第二篇学习笔记的链接为:https://blog.csdn.net/Nyte2018/article/details/88761489
这一篇是接上次关于第二章的学习
1、标签处理
先来看下面代码1:
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://www.pythonscraping.com/pages/page3.html")
bsObj = BeautifulSoup(html,"html.parser")
for sibling in bsObj.find("table",{"id":"giftList"}).tr.next_siblings:
print(sibling)
这段代码会打印产品列表里的所有行的产品,第一行表格标题除外。BeautifulSoup 的 next_siblings() 函数,只调用后面的兄弟标签。例如,如果我们选择一组标签中位于中间位置的一个标签,然后用 next_siblings() 函数,那么它就只会返回在它后面的兄弟标签。因此,选择标签行然后调next_siblings,可以选择表格中除了标题行以外的所有行。和 next_siblings 一样,如果你很容易找到一组兄弟标签中的最后一个标签,那么previous_siblings 函数也会很有用。当然,还有 next_sibling 和 previous_sibling 函数,与 next_siblings 和 previous_siblings的作用类似,只是它们返回的是单个标签,而不是一组标签。
父标签处理-代码2:
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://www.pythonscraping.com/pages/page3.html")
bsObj = BeautifulSoup(html,"html.parser")
print(bsObj.find("img",{"src":"../img/gifts/img1.jpg" }).parent.previous_sibling.get_text())
输出结果为:$15.00。即…/img/gifts/img1.jpg 这个图片对应商品的价格。
实现过程:

(1) 选择图片标签 src="…/img/gifts/img1.jpg";
(2) 选择图片标签的父标签(在示例中是 标签);
(3) 选择 标签的前一个兄弟标签 previous_sibling(在示例中是包含美元价格的 标签);
(4) 选择标签中的文字,“$15.00”。
2、正则表达式
正则表达式常用符号表:

识别邮箱地址的正则表达式:

把上面的规则连接起来,就获得了完整的正则表达式:
[A-Za-z0-9._+]+@[A-Za-z]+.(com|org|edu|net)
BeautifulSoup 和正则表达式配合使用抓取所有图片的 URL 链接代码3:
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
html = urlopen("http://www.pythonscraping.com/pages/page3.html")
bsObj = BeautifulSoup(html,"html.parser")
images = bsObj.findAll("img",{"src":re.compile("\.\.\/img\/gifts/img.*\.jpg")})
for image in images:
print(image["src"])
输出结果为:
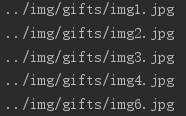
这段代码打印的式图片的相对路径,都是以 …/img/gifts/img 开头,以 .jpg 结尾。正则表达式可以作为 BeautifulSoup 语句的任意一个参数,让你的目标元素查找工作极具灵活性。
3、获取属性
对于一个标签对象,可以用下面的代码获取它的全部属性:myTag.attrs。
要注意这行代码返回的是一个 Python 字典对象,可以获取和操作这些属性。比如要获取图片的资源位置 src,可以用:myImgTag.attrs[“src”]
4、Lambda表达式
Lambda 表达式本质上就是一个函数,可以作为其他函数的变量使用;也就是说,一个函数不是定义成 f(x, y),而是定义成 f(g(x), y),或 f(g(x), h(x)) 的形式。
BeautifulSoup 允许我们把特定函数类型当作 findAll 函数的参数。唯一的限制条件是这些函数必须把一个标签作为参数且返回结果是布尔类型。BeautifulSoup 用这个函数来评估它遇到的每个标签对象,最后把评估结果为“真”的标签保留,把其他标签剔除。
例如,下面的代码就是获取有两个属性的标签:
soup.findAll(lambda tag: len(tag.attrs) == 2)
这行代码会找出下面的标签:
<div class="body" id="content"></div>
<span style="color:red" class="title"></span>