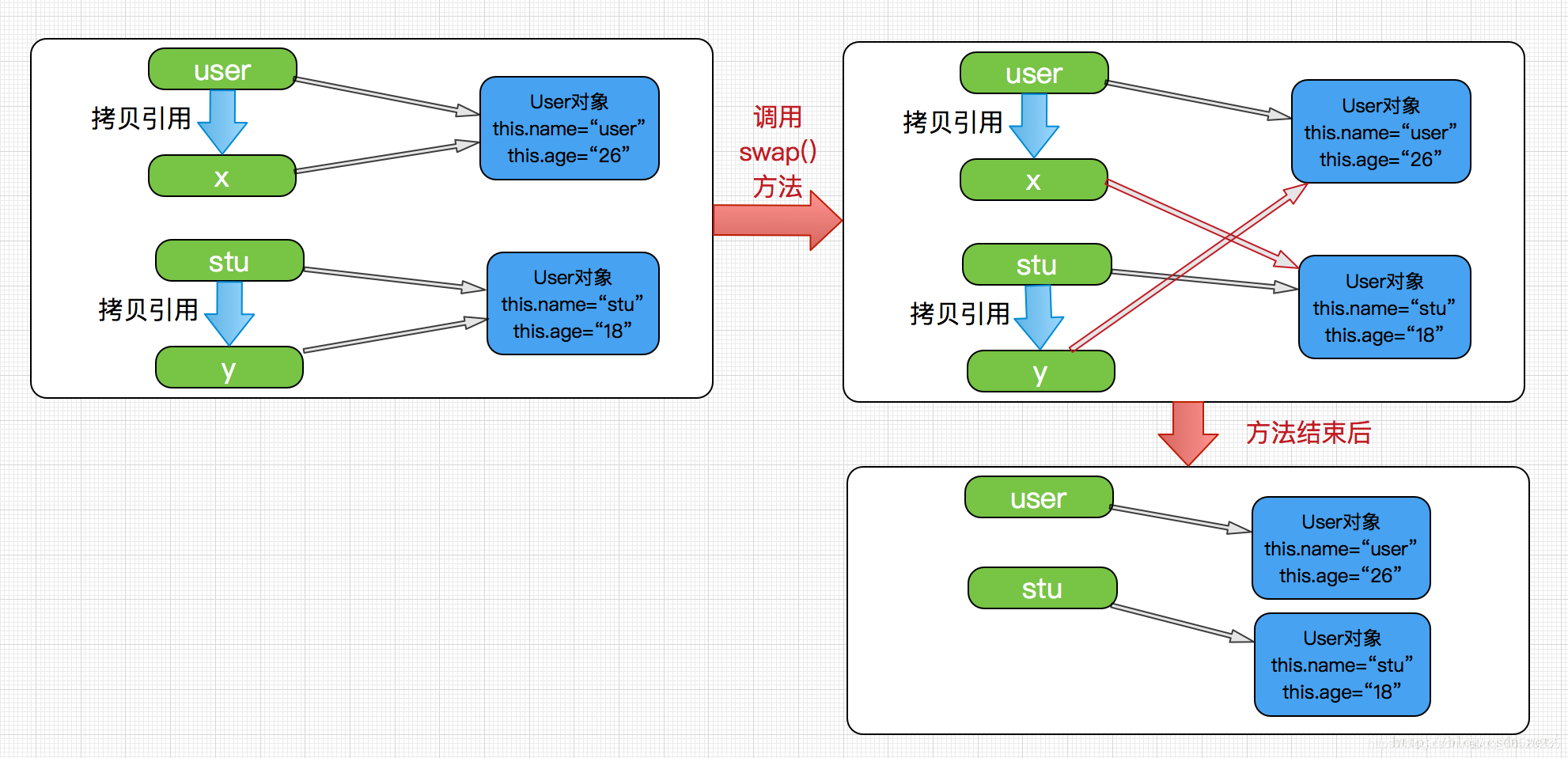
总结:
- 在传进来的参数是基本类型的时候,用的是值传递
- 如果传进来的参数类型是对象或者是数组类型的时候,也只是拷贝了引用的值罢了,之所以能修改引用数据是因为它们同时指向了一个对象,但这仍然是按值调用而不是引用调用
面试题2. Java的Object类中有哪些方法,各自的用途?
- clone()方法是用来进行拷贝一个对象的,他使用的是一种浅拷贝的方式。
- finalize() 方法是Object对象的protected修饰的方法,当虚拟机在进行回收一个对象之前的时候,会去调用该对象的finalize()方法,这个方法只能是被动的被调用,就算是我们主动去调用该方法去回收一个对象,也不会起到作用的,因为他是有虚拟机自己去决定的。
面试题3. 深拷贝和浅拷贝的区别,怎么实现深拷贝?
他们的区别就是:
- 当如果要拷贝一个A对象,而A对象中又有一个B对象,那么如果对A拷贝的时候,重新拷贝出来一个A1对象并且重新分配内存地址,但是对于A中的B对象,仅仅只是把A1中拷贝出来的B1对象的引用指向原来的B对象而已,并没有把拷贝的B1对象也重新进行分配一个新的内存地址。这就是浅拷贝。
- 而深拷贝就是在第1的基础上,不仅重新给A1对象分配了新的内存地址,而且还给A1中的B1也重新进行分配了新的内存地址,而不只是仅仅把原本的B的引用给B1。这就是深拷贝。
这里借用一张书中的图片:
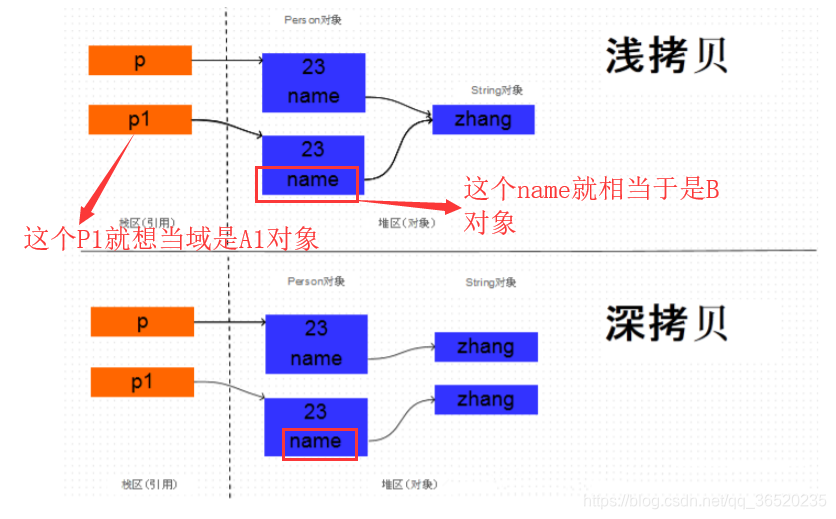
那么如果实现深拷贝呢?
- 如果想要深拷贝一个对象,这个对象必须要实现 Cloneable 接口,实现 重写clone()方法,并且在 clone 方法内部,把该对象引用的其他对象也要 clone 一份,这就要求这个被引用的对象必须也要实现
Cloneable 接口并且实现 clone 方法
面试题4. Final, finally, finalize的区别?
- final:他是用来进行修饰方法、类、以及属性变量的,如果修饰的是方法的话,表示方法不能够被覆盖,如果修饰的是类的话,就表示该类不能够被继承,如果修饰的是属性变量的话,就表示该属性变量不能够被修改。
- finally:他一般用来进行try 。。catch语句之后,主要是为了进行释放一些连接资源,无论怎么finally中的代码都会被执行。
- finalize:这个方法是Object对象的protected修饰的方法,当虚拟机在进行回收一个对象之前的时候,会去调用该对象的finalize()方法,这个方法只能是被动的被调用,就算是我们主动去调用该方法去回收一个对象,也不会起到作用的,因为他是有虚拟机自己去决定的。
面试题5. 讲一讲泛型,有没有在jdk源码层面研究过泛型
其实泛型的本质目的就是为了参数化类型,但是泛型的底层其实是经过了一个泛型擦除的过程,只在代码编译阶段才会起到作用,而在进入JVM之前,与泛型有关的信息就会被擦除,这个过程就叫做泛型擦除。
- 泛型不仅可以对一个对象进行使用泛型,还可以是接口、方法
- 那就说说泛型擦除吧,他其实在JVM中还是那个类,不会因为你加了泛型,就把泛型和加泛型的类、方法、接口绑定一起,但是在利用反射的时候,其实只能获取到原本的类、方法、接口,根本就没有泛型这一说(在进入JVM中之后),List l1 = new ArrayList() 和 List l2 = new ArrayList(),其实l1和l2通过泛型得到的字节码都是一样的没有什么区别。这里就使用了泛型擦除
- 但是泛型擦除也有例外的情况,比如说你在定义一个类的时候,你给这个类(定义的类)加了一个泛型上界public Class Teacher ,那么此时通过反射得到Teacher 这个定义类类型其实就是Teacher 类型,如果么没有加这个泛型上界的话,就还是Object类型。
面试题6. .说一说java的异常体系, java是如何处理异常的?
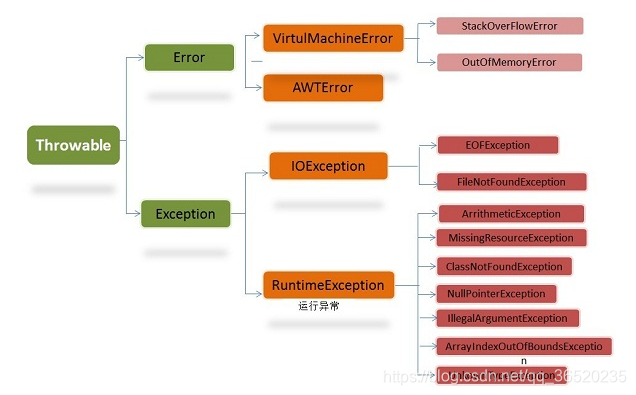
用上面一张图进行描述一下Java的异常体系的两大类:
- 第一种是我们开发人员会经常遇到的Throwable的子类Exception中的异常。并且这种异常一般是运行时异常和IO异常,表示程序还能够克服和恢复的问题,运行时异常就是我们开发中实际会经常遇到的一些,比如java.lang.NullPointerException、java.lang.ClassNotFoundException、java.lang.IndexOutOfBoundsException,这种异常可以使用try catch进行捕获异常就可以了,当然我们还可以提前用throws把有可能发生的异常给声明出来,或者在进行局部可能会出现的异常进行throw出去(这个只能单独抛出一种异常的实例)
- 第二种是由于虚拟机自身的一些错误导致的error异常,也是Throwable中子类的异常。这种异常表示应用程序本身无法克服和恢复的一种严重问题。,这种异常我们开发人员一般很难遇到。
面试题7. Public、private、protected
- public的访问权限:当前类,子类,当前类所在的包下,以及其他包下都可以进行访问。
- protected的访问权限:除了当前类所在的包下、以及子类都可以访问,其他的包下都不能进行访问。(可以用肥水不流外人田记忆,哈哈)
- 默认的话:只能当前类和当前类所在的包下可以访问,当前类的子类和其他包下都不能进行访问。
- private的访问权限:只有当前类可以访问(你可以理解成,加了private的话,这个人的钱就只能他自己知道他有多少钱,别人都不知道)
访问的权限依次是递减的。
面试题8. 成员变量、局部变量是否可以不初始化?
成员变量可以不用初始化:原因如下
- 原因是因为成员变量是属于实例对象的一部分,而且所有的实例对象都是分配在堆内存中,在虚拟机中分配好存储空间的时候,此时就会把实例对象的内存空间的成员变量都初始化为0,在类对象的加载过程中有五步,加载–>验证—>准备(static在这进行隐式初始化为0的)–>解析–>初始化,所以说成员变量就算你没有进行手动初始化也是有值的(为0或者为NULL)
局部变量必须进行初始化:原因如下
- 首先你得知道局部变量是位于方法中,而每一个方法在JVM执行过程中都是放在运行时数据区的栈贞中,而每一个栈贞中都存放着局部变量表、操作数栈、方法出口、动态链接等。因为局部变量表所需的内存空间是在编译期间就完成固定分配的,所以当调用方法前(也就是进入栈贞之前),就必须确定这个方法栈贞需要分配多大的变量空间,在方法运行期间就不会改变局部变量表的大小了,所以就说明了局部变量在创建时就必须进行初始化以确定分配内存大小。
面试题9. String,StringBuffer和StringBuilder的区别?
区别:
- 线程安全方面:String和StringBuilder都是线程不安全的,但是StringBuffer是线程安全的。
- String是字符串常量,而StringBuffer和StringBuilder都是字符串变量,说白了就是,当String字符串对象一旦创建成功,就不会改变,但是StringBuffer和StringBuilder是可以修改的
- 在执行效率上:或者说是执行速度,在这方面运行速度快慢为:StringBuilder > StringBuffer(他是synchronized进行修饰的) > String(因为每一次创建的String对象都是不可以变的)
面试题10. 接口和抽象类区别?,接口除了抽象方法还有什么方法?
不同之处:
抽象类:
- 抽象类中可以定义构造器
- 可以有抽象方法和具体方法
- 接口中的成员全都是 public 的
- 抽象类中可以定义成员变量
- 有抽象方法的类必须被声明为抽象类,而抽象类未必要有抽象方法
- 抽象类中可以包含静态方法
- 一个类只能继承一个抽象类
接口:
- 接口中不能定义构造器
- 方法全部默认都是抽象方法,接口中的变量默认也必须是public static final
- 抽象类中的成员可以是 private、默认、protected、public
- 接口中定义的成员变量实际上都是常量
- 接口中不能有静态方法
- 一个类可以实现多个接口
相同之处:
- 不能够实例化
- 可以将抽象类和接口类型作为引用类型
- 一个类如果继承了某个抽象类或者实现了某个接口都需要对其中的抽象方法全部进行实现,否则该类仍然需要
被声明为抽象类
面试题11. 什么 是内存泄漏和内存溢出,有什么解决办法?
内存泄漏:其实就是当我们在创建对象或者是变量之后,并且该对象或者变量在程序中都不再使用了,但是又没有办法回收这些没用的对象和变量。而且还一直占用着系统的内存空间,此时的现象就是内存泄漏。
解决办法:
- 我们在使用静态变量的时候尽量减少对静态变量的使用,因为静态变量是存储在方法区(也就是永久代),不会被回收
- 如果在程序中有不用的对象,应该及时进行释放。
内存溢出:其实就是当我要申请一块内存的时候,但是此时虚拟机不能够给我提供这么大的内存,就说明内存溢出了,比如出现OutOfMemoryError,StackOverflowError 这种错误信息的时候
解决办法:
- 修改 JVM 启动参数, 直接增加内存。 (-Xms, -Xmx 参数一定不要忘记加。一般要将-Xms 和-Xmx 选项设置为相同, 以避免在每次 GC 后调整堆的大小; 建议堆的最大值设置为可用内存的最大值的 80%)。
- 根据日志进行分析哪里的问题所在,进行排查。
面试题12. java中final 和static的区别?
先说一下static:分为静态方法、静态变量、静态块:所以静态代码块=静态变量>静态方法(因为静态方法是只有调用的时候才会去执行,否则不去执行)
如果一个类还没有被加载的时候:
- 会先去加载父类的静态变量和静态代码块(并且静态变量和静态代码块的加载顺序和他们在代码中出现的位置有关)
- 然后再去加载该类的静态代码块和静态变量的初始化
- 之后再去加载父类的实例变量的初始化
- 然后去执行父类的构造函数
- 再去加载该类的实例变量的初始化
- 然后去执行该类的构造函数
关于final的用法:
- 如果当final加在类上,那么这个类就不能再被继承
- 如果当final加在方法上,那么这个方法就不能被重写。
- 如果当final加在成员变量或者是局部变量上,那么这个变量的值就不能被修改。(补充:如果加在成员变量上,并且成员变量是一个对象,比如是一个Person对象,其实还是可以继续往Person对象中加一些其他的属性的,但是不能修改这个对象的引用而已,但是对象的内容还是可以改变的)
- final还可以加在方法的参数上,比如加在内部类的参数时就必须使用final关键字进行修饰(在JDK1.8之前都是必须的,但是在JDK1.8之后就可以不加了),因为内部类会持有外部类引用和方法中参数的引用,反编译class文件后,内部类的class文件的构造函数参数 中会显示传入 外部类对象(必然会加)以及方法内局部变量和形参(如果内部类有调用会加),不管是基本数据类型还是引用变量,如果重新赋值了,会导致内外指向的对象不一致,所以java就暴力的规定使用final,不能重新赋值。
面试题13. jdk动态代理,静态代理讲讲?
静态代理:
- 其实静态代理的最终目的就是为了扩展原本的对象方法的功能,通过代理对象类在去保证真实对象功能的前提下,再此基础上去扩展一些新的功能或者说是去增加一些繁琐且必须要去做的事情
- 但是如果当我们的业务接口过多的话,我们的代理对象也会变的很多,而且代理对象和真实对象都必须要实现同一个真正干活的业务接口。这也是他的缺点
jdk的动态代理:
- 而其实动态代理就是为了解决上一个静态代理的缺点,他可以不用代理对象和真是对象都去同时实现同一个业务接口。
- 而动态的代理的核心就是实现InvocationHandler 接口类重写invoke方法Object invoke(Object proxy, Method method, Object[] args) :在代理实例上处理方法调用并返回结果。 和public static Object newProxyInstance(ClassLoader loader, Class<?>[] interfaces,InvocationHandler h) 这两个核心方法。
- 还有一点核心的就是使用ava.lang.reflect.Proxy类,他提供用于创建动态代理类和实例的静态方法,它还是由这些方法创建的所有动态代理类的超类Object invoke(Object proxy, Method method, Object[] args)。Ojbect proxy:表示需要代理的对象,Method method:表示要操作的方法, Object[] args:method方法所需要传入的参数(可能没有为,null.也可能有多个)
代理对象的核心实现:
class ServiceProxy implements InvocationHandler {
private Object target=null;//保存真实业务对象
/**
* 返回动态代理类的对象,这样用户才可以利用代理类对象去操作真实对象
* @param obj 包含有真实业务实现的对象
* @return 返回代理对象
*/
public Object getProxy(Object obj) {
this.target=obj;//保存真实业务对象
return Proxy.newProxyInstance(obj.getClass().getClassLoader(), obj
.getClass().getInterfaces(), this);
}
@Override
public Object invoke(Object proxy, Method method, Object[] args)
throws Throwable {
Object result=method.invoke(target, args);//通过反射调用真实业务对象的业务方法,并且返回
return result;
}
}
这是如何使用这个动态代理对象
public static void main(String[] args) {
UserService service=(UserService) new ServiceProxy().getProxy(new UserServiceImpl());
service.saveUser();
}
面试题14. 什么是序列化和反序列化?序列化的底层怎么实现的?
什么是序列化和反序列化?
- Java序列化是指把Java对象保存为二进制字节码的过程,Java反序列化是指把二进制码重新转换成Java对象的过程
序列化的底层怎么实现的?
- 其实就是利用了java的IO流来进行实现的,
public static void main(String args[]) throws IOException {
FileOutputStream fos = new FileOutputStream("D:/demo.text");
ObjectOutputStream oos = new ObjectOutputStream(fos);
//这个是一个需要序列化的实体对象
User user = new User();
//这是为了把实体对象写到输出流中,然后保存到D盘的一个路径下
oos.writeObject(user);
oos.flush();
oos.close();
}
面试题15. switch中可以用String吗?
- 在Java5以前,switch(expr)中,exper只能是byte,short,char,int类型(或其包装类)的常量表达式。
- 从Java5开始,java中引入了枚举类型,即enum类型。
- 从Java7开始,exper还可以是String类型。
- 但是long在所有版本中都是不可以的。
- jdk1.7并没有新的指令来处理switch
string,而是通过调用switch中string.hashCode,将string转换为int从而进行判断。hashcode返回的是int型
面试题16. 说一下java中的变量类型的占用字节数?
- int 占用的字节是4个字节 、byte 占用1个字节、short 占用2个字节、long占用8个字节
- char 占用2个字节(可以储存一个汉字,一个汉字占用3个字节在UTF-8中,在GBK中一个汉字占用2个字节)
- double 占用8个字节,float占用4个字节
- Boolean占用1个字节
MySQL中的都有哪些字节类型,都占用多少个字节?
数字类型的:
- tinyint ,占用1个字节,他的数的范围是(-127~128)
- smallint,占用2个字节,他的可存储的范围是在(-32768~32767)
- int ,占用4个字节,这里其实是和java中的数据类型互通的
- bigint,占用8个字节,范围更大
- float,占用4个字节
- double,占用8个字节
字符串类型的:
- char,自己进行定义多少个字节就是多少个字节,如果没有用到那么多字节的话,后面会用空格进行补充
- varchar,这个也是可以自己定义的,但是他总是比自己定义的字节+1,因为他是可变的字符串,而且如果你的实际长度没有达到你自己定义的长度的话,用的时候还是会使用实际用到的长度
- tinytext,他也是跟varchar有点相似
- text,blog,这两个都是可以存储大量的文本的字符的类型
时间类型的:
- Date,这个是占用3个字节,并且只能精确到天,它支持的时间范围为’1000-01-01’到’9999-12-31’
- DateTime,这个占用8个字节,他可以支持到具体的秒级别的,它支持的范围为’1000-01-01 00:00:00’到’9999-12-31 23:59:59’
- TimeStamp,这个占用4个字节,他也是可以支持到具体的秒级别的,但是他支持的范围相比于datetime的话会少很多,它支持1970-01-01 00:00:00 到 2037年之间。(这个有分时区问题)
- Time,这个占用3个字节
面试题17. 说一下重载和重写的区别?(然后会接着问重载和重写是在怎么实现的?)
- 首先重载是发生在同一个类中的,他的参数个数、参数顺序、参数类型都可以不同,但是重载的方法名必须相同
- 重写的话,一般发生在父子类中,方法名、参数类型、参数列表都必须相同。典型的例子就是定义一个接口,我们去实现一个接口其实就是一种典型的重写。
面试题18. 说一下Java8中的Lambda个其他的新特性?
面试题19. 知道java8中的接口有个默认方法和静态方法是什么?干什么用的吗?为什么要有默认方法?
- 首先接口中有个默认方法是为了满足一种场景,如果当我们一个现有的业务接口中需要增加一个新的功能的时候,(在JDK1.8之前)我们需要重新定义一个接口,然后分别在不同的实现类中进行实现,如果不实现的话,就会报编译错误,要是实现类很多的话,就会变的跟糟糕。
所以在java8中添加一个默认的方法就是为了解决这种场景的,如果你想增加一个新的工能的话,只需要在接口中定义一个默认的default 来进行修饰的方法,并且可以在方法中可以写你自己增加的个功能,而且你的子类还不需要去挨个实现该功能接口,这样就完美的解决了。
补充一点:
- 静态方法,只能通过接口名调用,不可以通过实现类的类名或者实现类的对象调用。default方法,只能通过接口实现类的对象来调用。