软院编号:372
原创作品转载请注明出处 + https://github.com/mengning/linuxkernel/
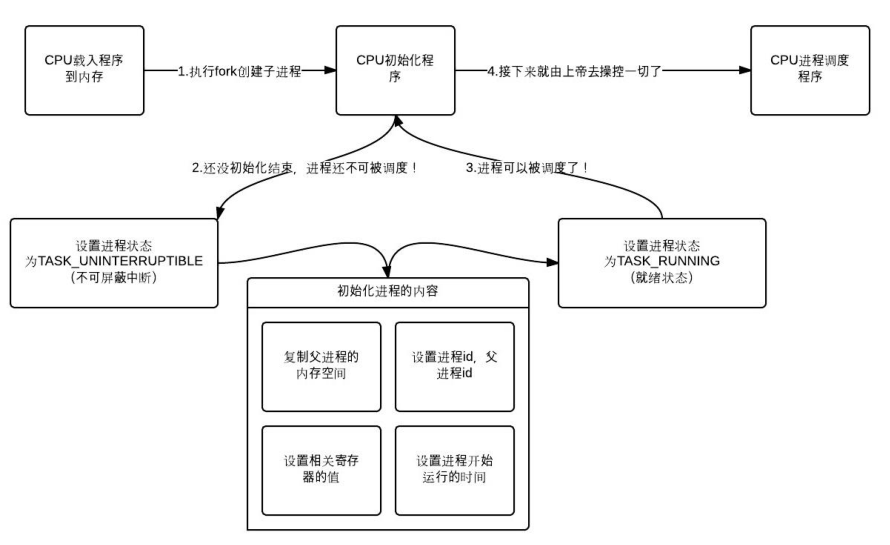
进程创建
进程和程序
程序是包含可执行代码以及执行代码需要的数据等信息的文件,存放在磁盘等介质上。
当程序被操作系统装载到内存并分配给它一定资源后,此时可称为进程。
程序是静态概念,进程是动态概念。
进程的创建简述
进程创建到可运行的过程大致分为以下3步:
- 程序载入内存后由CPU对程序进程初始化(fork);
- 初始化过程中对进程PCB进行设置(PCB中存放进程ID、进程状态、调度信息等);
- 设置后将进程放入就绪队列等待调度;
task_struct分析(部分)
task_struck太长,截取分析部分
struct task_struct{
pid_t pid; //进程id
uid_t uid,euid;
gid_t gid,egid;
volatile long state; //进程状态,0 running(运行/就绪);1/2 均等待态,分别响应/不响应异步信号;4 僵尸态,Linux特有,为生命周期已终止,但PCB未释放;8 暂停态,可被恢复
int exit_state; //退出的状态
unsigned int rt_priority; //调度优先级
unsigned int policy; //调度策略
struct list_head tasks;
struct task_struct *real_parent;
struct task_struct *parent;
struct list_head children,sibling;
struct fs_struct *fs; //进程与文件系统管理,进程工作的目录与根目录
struct files_struct *files; //进程对所有打开文件的组织,存储指向文件的句柄们
struct mm_struct *mm; //内存管理组织,存储了进程在用户空间不同的地址空间,可能存的数据,可能代码段
struct signal_struct *signal; //进程间通信机制--信号
struct sighand_struct *sighand; //指向进程
cputime_t utime, stime; //进程在用户态、内核态下所经历的节拍数
struct timespec start_time; //进程创建时间
struct timespec real_start_time; //包括睡眠时间的创建时间
}PCB结构如下图:

我的理解是,PCB中存了进程的pid、进程状态、调度策略、内存空间、文件系统、信号量、运行时间等诸多关键信息,进程的执行需要配合PCB。比如通过PCB的 mm可以查看进程在内存中的空间,里面有可能存的是数据段,也有可能是代码段;可以通过 files里的句柄,对被进程打开的文件进行读写。
PS:Linux系统中,所有的进程共有的祖先进程是init进程(pid=1),init进程创建其他的进程,其他进程继而进一步创建其子进程,最终实现一个进程树。
fork函数理解
头文件:unistd.h
函数 pid_t fork(void);
fork函数被正确调用后,在子进程和父进程中各返回一次
在子进程中返回0
在父进程中返回子进程pid
出错返回-1
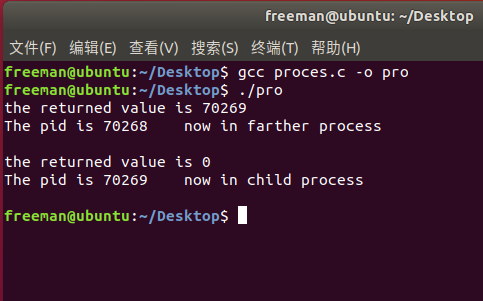
编写proces.c查看fork()运行结果
#include <stdio.h>
#include <unistd.h>
int main(int argc, char **argv){
pit_t pid;
pid=fork();
if(pid==-1)
printf("fork error\n");
else if(pid==0){
printf("the returned value is %d\n",pid);
printf("The pid is %d,now in child process\n",getpid());
}
else{
printf("the returned value is %d\n",pid);
printf("The pid is %d,now in farther process\n",getpid());
}
return 0;
}根据返回的pid来确定在哪个进程中执行;
pid==0,子进程中运行;
pid==正常值,父进程中运行。
子进程是父进程的副本
- 子进程复制/拷贝父进程的PCB、数据空间(数据段、堆和栈)
- 父子进程共享正文段(只读)
- 父子进程执行完fork以后会继续执行fork后的代码
PS:vfork用于创建新进程,该新进程的目的是执行另外一个可执行文件。vfork并不将父进程的地址空间完全复制到子进程中。
使用gdb跟踪fork系统调用理解do_forkhanshu
我使用的内核是Linux-5.0.1,下载"https://github.com/mengning/menu.git",修改其配置文件后make
- git clone https://github.com/mengning/menu.git
- cd menu //修改Makefile里 "qemu -kernel"后的内容为 “qemu -kernel ../linux-5.0.1/arch/x86/boot/bzImage -initrd ../rootfs.img” 按自己目录更改
- mv test_fork.c test.c
- make rootfs //即可启动qemu
后续参照上次实验进行qemu内的gdb
在qemu中gdb
打断点:
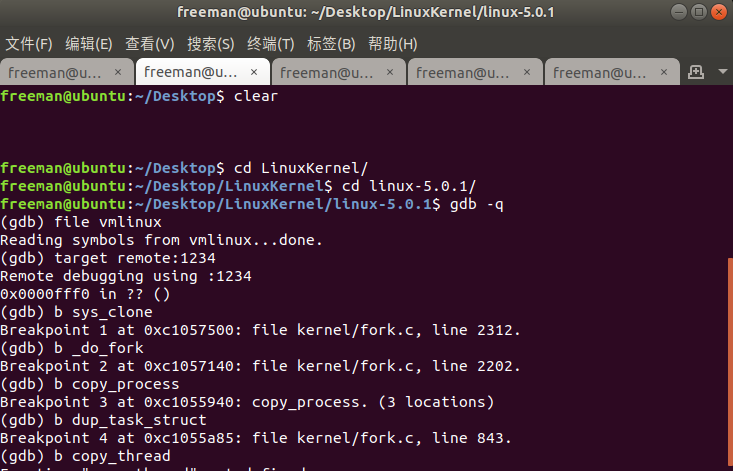
观察执行:

在do_fork函数中,以ret_from_fork函数为执行起点,复制父进程的内存堆栈和数据,并修改某些参数实现子进程的定义和初始化,创建子进程的工作完成后,通过sys_call exit函数退出并pop父进程的内存堆栈,实现新进程的创建工作。
理解编译链接的过程和ELF可执行文件格式
从源文件Hello.c编译链接成Hello.out,需要经历如下步骤:

编译
编译是指编译器读取源程序(字符流),对之进行词法和语法的分析,将高级语言指令转换为功能等效的汇编代码。
源文件的编译过程包含两个主要阶段:
第一个阶段是预处理阶段,在正式的编译阶段之前进行。预处理阶段将根据已放置在文件中的预处理指令来修改源文件的内容。
第二个阶段编译、优化阶段,编译程序所要作得工作就是通过词法分析和语法分析,在确认所有的指令都符合语法规则之后,将其翻译成等价的中间代码表示或汇编代码。
汇编
汇编实际上指汇编器(as)把汇编语言代码翻译成目标机器指令的过程。目标文件中所存放的也就是与源程序等效的目标的机器语言代码。目标文件由段组成。通常一个目标文件中至少有两个段:
代码段:该段中所包含的主要是程序的指令。该段一般是可读和可执行的,但一般却不可写。
数据段:主要存放程序中要用到的各种全局变量或静态的数据。一般数据段都是可读,可写,可执行的。
目标文件(Executable and Linkable Format)
可重定位(Relocatable)文件:由编译器和汇编器生成,可以与其他可重定位目标文件合并创建一个可执行或共享的目标文件;
共享(Shared)目标文件:一类特殊的可重定位目标文件,可以在链接(静态共享库)时加入目标文件或加载时或运行时(动态共享库)被动态的加载到内存并执行;
可执行(Executable)文件:由链接器生成,可以直接通过加载器加载到内存中充当进程执行的文件。
静态链接(编译时)
链接器将函数的代码从其所在地(目标文件或静态链接库中)拷贝到最终的可执行程序中。这样该程序在被执行时这些代码将被装入到该进程的虚拟地址空间中。静态链接库实际上是一个目标文件的集合,其中的每个文件含有库中的一个或者一组相关函数的代码。
为创建可执行文件,链接器必须要完成的主要任务:
符号解析:把目标文件中符号的定义和引用联系起来;
重定位:把符号定义和内存地址对应起来,然后修改所有对符号的引用。
动态链接(加载、运行时)
在此种方式下,函数的定义在动态链接库或共享对象的目标文件中。在编译的链接阶段,动态链接库只提供符号表和其他少量信息用于保证所有符号引用都有定义,保证编译顺利通过。动态链接器(ld-linux.so)链接程序在运行过程中根据记录的共享对象的符号定义来动态加载共享库,然后完成重定位。在此可执行文件被执行时,动态链接库的全部内容将被映射到运行时相应进程的虚地址空间。动态链接程序将根据可执行程序中记录的信息找到相应的函数代码。
加载
加载器把可执行文件从外存加载到内存并进行执行。
进程执行
启动(main函数举例)
内核启动C程序时,会有特殊的启动函数(exec)获取从shell或者父进程来的参数,获取程序入口地址(main函数地址),将这些信息填写到PCB中
使用execve库函数加载一个可执行文件()
exec系列函数作用是在进程中加载执行另一个可执行文件,exec 系列函数替换了当前进程(执行该函数的进程)的正文段、数据段、堆和栈(来源于加载的可执行文件)。执行exec 系列函数后从加载可执行文件的main 函数开始重新执行。
execl execle execlp execv execve execvp 六个函数开头均为exec ,所以称为exec 系列函数
PS:exec 系列函数并不创建新进程,所以在调用exec 系列函数后其进程ID 并未改变,已经打开的文件描述符不变。
exec参数如下:
- l:表示list,每个命令行参数都说明为一个单独的参数
- v:表示vector,命令行参数放在数组中
- e:表示由函数调用者提供环境变量表
- p:表示通过环境变量PATH来指定路径,查找可执行文件
本次使用execl执行ls命令做跟踪,
函数原型
头文件:unistd.h
int execl(const char pathname,const char arg0, ...,NULL);
参数: - pathname:要执行程序的绝对路径名
- 可变参数:要执行程序的命令行参数,以空指针结束
返回值 - 出错返回-1
- 成功该函数不返回!
execl.c代码如下
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int main(void)
{
printf("entering main process---\n");
if(fork()==0){
execl("/bin/ls","ls","-l",NULL);
printf("exiting main process ----\n");}
return 0;
}调用execl()库函数执行“ls -l” 命令,执行结果如预期,截图如下:

调用一次execve的过程如下图所示:

总结
子进程是父进程的副本,子进程复制/拷贝父进程的PCB、数据空间(数据段、堆和栈),父子进程共享正文段(只读)
子进程和父进程继续执行fork 函数调用之后的代码,为了提高效率,fork 后不并立即复制父进程数据段、( 堆和栈,采用了写时复制机制(Copy-On-Write) )
当父子进程任意之一要修改数据段、堆、栈时,进行复制操作,并且仅复制修改区域。