版权声明:老哥,这些都是我手打的,给点面子 https://blog.csdn.net/weixin_43312108/article/details/88779030
在此之前,我们首先要了解一下几个常用的命令和区别
-
having与where
区别在于执行时机不同,where是在检索开始时从数据源中获取,having是从分组后的数据结果中获取。
所以,重点在于having所筛选的数据一定是在where删选之后!
这个having说白了就是为了配合统计函数使用的 -
exist的总结
这个子查询的目的不在于为了产生结果集,只是用来判断某个子查询是否查询到了数据,返回的是一个布尔值。 -
count()统计函数
count()求某个组内非NULL记录的值,而count(*)可以求出某个组内含null记录的值。
下面建表试验一下。
CREATE TABLE `table1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL DEFAULT '',
`Gender` tinyint(4) NOT NULL COMMENT '0为男,1为女',
`score` int(11) NOT NULL,
`class` int(11) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8;
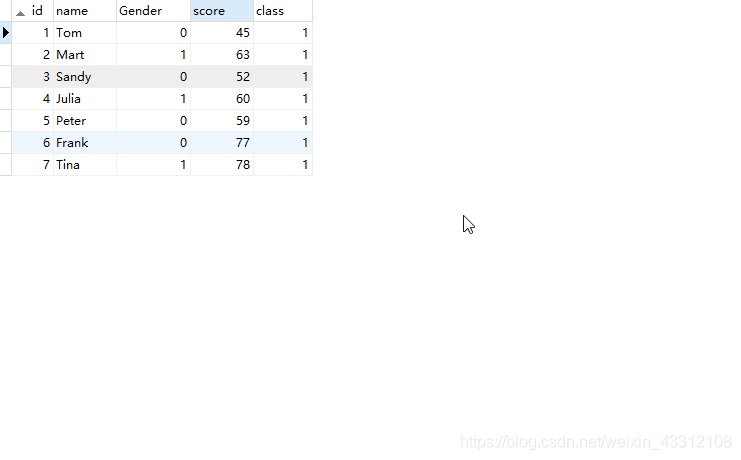
目的求出这个班中男女生中的前两名。
SELECT *FROM table1 a
where EXISTS (SELECT COUNT(*) FROM table1 b WHERE b.score>=a.score
GROUP BY b.gender HAVING COUNT(*)<=2 ) ORDER BY Gender,score DESC
得出结果是这样的
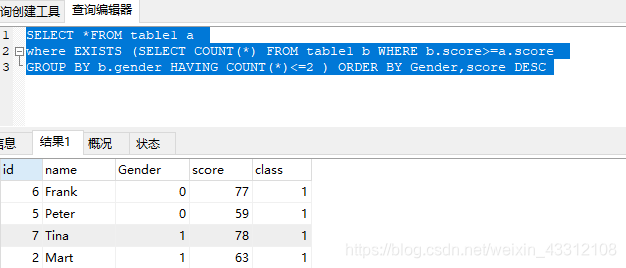
分析一下这个结构,在where exists 后的子查询的意思是,按性别分组之后,这个表中比这个学生分数还高的人数少于两个的查出来,之所以能够显示分组之后的人数,私以为这就是形成一个循环,只要满足条件,就接着输出。类似这种条件均可以如此解决。这里面有个大坑,回头问问大神看看是什么情况。