最近在搭建个人网站时,突然想写个爬虫玩玩,作为一名前端小白,自然就想到了用nodejs来实现爬虫。参考学习了许多文章教程后终于有点成果了,这里以虎扑爆照区为例,爬了许多小姐姐照片~
准备:
首先在node项目里安装爬虫需要的依赖:
//package.json的依赖里添加这三个
"dependencies": {
"cheerio": "^1.0.0-rc.2",
"superagent": "^4.1.0",
...
},
//在终端
npm install
这里引入了几个模块:
客户端请求代理模块SuperAgent
类似于jQuery的cheerio
还需要分析一下页面结构: 爆照区是以’https://bbs.hupu.com/selfie-’ + 页数 的形式呈现,
每个class为titlelink的div的下一个节点就是帖子的入口,依次分析完后可以得出
标题:bbs-hd-h1>h1
用户id:j_u
图片:quote-content>p>img
好了,准备了这些就可以开工了
爬虫文件 crawler.js
let start =function() {
//我用的是mongo数据库存储数据
let mongoose = require('mongoose')
let mongourl = "mongodb://localhost:27017/dbname"
mongoose.connect(mongourl) //连接数据库
let Schema = mongoose.Schema
//骨架模版
let sssSchema = new Schema({
pics: String,
href: String
})
//model模型
let SSS = mongoose.model('SSS', sssSchema)
const superagent = require('superagent')
const cheerio = require('cheerio')
const fs = require('fs')
const url = require('url')
let allUrl = [] //用于存放所有url
for (let i = 1; i <= 5; i++) {
let hupuUrl = 'https://bbs.hupu.com/selfie-' + i
//示例 把5页的页面循环打出来
superagent.get(hupuUrl)
//通过superagent的get请求去请求每一页
.end(function (err, res) {
if (err) {
return console.log(err)
}
let $ = cheerio.load(res.text);
//对所有帖子入口进行遍历
$('.titlelink > a:first-child').each(function (idx, element) {
let $element = $(element);
let href = url.resolve(hupuUrl, $element.attr('href'));
allUrl.push(href);
//获取到此url,异步进行以下操作,此操作为进入到这个帖子中爬取数据
superagent.get(href)
.end(function (err, res) {
if (err) {
return console.log(err);
}
let $ = cheerio.load(res.text);
let add = href;
let title = $('.bbs-hd-h1 > h1').attr('data-title'); //帖子标题
let name = $('.j_u:first-child').attr('uname'); //用户ID
let contentImg = [] //存放一张帖子里的图片数组
let t = 1;
while ($(`.quote-content>p:nth-child(${t})>img`).attr('src')) {
//当有图片时
contentImg.push($(`.quote-content>p:nth-child(${t++})>img`).attr('src'))
}
if (t != 1) {
//如果没有图就不要了
//第一种存储方式,把数据存储到数据库,这里只要链接和图片,贴子标题啥的我不关心~
let sss = new SSS({
href: add,
pics: contentImg,
title: title,
name : name
})
sss.save(function (err) {
if (err) {
console.log('保存失败')
return;
}
console.log("ok")
})
}
})
});
});
}
console.log("搞完了")
}
module.exports = start
代码不难,通读一遍之后应该就明白了,数据库的话看个人喜欢了
后台接口
这里服务端用的是koa,比较复杂,就不贴出来了不然太多了。前端通过发送ajax请求给后台接口,返回的到一个results
module.exports = {
getsss: async (ctx, next) => {
//引入刚刚的爬虫文件
let crawler = require('./crawler.js')
await crawler() //等待异步操作
let mongoose = require('mongoose')
const db = mongoose.connect("mongodb://localhost/daname")
// 数据库 模型
let sss = new mongoose.Schema({
href: String,
pics: String,
name: String,
title: String
});
let sssModel = mongoose.model('ssses', sss)
// 查询得到的是json文档
const results = await sssModel.find({})
ctx.result = {
code: 0,
msg: "sss",
results: results
}
return next()
}
}
前端展示
前端我用的是vue,用图片+分页跳转的模式观赏
这里有一个坑:在动态获取src图片时会出现403(虎扑做的安全措施).查阅资料后发现需要修改请求头,具体的大家可以看看http协议哈。
1.在img里加上 referrer="no-referrer|origin|unsafe-url
2.把链接改为 https://images.weserv.nl/?url= …的格式
扫描二维码关注公众号,回复:
5649261 查看本文章

<template>
<div style="display:flex; justify-content: center; align-items: center; flex-direction: row;">
<el-button type="success" v-if="results.length === 0" @click="start_crawler">开始爬取</el-button>
<div v-else>
<img :src = "result.src" style="width:500px;" referrer="no-referrer|origin|unsafe-url"/>
<div>
<span style="display: block;">切换小姐姐照片~</span>
<el-input-number v-model="page" @change="handleChange" :min="1" :max="results.length" label="切换小姐姐照片~" style="display: block; "></el-input-number>
<span style="display: block;">共{{results.length}}张</span>
</div>
</div>
</div>
</template>
<script>
export default {
name: "crawler",
data() {
return {
page: 0,
results: [],
result: {
src: {},
}
};
},
methods:{
format(pics){
//简单的洗一下数据,去掉没用的链接,使链接跳转的是一个图片
let pic = pics.split("?x-oss-process=image/resize,w_800/format,webp")
let res = []
for(let i = 0 ; i < pic.length; i++){
res = pic[i].split(",")
res.forEach((item)=>{
if(item.length > 1 && item != "https://b1.hoopchina.com.cn/web/sns/bbs/images/placeholder.png"){
this.results.push(item)
}
})
}
this.result = {
src: this.results[0].replace("https://","https://images.weserv.nl/?url=")
}
},
handleChange(){
this.result = {
src: this.results[this.page - 1].replace("https://","https://images.weserv.nl/?url=")
}
},
start_crawler(){
//从本地mongo数据库提取文件
let data = {
msg: '我要小姐姐!'
}
this.$api.getsss(data).then((res) =>{
res.data.results.forEach((item) => {
this.format(item.pics) //洗数据
});
console.log(this.results)
})
}
}
}
</script>
最终效果如图
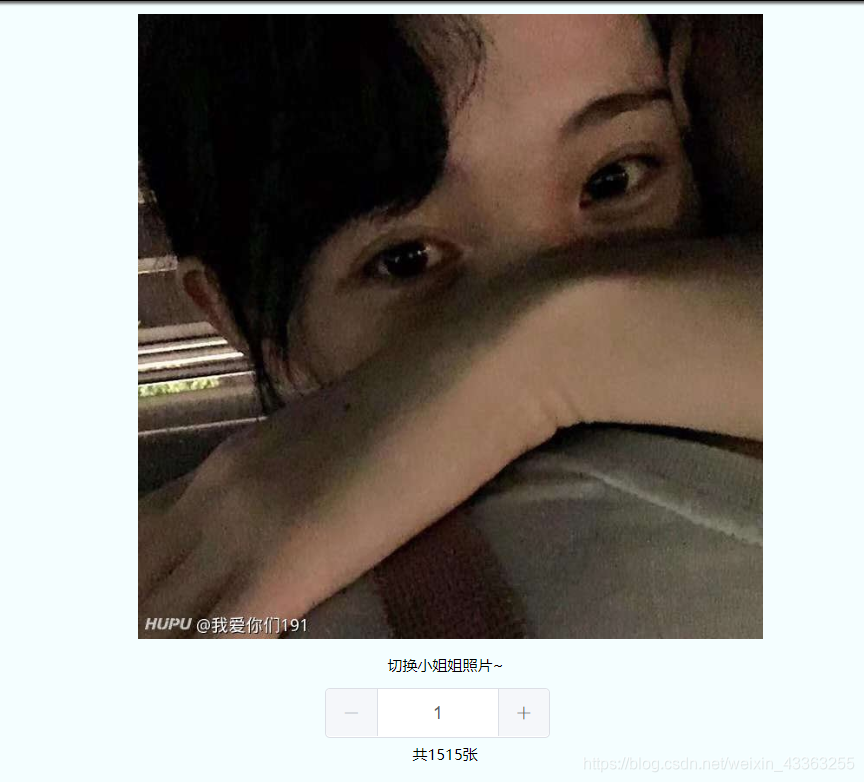 大功告成!
大功告成!
ps:
本文主要是记录写一个node爬虫的过程,所以只贴出了部分相关代码
相对于python爬虫来说,node的优势在于简单的爬取数据,解析网页能力,处理数据返回。适合前端个人项目。